 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Set Semantic Tagging: End-to-End Multi-label Prediction using Neural Attention for Complex Query Reformulation and Automated Text Categorization
Nov 11, 2019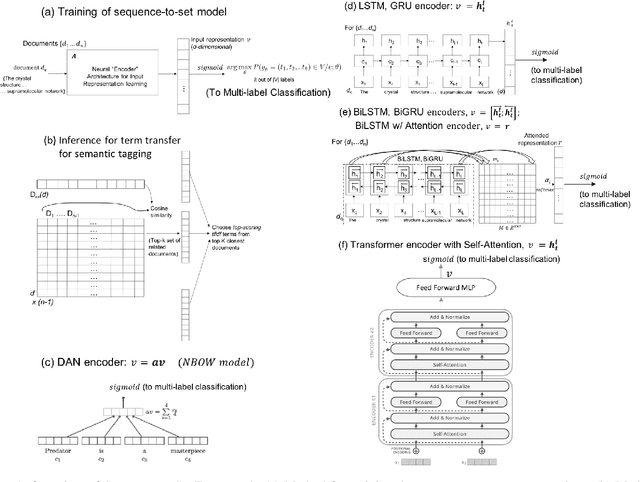

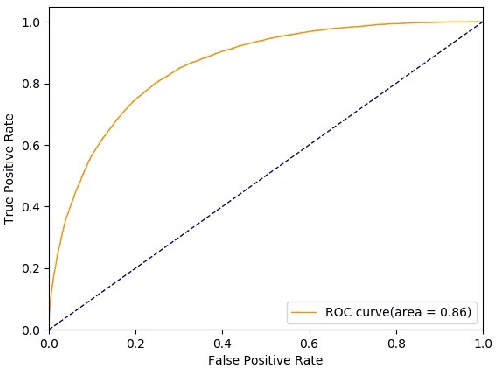
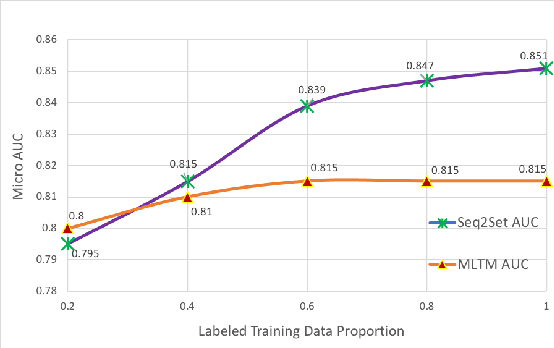
Novel contexts may often arise in complex querying scenarios such as in evidence-based medicine (EBM) involving biomedical literature, that may not explicitly refer to entities or canonical concept forms occurring in any fact- or rule-based knowledge source such as an ontology like the UMLS. Moreover, hidden associations between candidate concepts meaningful in the current context, may not exist within a single document, but within the collection, via alternate lexical forms. Therefore, inspired by the recent success of sequence-to-sequence neural models in delivering the state-of-the-art in a wide range of NLP tasks, we develop a novel sequence-to-set framework with neural attention for learning document representations that can effect term transfer within the corpus, for semantically tagging a large collection of documents. We demonstrate that our proposed method can be effective in both a supervised multi-label classification setup for text categorization, as well as in a unique unsupervised setting with no human-annotated document labels that uses no external knowledge resources and only corpus-derived term statistics to drive the training. Further, we show that semi-supervised training using our architecture on large amounts of unlabeled data can augment performance on the text categorization task when limited labeled data is available. Our approach to generate document encodings employing our sequence-to-set models for inference of semantic tags, gives to the best of our knowledge, the state-of-the-art for both, the unsupervised query expansion task for the TREC CDS 2016 challenge dataset when evaluated on an Okapi BM25--based document retrieval system; and also over the MLTM baseline (Soleimani et al, 2016), for both supervised and semi-supervised multi-label prediction tasks on the del.icio.us and Ohsumed datasets. We will make our code and data publicly available.