 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFroSSL: Frobenius Norm Minimization for Self-Supervised Learning
Oct 04, 2023Self-supervised learning (SSL) is an increasingly popular paradigm for representation learning. Recent methods can be classified as sample-contrastive, dimension-contrastive, or asymmetric network-based, with each family having its own approach to avoiding informational collapse. While dimension-contrastive methods converge to similar solutions as sample-contrastive methods, it can be empirically shown that some methods require more epochs of training to converge. Motivated by closing this divide, we present the objective function FroSSL which is both sample- and dimension-contrastive up to embedding normalization. FroSSL works by minimizing covariance Frobenius norms for avoiding collapse and minimizing mean-squared error for augmentation invariance. We show that FroSSL converges more quickly than a variety of other SSL methods and provide theoretical and empirical support that this faster convergence is due to how FroSSL affects the eigenvalues of the embedding covariance matrices. We also show that FroSSL learns competitive representations on linear probe evaluation when used to train a ResNet18 on the CIFAR-10, CIFAR-100, STL-10, and ImageNet datasets.
DiME: Maximizing Mutual Information by a Difference of Matrix-Based Entropies
Jan 19, 2023We introduce an information-theoretic quantity with similar properties to mutual information that can be estimated from data without making explicit assumptions on the underlying distribution. This quantity is based on a recently proposed matrix-based entropy that uses the eigenvalues of a normalized Gram matrix to compute an estimate of the eigenvalues of an uncentered covariance operator in a reproducing kernel Hilbert space. We show that a difference of matrix-based entropies (DiME) is well suited for problems involving maximization of mutual information between random variables. While many methods for such tasks can lead to trivial solutions, DiME naturally penalizes such outcomes. We provide several examples of use cases for the proposed quantity including a multi-view representation learning problem where DiME is used to encourage learning a shared representation among views with high mutual information. We also show the versatility of DiME by using it as objective function for a variety of tasks.
The Representation Jensen-Rényi Divergence
Dec 21, 2021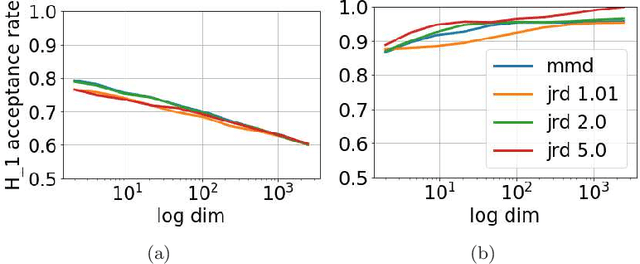

We introduce a divergence measure between data distributions based on operators in reproducing kernel Hilbert spaces defined by infinitely divisible kernels. The empirical estimator of the divergence is computed using the eigenvalues of positive definite matrices that are obtained by evaluating the kernel over pairs of samples. The new measure shares similar properties to Jensen-Shannon divergence. Convergence of the proposed estimators follows from concentration results based on the difference between the ordered spectrum of the Gram matrices and the integral operators associated with the population quantities. The proposed measure of divergence avoids the estimation of the probability distribution underlying the data. Numerical experiments involving comparing distributions and applications to sampling unbalanced data for classification show that the proposed divergence can achieve state of the art results.
Integrating Flexible Normalization into Mid-Level Representations of Deep Convolutional Neural Networks
Aug 27, 2018Deep convolutional neural networks (CNNs) are becoming increasingly popular models to predict neural responses in visual cortex. However, contextual effects, which are prevalent in neural processing and in perception, are not explicitly handled by current CNNs, including those used for neural prediction. In primary visual cortex, neural responses are modulated by stimuli spatially surrounding the classical receptive field in rich ways. These effects have been modeled with divisive normalization approaches, including flexible models where spatial normalization is recruited only to the degree responses from center and surround locations are deemed statistically dependent. We propose a flexible normalization model applied to mid-level representations of deep CNNs as a tractable way to study contextual normalization mechanisms in mid-level visual areas. This approach captures non-trivial spatial dependencies among mid-level features in CNNs, such as those present in textures and other visual stimuli that arise from tiling high order features, geometrically. We expect that the proposed approach can make predictions about when spatial normalization might be recruited in mid-level cortical areas. We also expect this approach to be useful as part of the CNN toolkit, therefore going beyond more restrictive fixed forms of normalization.
Multivariate Extension of Matrix-based Renyi's α-order Entropy Functional
Aug 23, 2018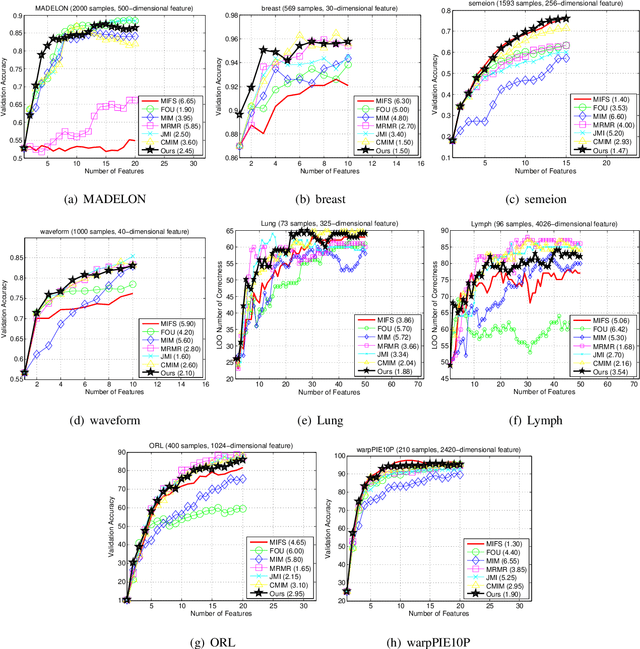

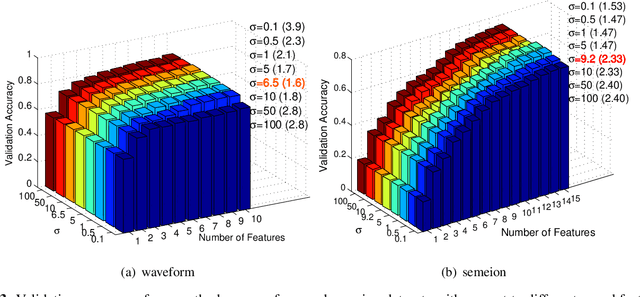

The matrix-based Renyi's {\alpha}-order entropy functional was recently introduced using the normalized eigenspectrum of an Hermitian matrix of the projected data in the reproducing kernel Hilbert space (RKHS). However, the current theory in the matrix-based Renyi's {\alpha}-order entropy functional only defines the entropy of a single variable or mutual information between two random variables. In information theory and machine learning communities, one is also frequently interested in multivariate information quantities, such as the multivariate joint entropy and different interactive quantities among multiple variables. In this paper, we first define the matrix-based Renyi's {\alpha}-order joint entropy among multiple variables. We then show how this definition can ease the estimation of various information quantities that measure the interactions among multiple variables, such as interactive information and total correlation. We finally present an application to feature selection to show how our definition provides a simple yet powerful way to estimate a widely-acknowledged intractable quantity from data. A real example on hyperspectral image (HSI) band selection is also provided.