 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiME: Maximizing Mutual Information by a Difference of Matrix-Based Entropies
Jan 19, 2023We introduce an information-theoretic quantity with similar properties to mutual information that can be estimated from data without making explicit assumptions on the underlying distribution. This quantity is based on a recently proposed matrix-based entropy that uses the eigenvalues of a normalized Gram matrix to compute an estimate of the eigenvalues of an uncentered covariance operator in a reproducing kernel Hilbert space. We show that a difference of matrix-based entropies (DiME) is well suited for problems involving maximization of mutual information between random variables. While many methods for such tasks can lead to trivial solutions, DiME naturally penalizes such outcomes. We provide several examples of use cases for the proposed quantity including a multi-view representation learning problem where DiME is used to encourage learning a shared representation among views with high mutual information. We also show the versatility of DiME by using it as objective function for a variety of tasks.
The Representation Jensen-Rényi Divergence
Dec 21, 2021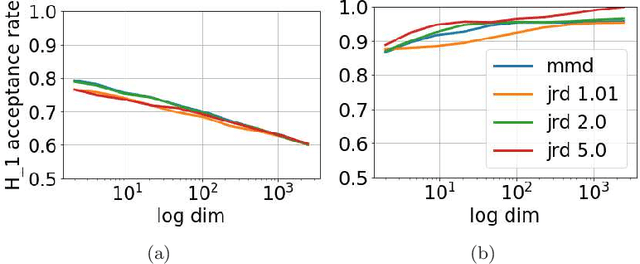

We introduce a divergence measure between data distributions based on operators in reproducing kernel Hilbert spaces defined by infinitely divisible kernels. The empirical estimator of the divergence is computed using the eigenvalues of positive definite matrices that are obtained by evaluating the kernel over pairs of samples. The new measure shares similar properties to Jensen-Shannon divergence. Convergence of the proposed estimators follows from concentration results based on the difference between the ordered spectrum of the Gram matrices and the integral operators associated with the population quantities. The proposed measure of divergence avoids the estimation of the probability distribution underlying the data. Numerical experiments involving comparing distributions and applications to sampling unbalanced data for classification show that the proposed divergence can achieve state of the art results.