 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Continuous Kernels with Sparse Fourier Domain Learning
Sep 15, 2024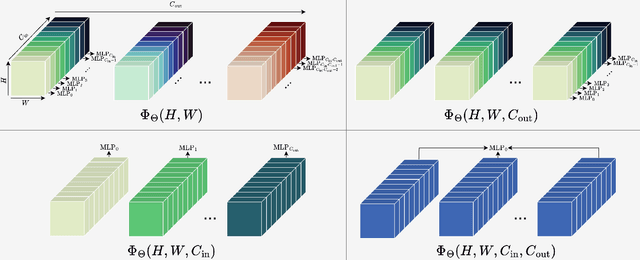

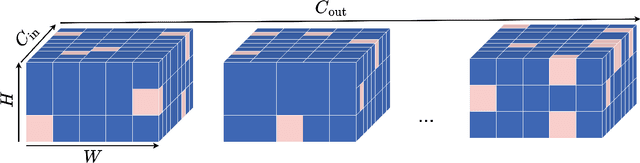

We address three key challenges in learning continuous kernel representations: computational efficiency, parameter efficiency, and spectral bias. Continuous kernels have shown significant potential, but their practical adoption is often limited by high computational and memory demands. Additionally, these methods are prone to spectral bias, which impedes their ability to capture high-frequency details. To overcome these limitations, we propose a novel approach that leverages sparse learning in the Fourier domain. Our method enables the efficient scaling of continuous kernels, drastically reduces computational and memory requirements, and mitigates spectral bias by exploiting the Gibbs phenomenon.
KerasCV and KerasNLP: Vision and Language Power-Ups
May 31, 2024
We present the Keras domain packages KerasCV and KerasNLP, extensions of the Keras API for Computer Vision and Natural Language Processing workflows, capable of running on either JAX, TensorFlow, or PyTorch. These domain packages are designed to enable fast experimentation, with a focus on ease-of-use and performance. We adopt a modular, layered design: at the library's lowest level of abstraction, we provide building blocks for creating models and data preprocessing pipelines, and at the library's highest level of abstraction, we provide pretrained ``task" models for popular architectures such as Stable Diffusion, YOLOv8, GPT2, BERT, Mistral, CLIP, Gemma, T5, etc. Task models have built-in preprocessing, pretrained weights, and can be fine-tuned on raw inputs. To enable efficient training, we support XLA compilation for all models, and run all preprocessing via a compiled graph of TensorFlow operations using the tf.data API. The libraries are fully open-source (Apache 2.0 license) and available on GitHub.
Deep Learning Object Detection Approaches to Signal Identification
Nov 01, 2022

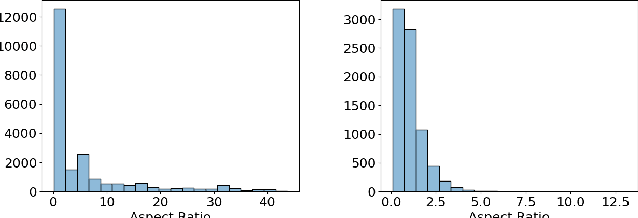
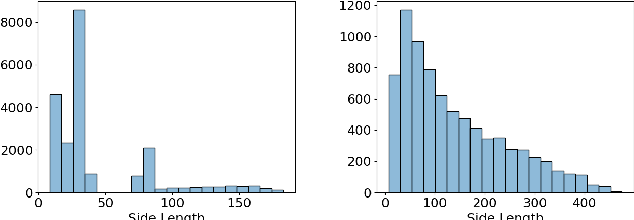
Traditionally source identification is solved using threshold based energy detection algorithms. These algorithms frequently sum up the activity in regions, and consider regions above a specific activity threshold to be sources. While these algorithms work for the majority of cases, they often fail to detect signals that occupy small frequency bands, fail to distinguish sources with overlapping frequency bands, and cannot detect any signals under a specified signal to noise ratio. Through the conversion of raw signal data to spectrogram, source identification can be framed as an object detection problem. By leveraging modern advancements in deep learning based object detection, we propose a system that manages to alleviate the failure cases encountered when using traditional source identification algorithms. Our contributions include framing source identification as an object detection problem, the publication of a spectrogram object detection dataset, and evaluation of the RetinaNet and YOLOv5 object detection models trained on the dataset. Our final models achieve Mean Average Precisions of up to 0.906. With such a high Mean Average Precision, these models are sufficiently robust for use in real world applications.
Efficient Graph-Friendly COCO Metric Computation for Train-Time Model Evaluation
Jul 21, 2022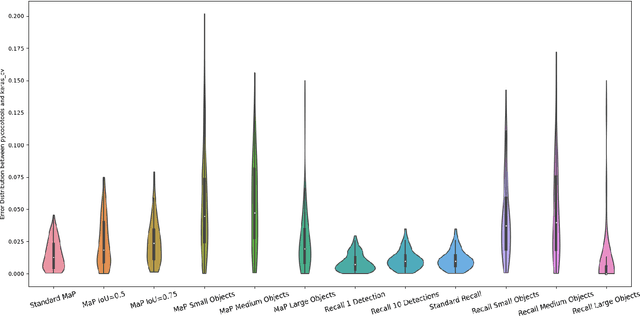
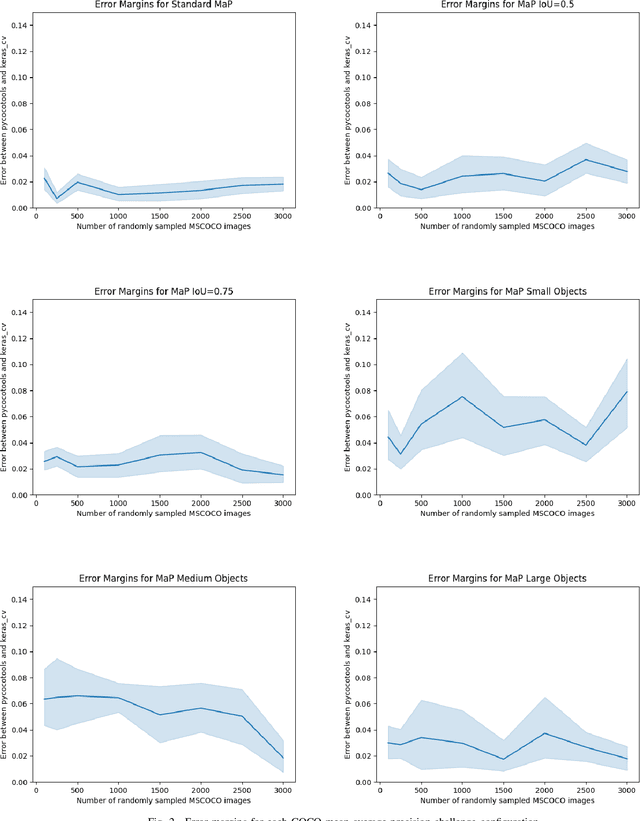
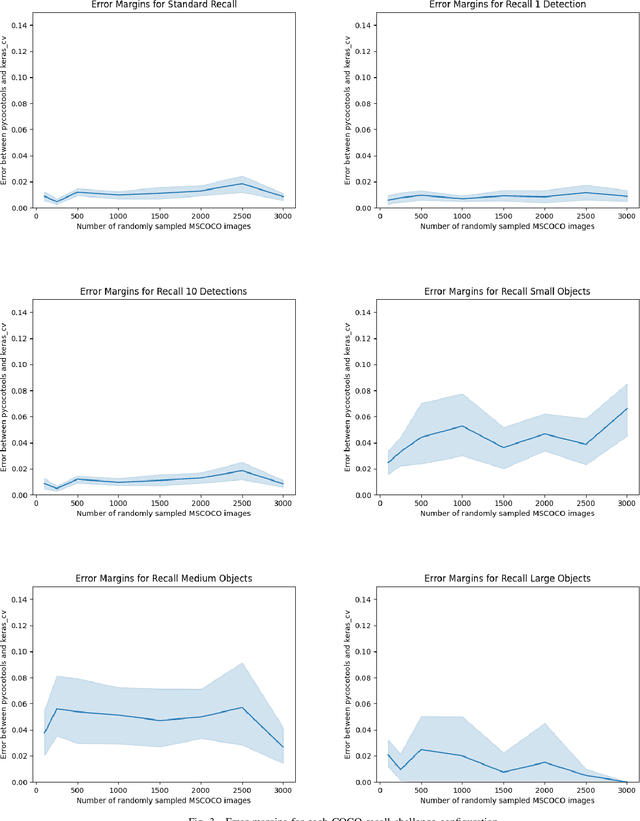
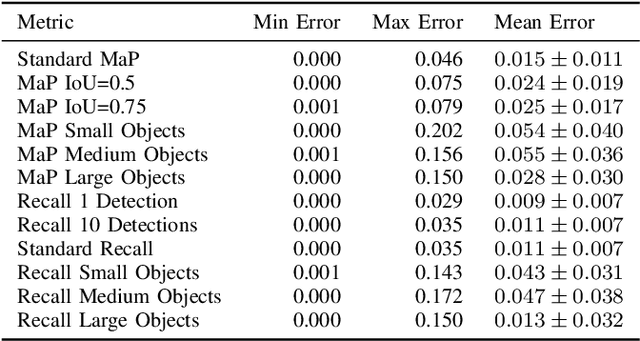
Evaluating the COCO mean average precision (MaP) and COCO recall metrics as part of the static computation graph of modern deep learning frameworks poses a unique set of challenges. These challenges include the need for maintaining a dynamic-sized state to compute mean average precision, reliance on global dataset-level statistics to compute the metrics, and managing differing numbers of bounding boxes between images in a batch. As a consequence, it is common practice for researchers and practitioners to evaluate COCO metrics as a post training evaluation step. With a graph-friendly algorithm to compute COCO Mean Average Precision and recall, these metrics could be evaluated at training time, improving visibility into the evolution of the metrics through training curve plots, and decreasing iteration time when prototyping new model versions. Our contributions include an accurate approximation algorithm for Mean Average Precision, an open source implementation of both COCO mean average precision and COCO recall, extensive numerical benchmarks to verify the accuracy of our implementations, and an open-source training loop that include train-time evaluation of mean average precision and recall.