 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling
Dec 14, 2020
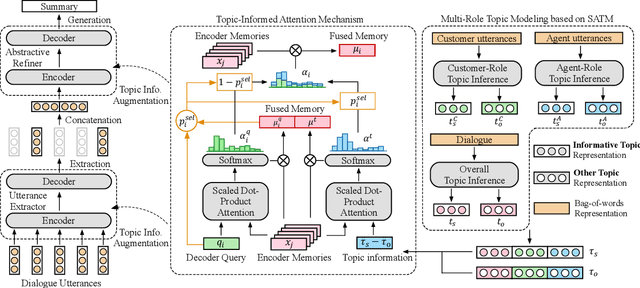
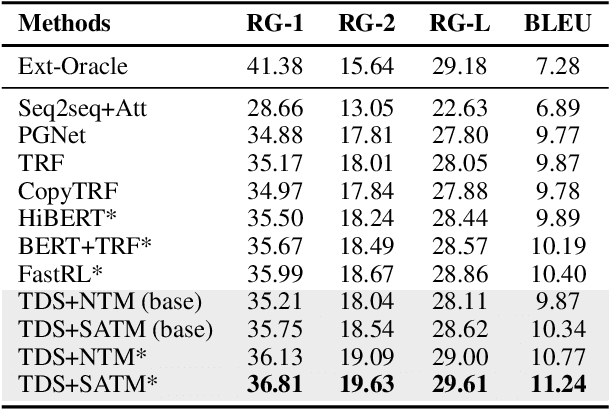
In a customer service system, dialogue summarization can boost service efficiency by automatically creating summaries for long spoken dialogues in which customers and agents try to address issues about specific topics. In this work, we focus on topic-oriented dialogue summarization, which generates highly abstractive summaries that preserve the main ideas from dialogues. In spoken dialogues, abundant dialogue noise and common semantics could obscure the underlying informative content, making the general topic modeling approaches difficult to apply. In addition, for customer service, role-specific information matters and is an indispensable part of a summary. To effectively perform topic modeling on dialogues and capture multi-role information, in this work we propose a novel topic-augmented two-stage dialogue summarizer (TDS) jointly with a saliency-aware neural topic model (SATM) for topic-oriented summarization of customer service dialogues. Comprehensive studies on a real-world Chinese customer service dataset demonstrated the superiority of our method against several strong baselines.
Unsupervised Summarization for Chat Logs with Topic-Oriented Ranking and Context-Aware Auto-Encoders
Dec 14, 2020

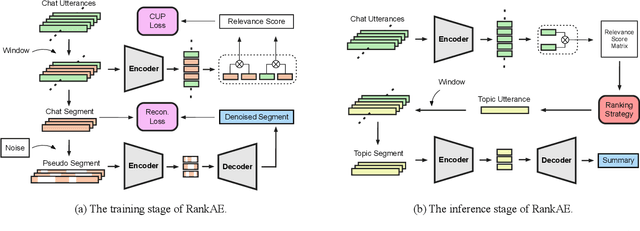
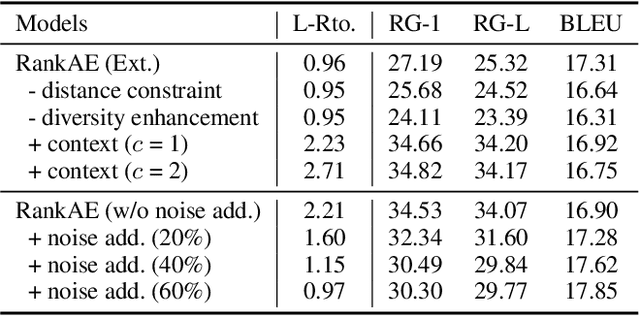
Automatic chat summarization can help people quickly grasp important information from numerous chat messages. Unlike conventional documents, chat logs usually have fragmented and evolving topics. In addition, these logs contain a quantity of elliptical and interrogative sentences, which make the chat summarization highly context dependent. In this work, we propose a novel unsupervised framework called RankAE to perform chat summarization without employing manually labeled data. RankAE consists of a topic-oriented ranking strategy that selects topic utterances according to centrality and diversity simultaneously, as well as a denoising auto-encoder that is carefully designed to generate succinct but context-informative summaries based on the selected utterances. To evaluate the proposed method, we collect a large-scale dataset of chat logs from a customer service environment and build an annotated set only for model evaluation. Experimental results show that RankAE significantly outperforms other unsupervised methods and is able to generate high-quality summaries in terms of relevance and topic coverage.
Cross-domain Aspect Category Transfer and Detection via Traceable Heterogeneous Graph Representation Learning
Aug 30, 2019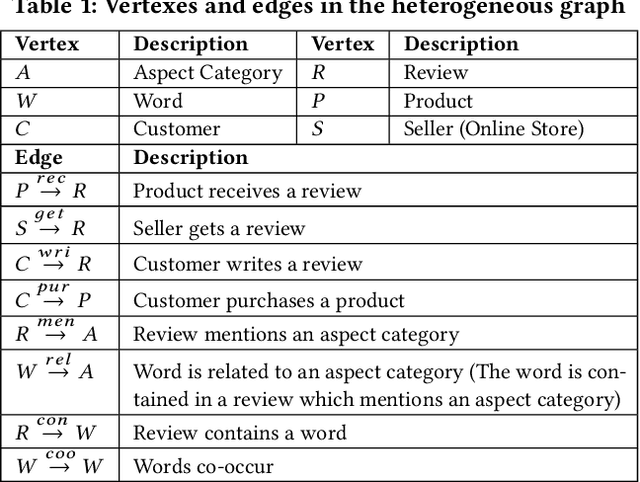
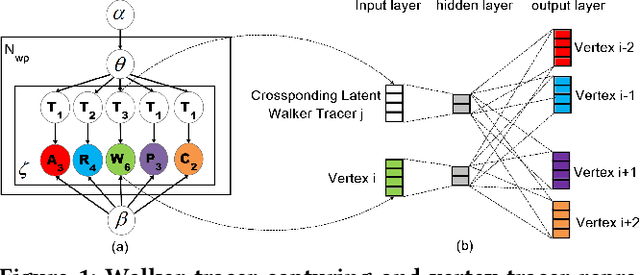
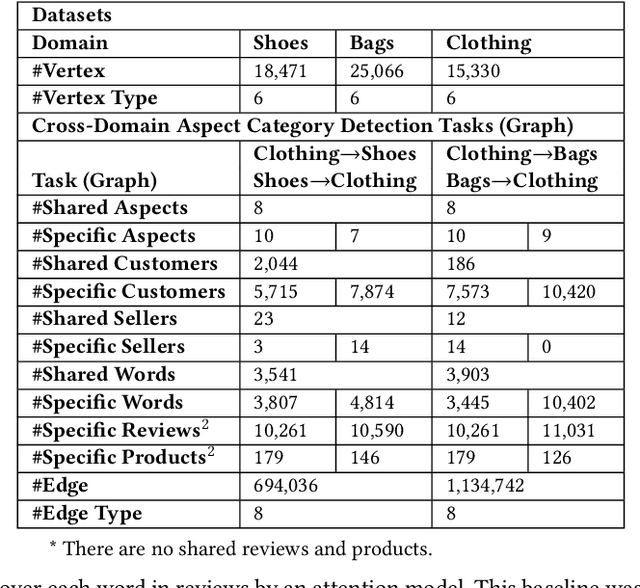
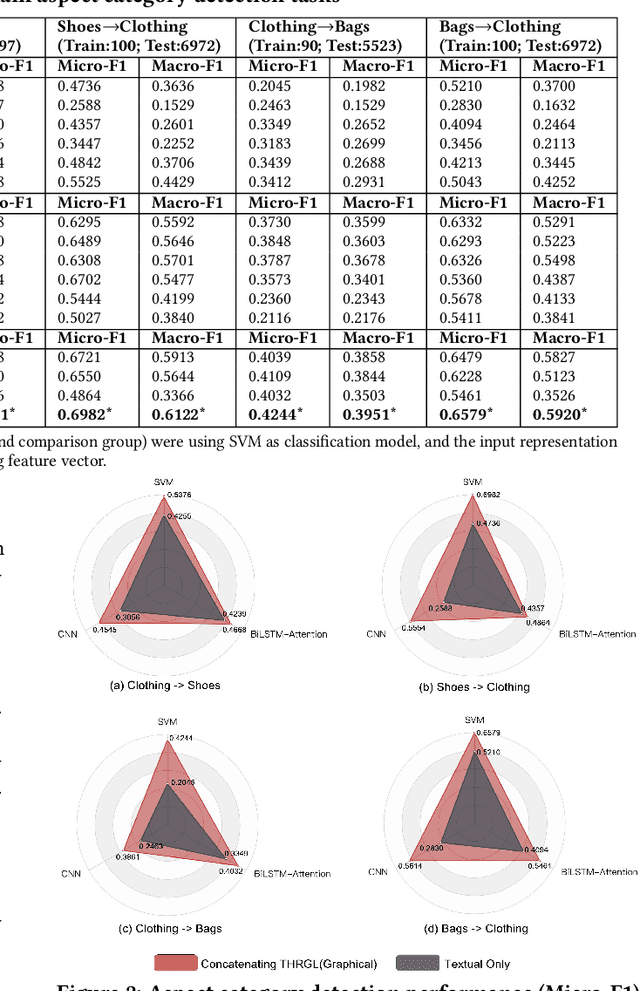
Aspect category detection is an essential task for sentiment analysis and opinion mining. However, the cost of categorical data labeling, e.g., label the review aspect information for a large number of product domains, can be inevitable but unaffordable. In this study, we propose a novel problem, cross-domain aspect category transfer and detection, which faces three challenges: various feature spaces, different data distributions, and diverse output spaces. To address these problems, we propose an innovative solution, Traceable Heterogeneous Graph Representation Learning (THGRL). Unlike prior text-based aspect detection works, THGRL explores latent domain aspect category connections via massive user behavior information on a heterogeneous graph. Moreover, an innovative latent variable "Walker Tracer" is introduced to characterize the global semantic/aspect dependencies and capture the informative vertexes on the random walk paths. By using THGRL, we project different domains' feature spaces into a common one, while allowing data distributions and output spaces stay differently. Experiment results show that the proposed method outperforms a series of state-of-the-art baseline models.
Long Short-Term Memory with Dynamic Skip Connections
Nov 09, 2018

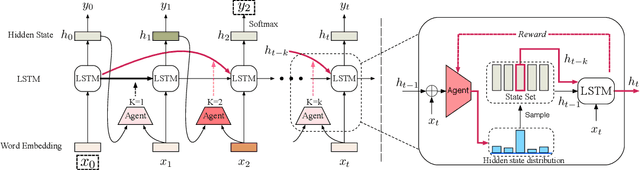
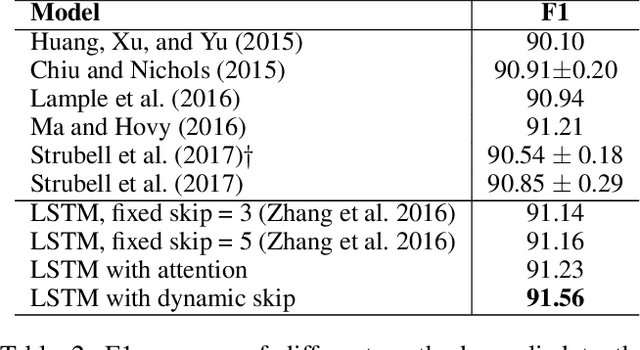
In recent years, long short-term memory (LSTM) has been successfully used to model sequential data of variable length. However, LSTM can still experience difficulty in capturing long-term dependencies. In this work, we tried to alleviate this problem by introducing a dynamic skip connection, which can learn to directly connect two dependent words. Since there is no dependency information in the training data, we propose a novel reinforcement learning-based method to model the dependency relationship and connect dependent words. The proposed model computes the recurrent transition functions based on the skip connections, which provides a dynamic skipping advantage over RNNs that always tackle entire sentences sequentially. Our experimental results on three natural language processing tasks demonstrate that the proposed method can achieve better performance than existing methods. In the number prediction experiment, the proposed model outperformed LSTM with respect to accuracy by nearly 20%.