 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing hierarchies in scRNA-seq data using a density tree-biased autoencoder
Feb 11, 2021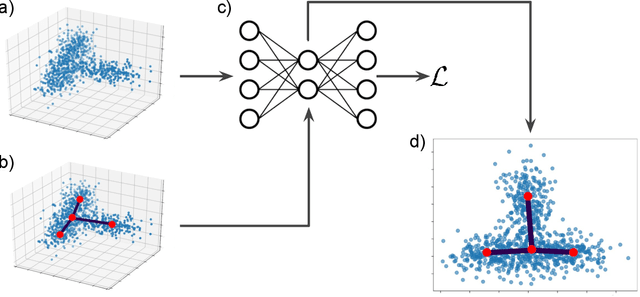
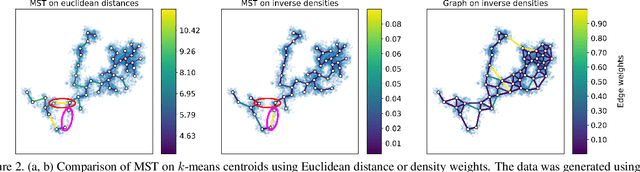
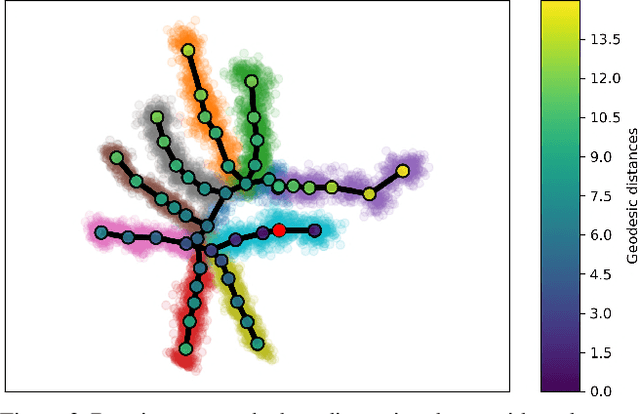
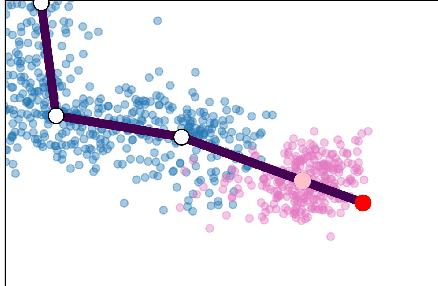
Single cell RNA sequencing (scRNA-seq) data makes studying the development of cells possible at unparalleled resolution. Given that many cellular differentiation processes are hierarchical, their scRNA-seq data is expected to be approximately tree-shaped in gene expression space. Inference and representation of this tree-structure in two dimensions is highly desirable for biological interpretation and exploratory analysis. Our two contributions are an approach for identifying a meaningful tree structure from high-dimensional scRNA-seq data, and a visualization method respecting the tree-structure. We extract the tree structure by means of a density based minimum spanning tree on a vector quantization of the data and show that it captures biological information well. We then introduce DTAE, a tree-biased autoencoder that emphasizes the tree structure of the data in low dimensional space. We compare to other dimension reduction methods and demonstrate the success of our method experimentally. Our implementation relying on PyTorch and Higra is available at github.com/hci-unihd/DTAE.
Mixture-of-Experts Variational Autoencoder for clustering and generating from similarity-based representations
Oct 17, 2019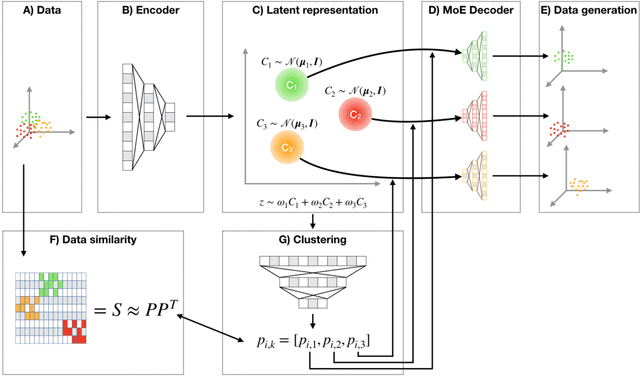
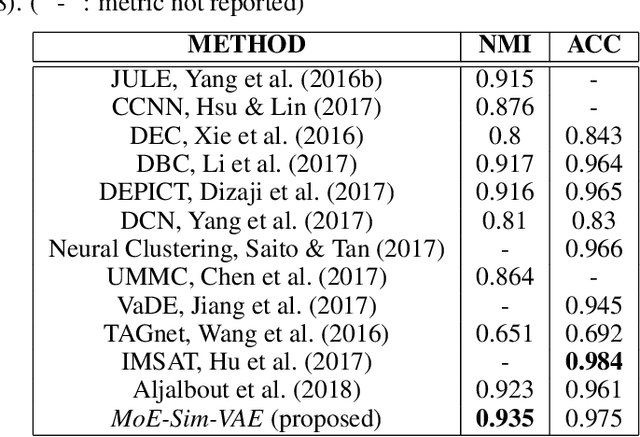
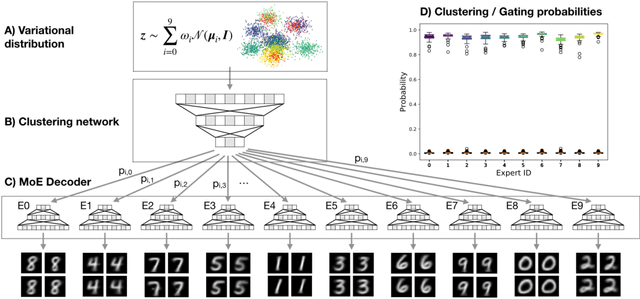
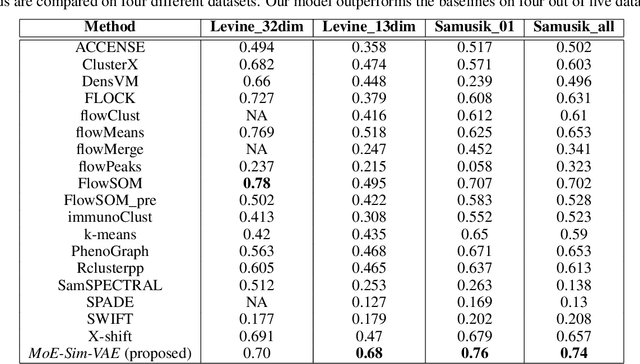
Clustering high-dimensional data, such as images or biological measurements, is a long-standing problem and has been studied extensively. Recently, Deep Clustering gained popularity due to the non-linearity of neural networks, which allows for flexibility in fitting the specific peculiarities of complex data. Here we introduce the Mixture-of-Experts Similarity Variational Autoencoder (MoE-Sim-VAE), a novel generative clustering model. The model can learn multi-modal distributions of high-dimensional data and use these to generate realistic data with high efficacy and efficiency. MoE-Sim-VAE is based on a Variational Autoencoder (VAE), where the decoder consists of a Mixture-of-Experts (MoE) architecture. This specific architecture allows for various modes of the data to be automatically learned by means of the experts. Additionally, we encourage the latent representation of our model to follow a Gaussian mixture distribution and to accurately represent the similarities between the data points. We assess the performance of our model on synthetic data, the MNIST benchmark data set, and a challenging real-world task of defining cell subpopulations from mass cytometry (CyTOF) measurements on hundreds of different datasets. MoE-Sim-VAE exhibits superior clustering performance on all these tasks in comparison to the baselines and we show that the MoE architecture in the decoder reduces the computational cost of sampling specific data modes with high fidelity.
Coupling weak and strong supervision for classification of prostate cancer histopathology images
Nov 16, 2018
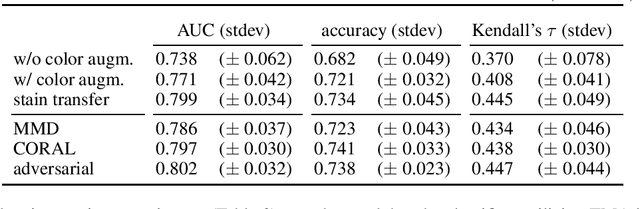
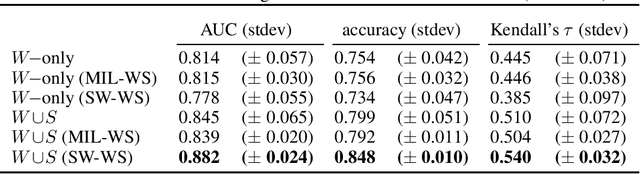
Automated grading of prostate cancer histopathology images is a challenging task, with one key challenge being the scarcity of annotations down to the level of regions of interest (strong labels), as typically the prostate cancer Gleason score is known only for entire tissue slides (weak labels). In this study, we focus on automated Gleason score assignment of prostate cancer whole-slide images on the basis of a large weakly-labeled dataset and a smaller strongly-labeled one. We efficiently leverage information from both label sources by jointly training a classifier on the two datasets and by introducing a gradient update scheme that assigns different relative importances to each training example, as a means of self-controlling the weak supervision signal. Our approach achieves superior performance when compared with standard Gleason scoring methods.
A Fused Elastic Net Logistic Regression Model for Multi-Task Binary Classification
Dec 30, 2013

Multi-task learning has shown to significantly enhance the performance of multiple related learning tasks in a variety of situations. We present the fused logistic regression, a sparse multi-task learning approach for binary classification. Specifically, we introduce sparsity inducing penalties over parameter differences of related logistic regression models to encode similarity across related tasks. The resulting joint learning task is cast into a form that lends itself to be efficiently optimized with a recursive variant of the alternating direction method of multipliers. We show results on synthetic data and describe the regime of settings where our multi-task approach achieves significant improvements over the single task learning approach and discuss the implications on applying the fused logistic regression in different real world settings.
Markov Network Structure Learning via Ensemble-of-Forests Models
Dec 17, 2013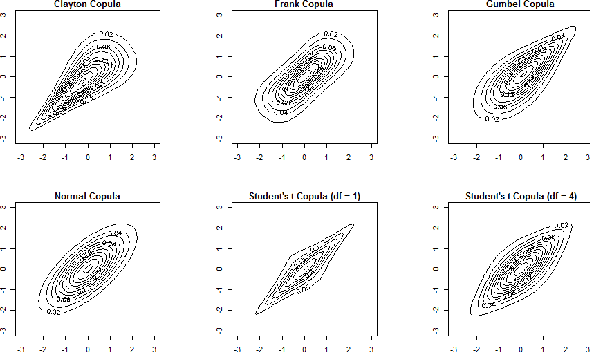
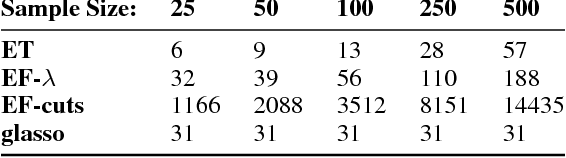
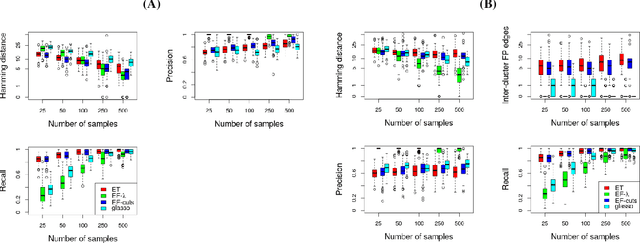

Real world systems typically feature a variety of different dependency types and topologies that complicate model selection for probabilistic graphical models. We introduce the ensemble-of-forests model, a generalization of the ensemble-of-trees model. Our model enables structure learning of Markov random fields (MRF) with multiple connected components and arbitrary potentials. We present two approximate inference techniques for this model and demonstrate their performance on synthetic data. Our results suggest that the ensemble-of-forests approach can accurately recover sparse, possibly disconnected MRF topologies, even in presence of non-Gaussian dependencies and/or low sample size. We applied the ensemble-of-forests model to learn the structure of perturbed signaling networks of immune cells and found that these frequently exhibit non-Gaussian dependencies with disconnected MRF topologies. In summary, we expect that the ensemble-of-forests model will enable MRF structure learning in other high dimensional real world settings that are governed by non-trivial dependencies.