 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Internet of Things Data to Business Processes: Challenges and a Framework
May 14, 2024



The IoT and Business Process Management (BPM) communities co-exist in many shared application domains, such as manufacturing and healthcare. The IoT community has a strong focus on hardware, connectivity and data; the BPM community focuses mainly on finding, controlling, and enhancing the structured interactions among the IoT devices in processes. While the field of Process Mining deals with the extraction of process models and process analytics from process event logs, the data produced by IoT sensors often is at a lower granularity than these process-level events. The fundamental questions about extracting and abstracting process-related data from streams of IoT sensor values are: (1) Which sensor values can be clustered together as part of process events?, (2) Which sensor values signify the start and end of such events?, (3) Which sensor values are related but not essential? This work proposes a framework to semi-automatically perform a set of structured steps to convert low-level IoT sensor data into higher-level process events that are suitable for process mining. The framework is meant to provide a generic sequence of abstract steps to guide the event extraction, abstraction, and correlation, with variation points for plugging in specific analysis techniques and algorithms for each step. To assess the completeness of the framework, we present a set of challenges, how they can be tackled through the framework, and an example on how to instantiate the framework in a real-world demonstration from the field of smart manufacturing. Based on this framework, future research can be conducted in a structured manner through refining and improving individual steps.
XAI in the context of Predictive Process Monitoring: Too much to Reveal
Feb 16, 2022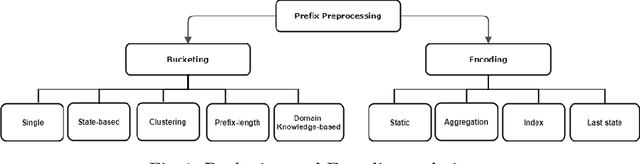
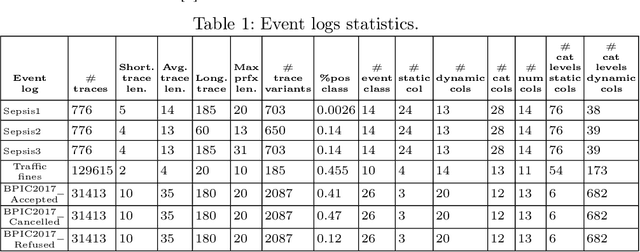
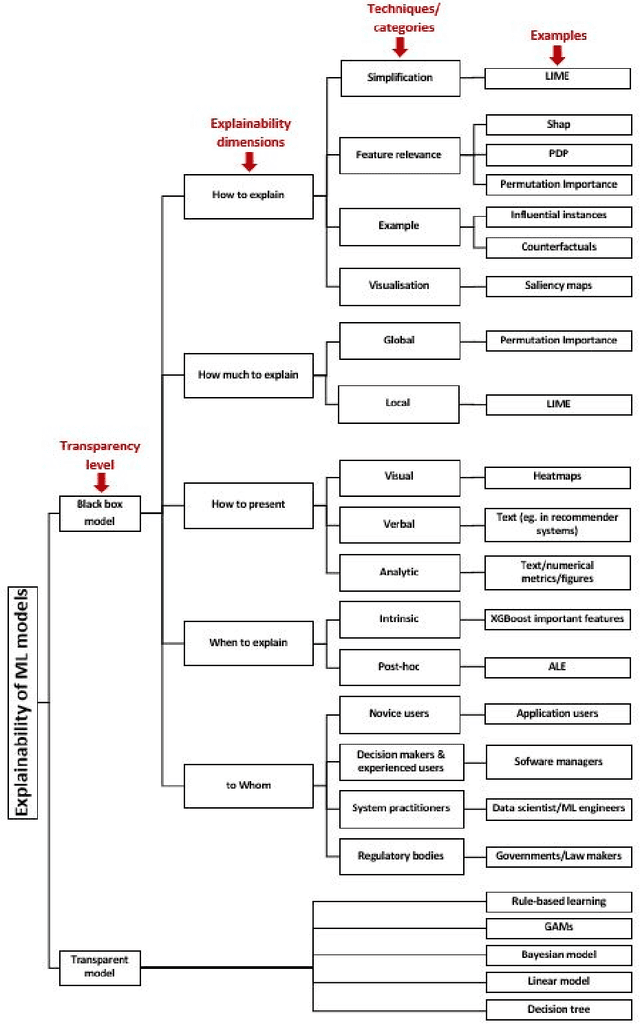
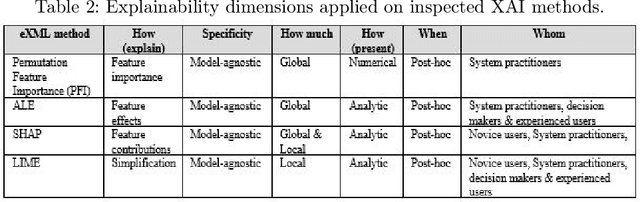
Predictive Process Monitoring (PPM) has been integrated into process mining tools as a value-adding task. PPM provides useful predictions on the further execution of the running business processes. To this end, machine learning-based techniques are widely employed in the context of PPM. In order to gain stakeholders trust and advocacy of PPM predictions, eXplainable Artificial Intelligence (XAI) methods are employed in order to compensate for the lack of transparency of most efficient predictive models. Even when employed under the same settings regarding data, preprocessing techniques, and ML models, explanations generated by multiple XAI methods differ profoundly. A comparison is missing to distinguish XAI characteristics or underlying conditions that are deterministic to an explanation. To address this gap, we provide a framework to enable studying the effect of different PPM-related settings and ML model-related choices on characteristics and expressiveness of resulting explanations. In addition, we compare how different explainability methods characteristics can shape resulting explanations and enable reflecting underlying model reasoning process
Explainability of Predictive Process Monitoring Results: Can You See My Data Issues?
Feb 16, 2022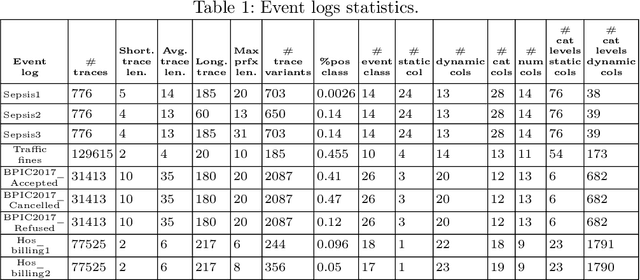

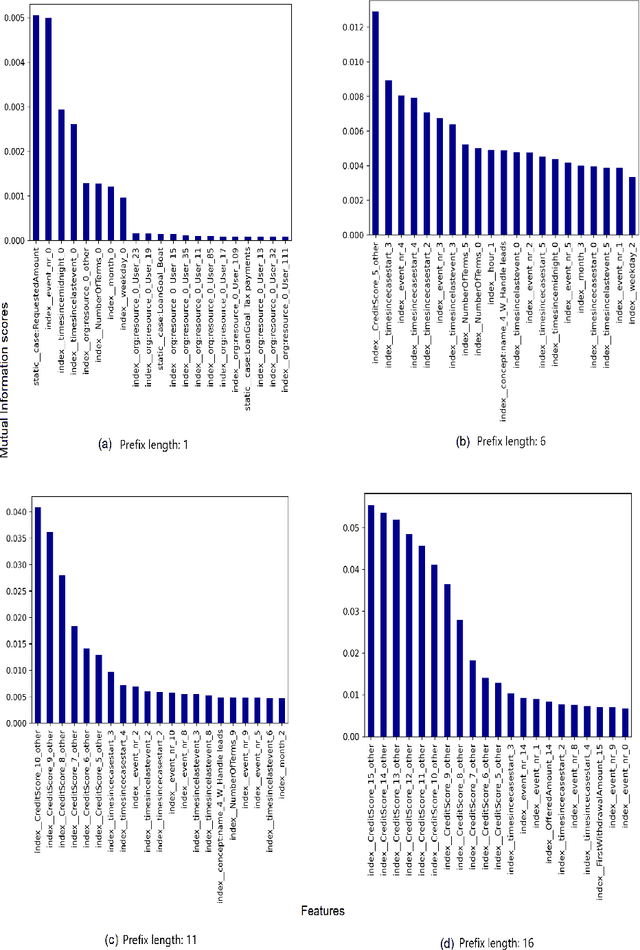
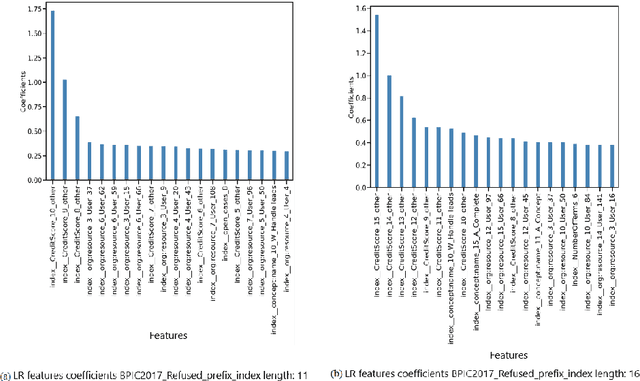
Predictive business process monitoring (PPM) has been around for several years as a use case of process mining. PPM enables foreseeing the future of a business process through predicting relevant information about how a running process instance might end, related performance indicators, and other predictable aspects. A big share of PPM approaches adopts a Machine Learning (ML) technique to address a prediction task, especially non-process-aware PPM approaches. Consequently, PPM inherits the challenges faced by ML approaches. One of these challenges concerns the need to gain user trust in the predictions generated. The field of explainable artificial intelligence (XAI) addresses this issue. However, the choices made, and the techniques employed in a PPM task, in addition to ML model characteristics, influence resulting explanations. A comparison of the influence of different settings on the generated explanations is missing. To address this gap, we investigate the effect of different PPM settings on resulting data fed into an ML model and consequently to a XAI method. We study how differences in resulting explanations may indicate several issues in underlying data. We construct a framework for our experiments including different settings at each stage of PPM with XAI integrated as a fundamental part. Our experiments reveal several inconsistencies, as well as agreements, between data characteristics (and hence expectations about these data), important data used by the ML model as a result of querying it, and explanations of predictions of the investigated ML model.
The Atlas of Lane Changes: Investigating Location-dependent Lane Change Behaviors Using Measurement Data from a Customer Fleet
Jul 09, 2021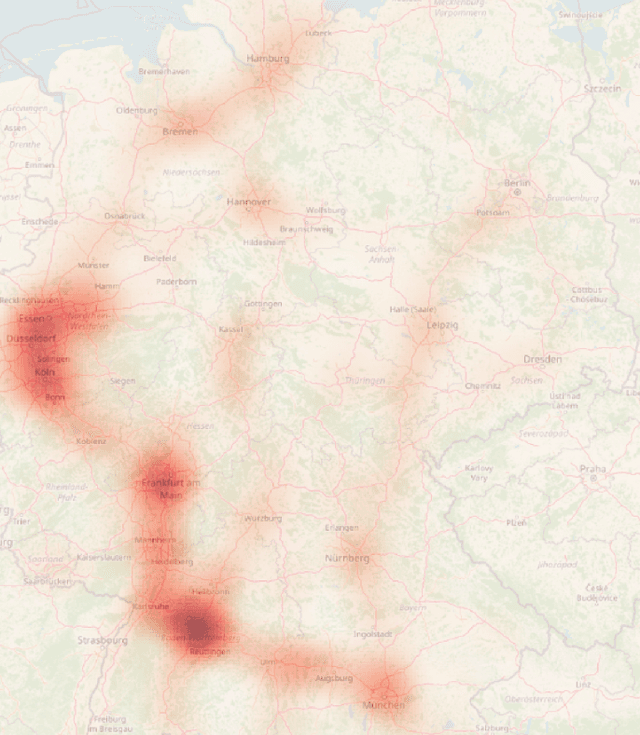
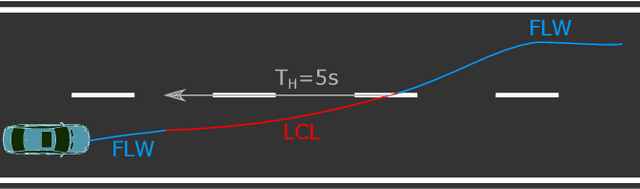
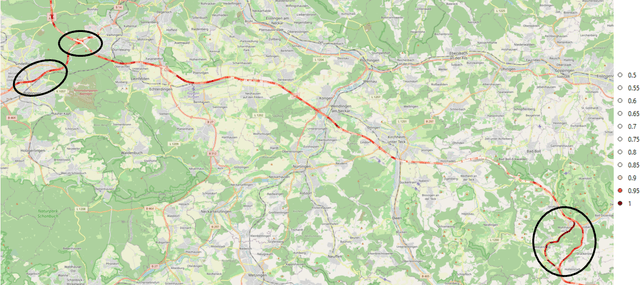
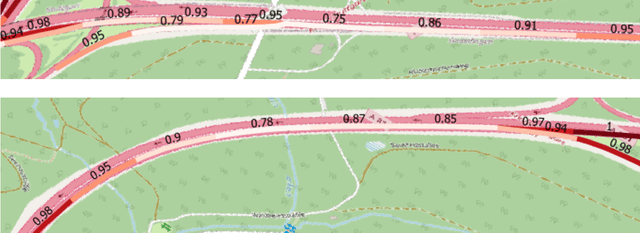
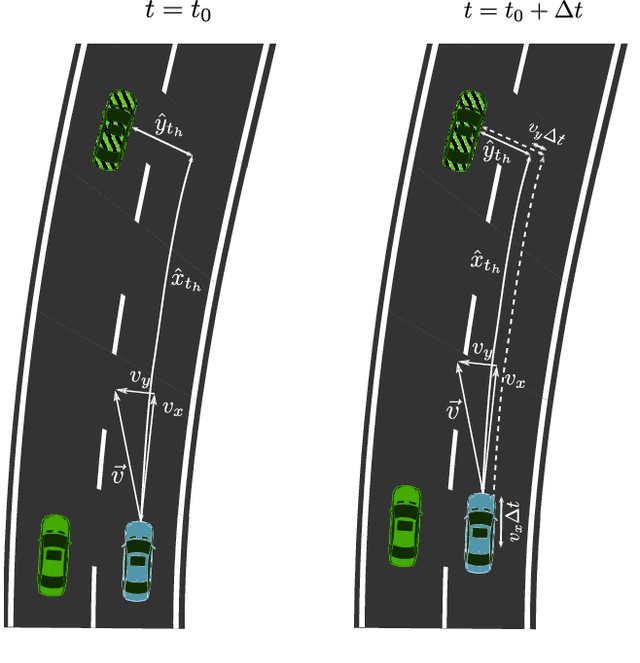
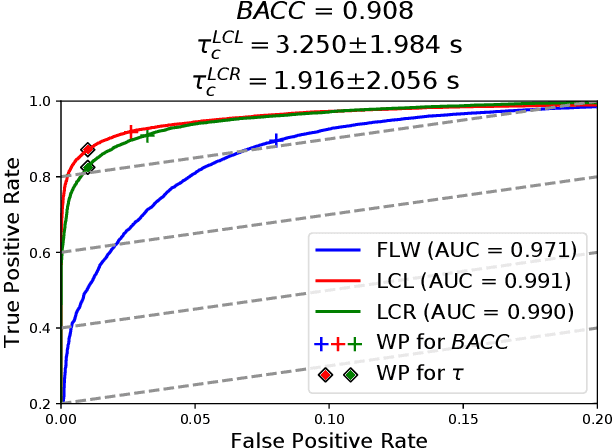
The prediction of surrounding traffic participants behavior is a crucial and challenging task for driver assistance and autonomous driving systems. Today's approaches mainly focus on modeling dynamic aspects of the traffic situation and try to predict traffic participants behavior based on this. In this article we take a first step towards extending this common practice by calculating location-specific a-priori lane change probabilities. The idea behind this is straight forward: The driving behavior of humans may vary in exactly the same traffic situation depending on the respective location. E.g. drivers may ask themselves: Should I pass the truck in front of me immediately or should I wait until reaching the less curvy part of my route lying only a few kilometers ahead? Although, such information is far away from allowing behavior prediction on its own, it is obvious that today's approaches will greatly benefit when incorporating such location-specific a-priori probabilities into their predictions. For example, our investigations show that highway interchanges tend to enhance driver's motivation to perform lane changes, whereas curves seem to have lane change-dampening effects. Nevertheless, the investigation of all considered local conditions shows that superposition of various effects can lead to unexpected probabilities at some locations. We thus suggest dynamically constructing and maintaining a lane change probability map based on customer fleet data in order to support onboard prediction systems with additional information. For deriving reliable lane change probabilities a broad customer fleet is the key to success.
Predicting the Time Until a Vehicle Changes the Lane Using LSTM-based Recurrent Neural Networks
Feb 03, 2021
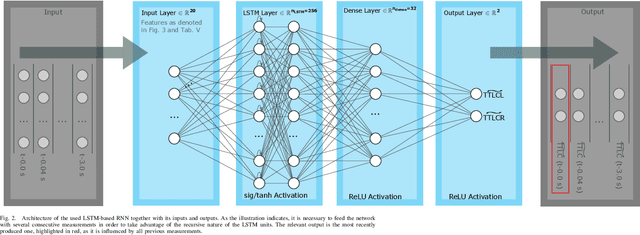
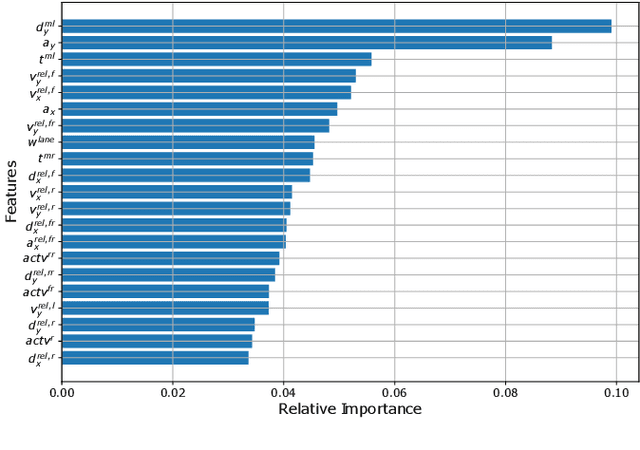
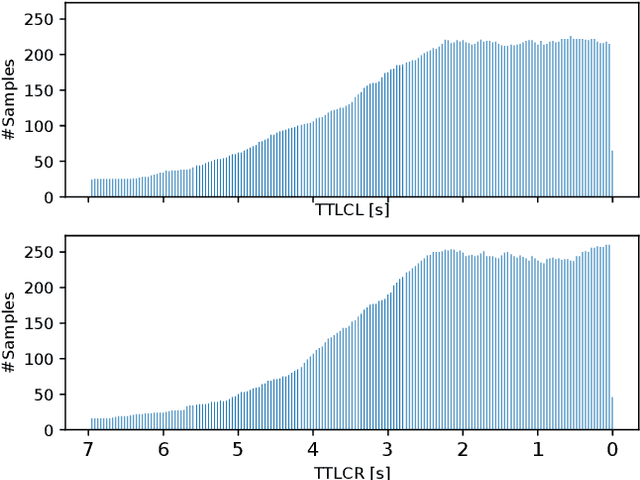
To plan safe and comfortable trajectories for automated vehicles on highways, accurate predictions of traffic situations are needed. So far, a lot of research effort has been spent on detecting lane change maneuvers rather than on estimating the point in time a lane change actually happens. In practice, however, this temporal information might be even more useful. This paper deals with the development of a system that accurately predicts the time to the next lane change of surrounding vehicles on highways using long short-term memory-based recurrent neural networks. An extensive evaluation based on a large real-world data set shows that our approach is able to make reliable predictions, even in the most challenging situations, with a root mean squared error around 0.7 seconds. Already 3.5 seconds prior to lane changes the predictions become highly accurate, showing a median error of less than 0.25 seconds. In summary, this article forms a fundamental step towards downstreamed highly accurate position predictions.
Robotic Process Automation -- A Systematic Literature Review and Assessment Framework
Dec 22, 2020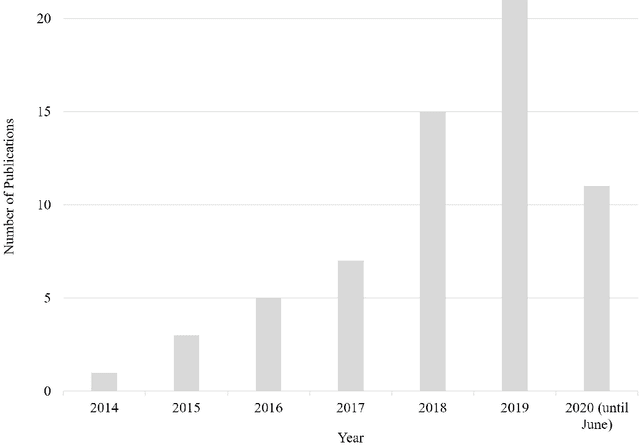



Robotic Process Automation (RPA) is the automation of rule-based routine processes to increase efficiency and to reduce costs. Due to the utmost importance of process automation in industry, RPA attracts increasing attention in the scientific field as well. This paper presents the state-of-the-art in the RPA field by means of a Systematic Literature Review (SLR). In this SLR, 63 publications are identified, categorised, and analysed along well-defined research questions. From the SLR findings, moreover, a framework for systematically analysing, assessing, and comparing existing as well as upcoming RPA works is derived. The discovered thematic clusters advise further investigations in order to develop an even more detailed structural research approach for RPA.
A Fleet Learning Architecture for Enhanced Behavior Predictions during Challenging External Conditions
Sep 24, 2020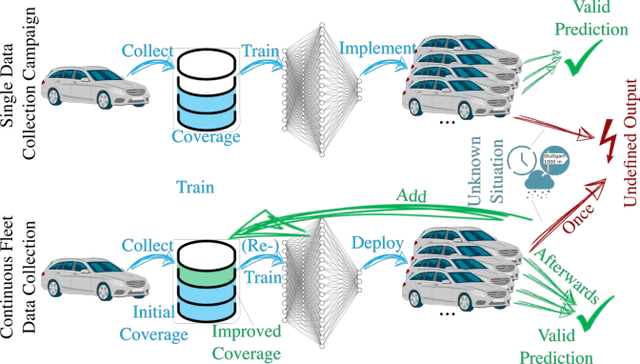
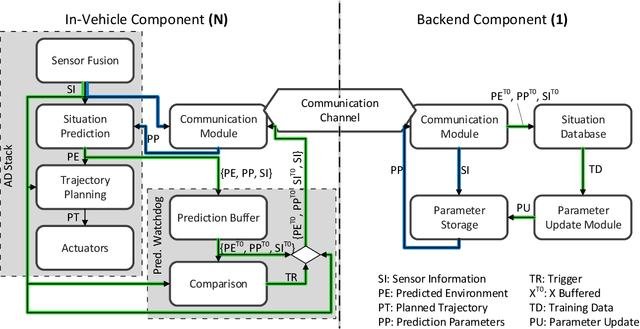

Already today, driver assistance systems help to make daily traffic more comfortable and safer. However, there are still situations that are quite rare but are hard to handle at the same time. In order to cope with these situations and to bridge the gap towards fully automated driving, it becomes necessary to not only collect enormous amounts of data but rather the right ones. This data can be used to develop and validate the systems through machine learning and simulation pipelines. Along this line this paper presents a fleet learning-based architecture that enables continuous improvements of systems predicting the movement of surrounding traffic participants. Moreover, the presented architecture is applied to a testing vehicle in order to prove the fundamental feasibility of the system. Finally, it is shown that the system collects meaningful data which are helpful to improve the underlying prediction systems.
CONDA-PM -- A Systematic Review and Framework for Concept Drift Analysis in Process Mining
Sep 08, 2020
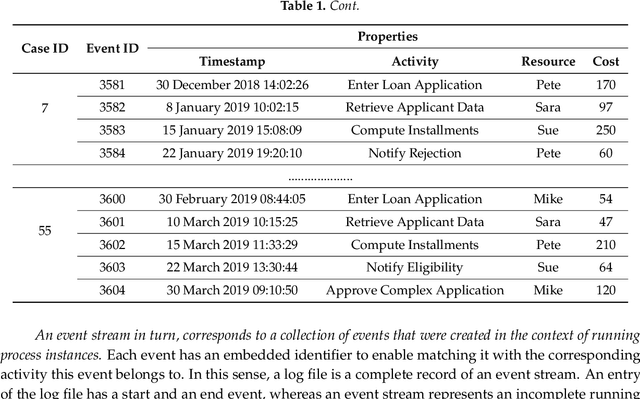
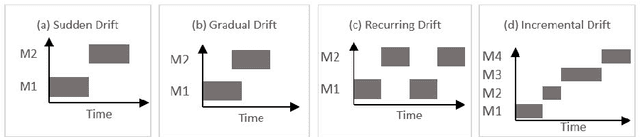
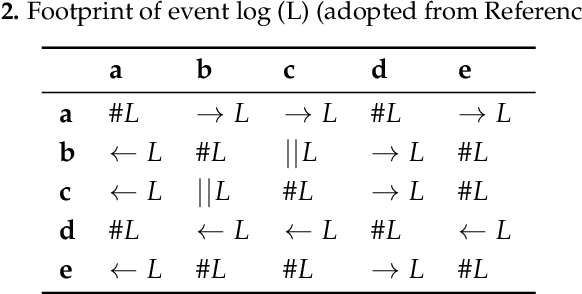
Business processes evolve over time to adapt to changing business environments. This requires continuous monitoring of business processes to gain insights into whether they conform to the intended design or deviate from it. The situation when a business process changes while being analysed is denoted as Concept Drift. Its analysis is concerned with studying how a business process changes, in terms of detecting and localising changes and studying the effects of the latter. Concept drift analysis is crucial to enable early detection and management of changes, that is, whether to promote a change to become part of an improved process, or to reject the change and make decisions to mitigate its effects. Despite its importance, there exists no comprehensive framework for analysing concept drift types, affected process perspectives, and granularity levels of a business process. This article proposes the CONcept Drift Analysis in Process Mining (CONDA-PM) framework describing phases and requirements of a concept drift analysis approach. CONDA-PM was derived from a Systematic Literature Review (SLR) of current approaches analysing concept drift. We apply the CONDA-PM framework on current approaches to concept drift analysis and evaluate their maturity. Applying CONDA-PM framework highlights areas where research is needed to complement existing efforts.
* 45 pages, 11 tables, 13 figures
Towards Incorporating Contextual Knowledge into the Prediction of Driving Behavior
Jul 04, 2020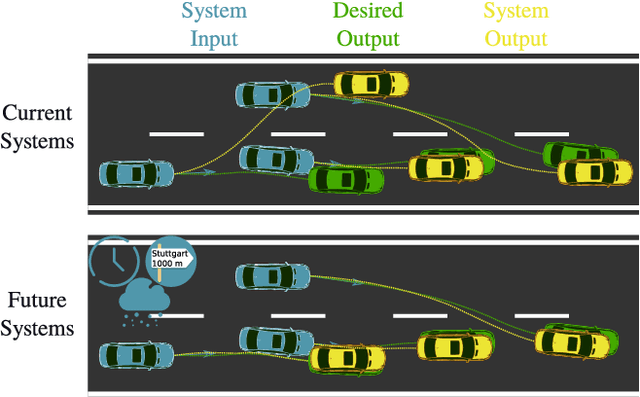
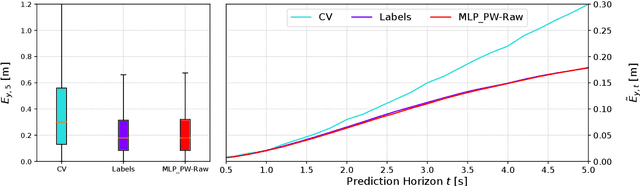
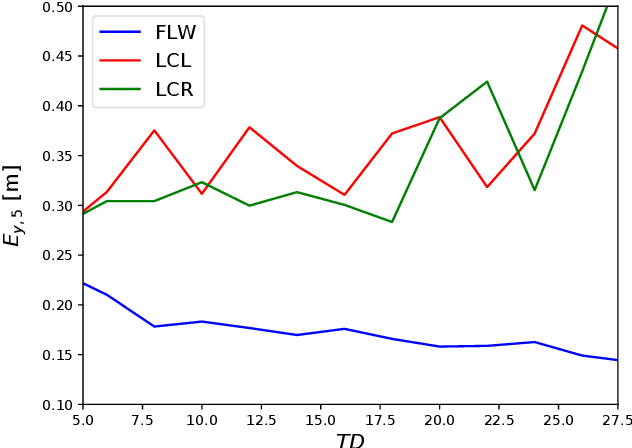
Predicting the behavior of surrounding traffic participants is crucial for advanced driver assistance systems and autonomous driving. Most researchers however do not consider contextual knowledge when predicting vehicle motion. Extending former studies, we investigate how predictions are affected by external conditions. To do so, we categorize different kinds of contextual information and provide a carefully chosen definition as well as examples for external conditions. More precisely, we investigate how a state-of-the-art approach for lateral motion prediction is influenced by one selected external condition, namely the traffic density. Our investigations demonstrate that this kind of information is highly relevant in order to improve the performance of prediction algorithms. Therefore, this study constitutes the first step towards the integration of such information into automated vehicles. Moreover, our motion prediction approach is evaluated based on the public highD data set showing a maneuver prediction performance with areas under the ROC curve above 97% and a median lateral prediction error of only 0.18m on a prediction horizon of 5s.
Detecting Production Phases Based on Sensor Values using 1D-CNNs
Apr 24, 2020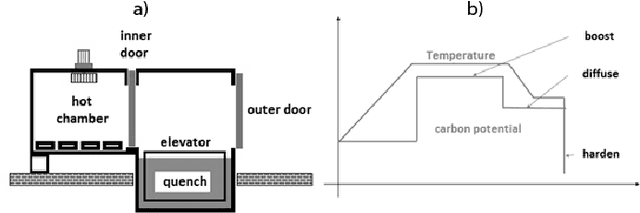
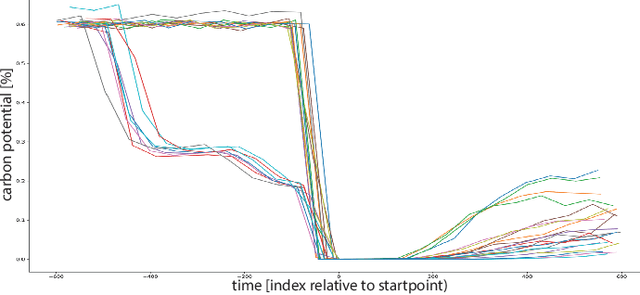
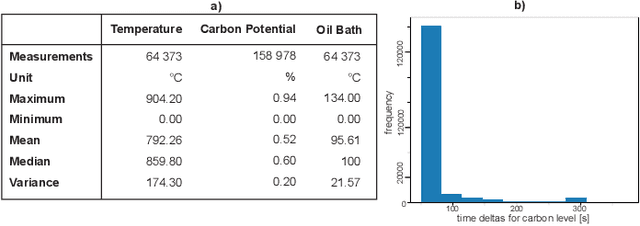
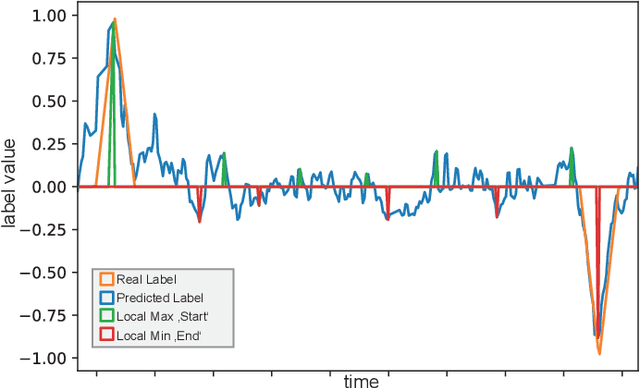
In the context of Industry 4.0, the knowledge extraction from sensor information plays an important role. Often, information gathered from sensor values reveals meaningful insights for production levels, such as anomalies or machine states. In our use case, we identify production phases through the inspection of sensor values with the help of convolutional neural networks. The data set stems from a tempering furnace used for metal heat treating. Our supervised learning approach unveils a promising accuracy for the chosen neural network that was used for the detection of production phases. We consider solutions like shown in this work as salient pillars in the field of predictive maintenance.