 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePragmatic-Pedagogic Value Alignment
Feb 05, 2018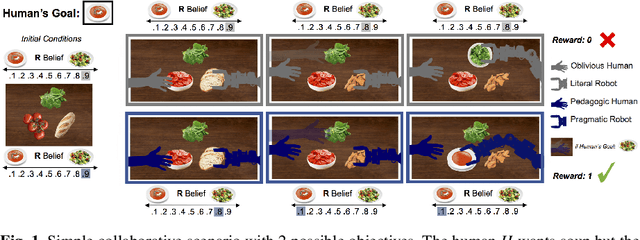

As intelligent systems gain autonomy and capability, it becomes vital to ensure that their objectives match those of their human users; this is known as the value-alignment problem. In robotics, value alignment is key to the design of collaborative robots that can integrate into human workflows, successfully inferring and adapting to their users' objectives as they go. We argue that a meaningful solution to value alignment must combine multi-agent decision theory with rich mathematical models of human cognition, enabling robots to tap into people's natural collaborative capabilities. We present a solution to the cooperative inverse reinforcement learning (CIRL) dynamic game based on well-established cognitive models of decision making and theory of mind. The solution captures a key reciprocity relation: the human will not plan her actions in isolation, but rather reason pedagogically about how the robot might learn from them; the robot, in turn, can anticipate this and interpret the human's actions pragmatically. To our knowledge, this work constitutes the first formal analysis of value alignment grounded in empirically validated cognitive models.
* Published at the International Symposium on Robotics Research (ISRR 2017)