 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Graph-Friendly COCO Metric Computation for Train-Time Model Evaluation
Paper and Code
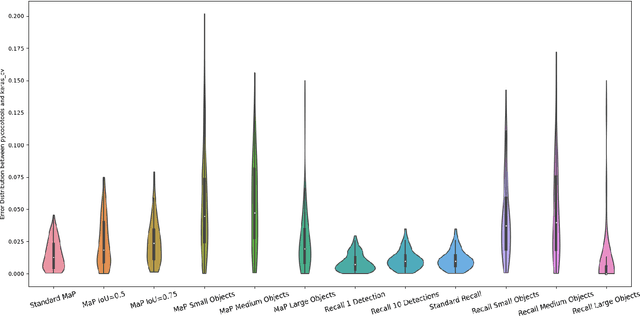
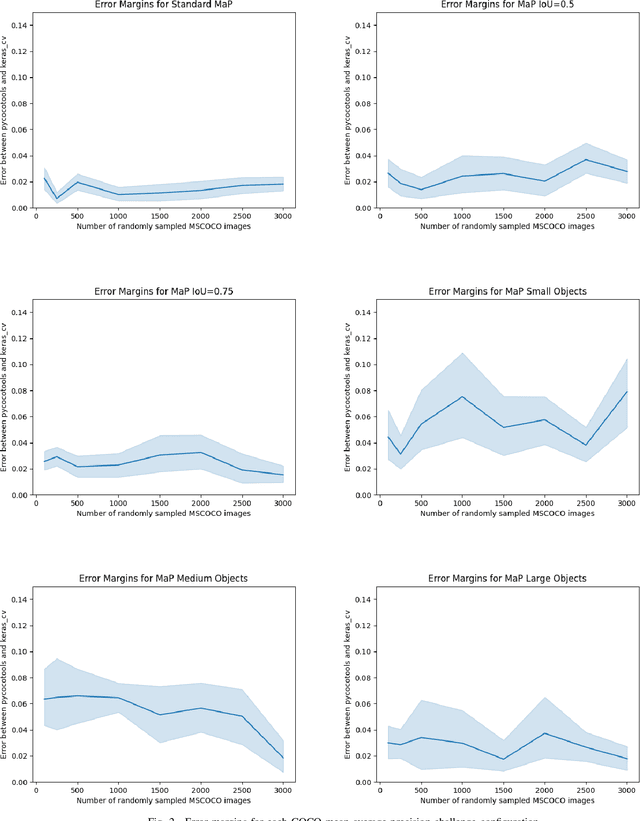
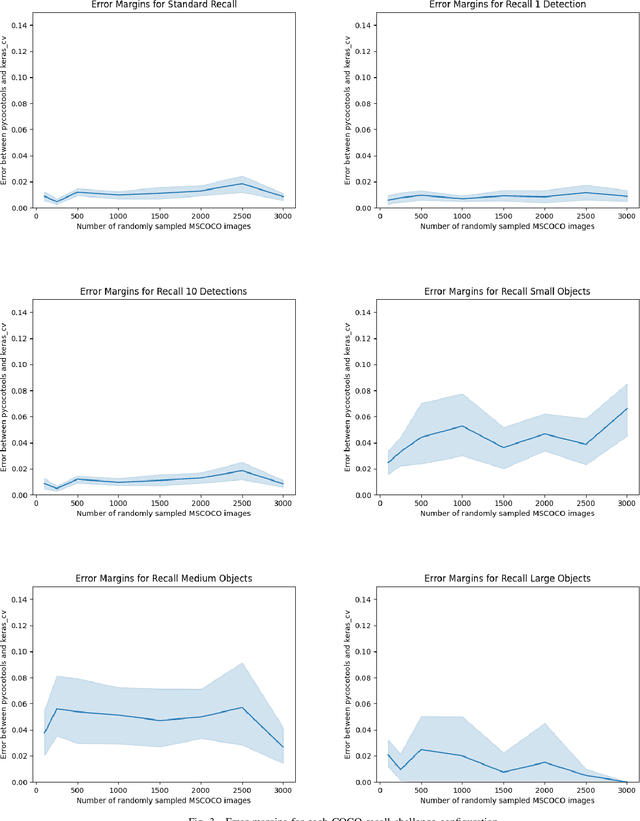
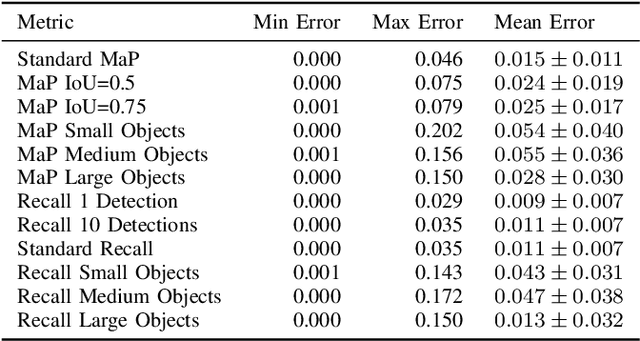
Evaluating the COCO mean average precision (MaP) and COCO recall metrics as part of the static computation graph of modern deep learning frameworks poses a unique set of challenges. These challenges include the need for maintaining a dynamic-sized state to compute mean average precision, reliance on global dataset-level statistics to compute the metrics, and managing differing numbers of bounding boxes between images in a batch. As a consequence, it is common practice for researchers and practitioners to evaluate COCO metrics as a post training evaluation step. With a graph-friendly algorithm to compute COCO Mean Average Precision and recall, these metrics could be evaluated at training time, improving visibility into the evolution of the metrics through training curve plots, and decreasing iteration time when prototyping new model versions. Our contributions include an accurate approximation algorithm for Mean Average Precision, an open source implementation of both COCO mean average precision and COCO recall, extensive numerical benchmarks to verify the accuracy of our implementations, and an open-source training loop that include train-time evaluation of mean average precision and recall.