 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISK: Domain-constrained Instance Sketch for Math Word Problem Generation
Apr 10, 2022
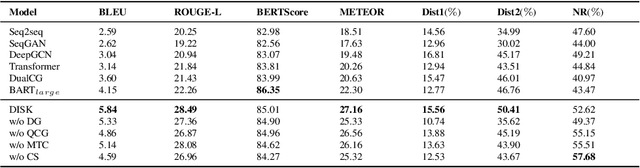

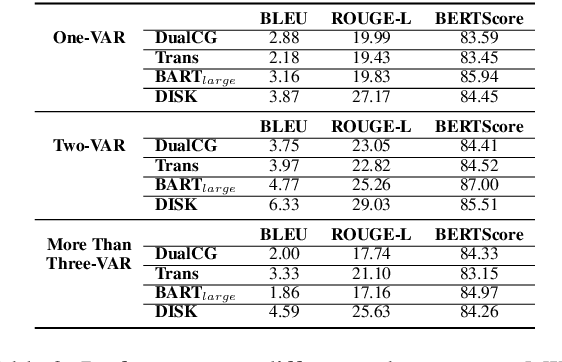
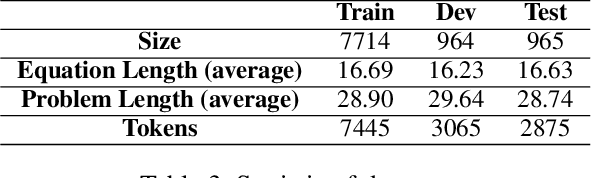
A math word problem (MWP) is a coherent narrative which reflects the underlying logic of math equations. Successful MWP generation can automate the writing of mathematics questions. Previous methods mainly generate MWP text based on inflexible pre-defined templates. In this paper, we propose a neural model for generating MWP text from math equations. Firstly, we incorporate a matching model conditioned on the domain knowledge to retrieve a MWP instance which is most consistent with the ground-truth, where the domain is a latent variable extracted with a domain summarizer. Secondly, by constructing a Quantity Cell Graph (QCG) from the retrieved MWP instance and reasoning over it, we improve the model's comprehension of real-world scenarios and derive a domain-constrained instance sketch to guide the generation. Besides, the QCG also interacts with the equation encoder to enhance the alignment between math tokens (e.g., quantities and variables) and MWP text. Experiments and empirical analysis on educational MWP set show that our model achieves impressive performance in both automatic evaluation metrics and human evaluation metrics.
Generating Math Word Problems from Equations with Topic Controlling and Commonsense Enforcement
Dec 14, 2020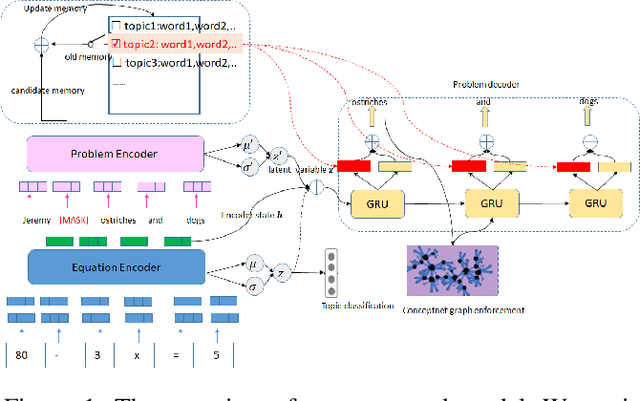
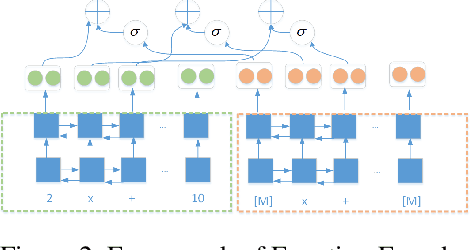
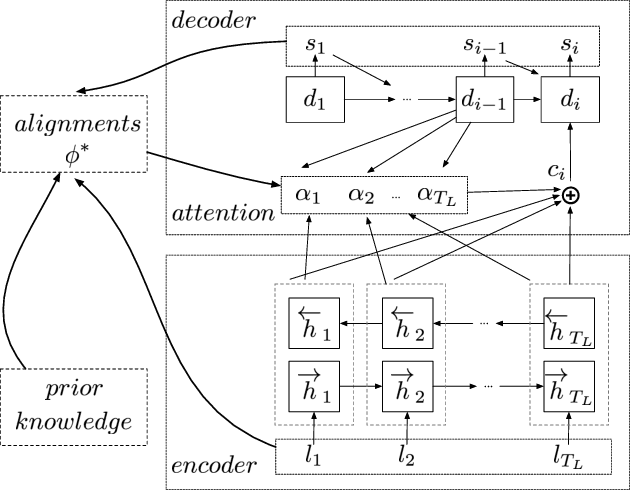
Recent years have seen significant advancement in text generation tasks with the help of neural language models. However, there exists a challenging task: generating math problem text based on mathematical equations, which has made little progress so far. In this paper, we present a novel equation-to-problem text generation model. In our model, 1) we propose a flexible scheme to effectively encode math equations, we then enhance the equation encoder by a Varitional Autoen-coder (VAE) 2) given a math equation, we perform topic selection, followed by which a dynamic topic memory mechanism is introduced to restrict the topic distribution of the generator 3) to avoid commonsense violation in traditional generation model, we pretrain word embedding with background knowledge graph (KG), and we link decoded words to related words in KG, targeted at injecting background knowledge into our model. We evaluate our model through both automatic metrices and human evaluation, experiments demonstrate our model outperforms baseline and previous models in both accuracy and richness of generated problem text.
KNPTC: Knowledge and Neural Machine Translation Powered Chinese Pinyin Typo Correction
May 02, 2018
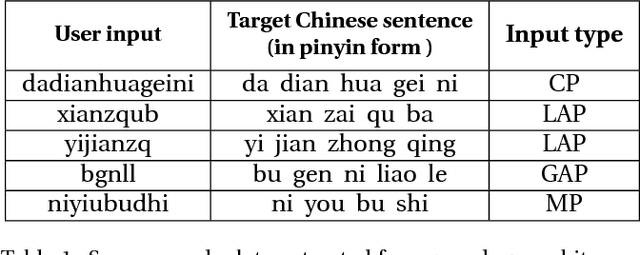
Chinese pinyin input methods are very important for Chinese language processing. Actually, users may make typos inevitably when they input pinyin. Moreover, pinyin typo correction has become an increasingly important task with the popularity of smartphones and the mobile Internet. How to exploit the knowledge of users typing behaviors and support the typo correction for acronym pinyin remains a challenging problem. To tackle these challenges, we propose KNPTC, a novel approach based on neural machine translation (NMT). In contrast to previous work, KNPTC is able to integrate explicit knowledge into NMT for pinyin typo correction, and is able to learn to correct a variety of typos without the guidance of manually selected constraints or languagespecific features. In this approach, we first obtain the transition probabilities between adjacent letters based on large-scale real-life datasets. Then, we construct the "ground-truth" alignments of training sentence pairs by utilizing these probabilities. Furthermore, these alignments are integrated into NMT to capture sensible pinyin typo correction patterns. KNPTC is applied to correct typos in real-life datasets, which achieves 32.77% increment on average in accuracy rate of typo correction compared against the state-of-the-art system.