 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient, Generalized Bellman Update For Cooperative Inverse Reinforcement Learning
Jun 11, 2018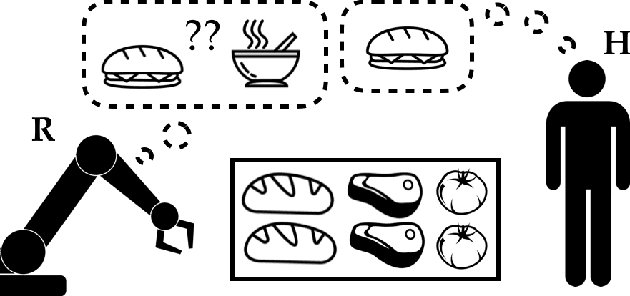

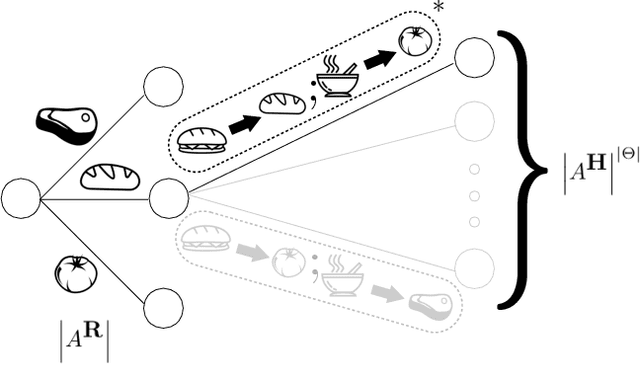

Our goal is for AI systems to correctly identify and act according to their human user's objectives. Cooperative Inverse Reinforcement Learning (CIRL) formalizes this value alignment problem as a two-player game between a human and robot, in which only the human knows the parameters of the reward function: the robot needs to learn them as the interaction unfolds. Previous work showed that CIRL can be solved as a POMDP, but with an action space size exponential in the size of the reward parameter space. In this work, we exploit a specific property of CIRL---the human is a full information agent---to derive an optimality-preserving modification to the standard Bellman update; this reduces the complexity of the problem by an exponential factor and allows us to relax CIRL's assumption of human rationality. We apply this update to a variety of POMDP solvers and find that it enables us to scale CIRL to non-trivial problems, with larger reward parameter spaces, and larger action spaces for both robot and human. In solutions to these larger problems, the human exhibits pedagogic (teaching) behavior, while the robot interprets it as such and attains higher value for the human.
Pragmatic-Pedagogic Value Alignment
Feb 05, 2018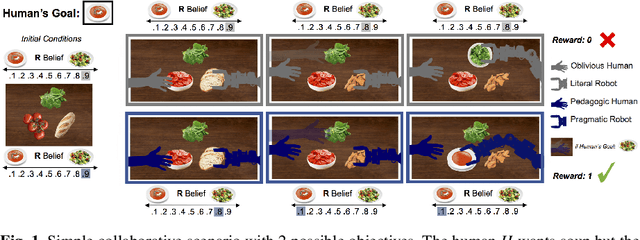

As intelligent systems gain autonomy and capability, it becomes vital to ensure that their objectives match those of their human users; this is known as the value-alignment problem. In robotics, value alignment is key to the design of collaborative robots that can integrate into human workflows, successfully inferring and adapting to their users' objectives as they go. We argue that a meaningful solution to value alignment must combine multi-agent decision theory with rich mathematical models of human cognition, enabling robots to tap into people's natural collaborative capabilities. We present a solution to the cooperative inverse reinforcement learning (CIRL) dynamic game based on well-established cognitive models of decision making and theory of mind. The solution captures a key reciprocity relation: the human will not plan her actions in isolation, but rather reason pedagogically about how the robot might learn from them; the robot, in turn, can anticipate this and interpret the human's actions pragmatically. To our knowledge, this work constitutes the first formal analysis of value alignment grounded in empirically validated cognitive models.
* Published at the International Symposium on Robotics Research (ISRR 2017)