 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOLD: Boolean Logic Deep Learning
May 25, 2024Deep learning is computationally intensive, with significant efforts focused on reducing arithmetic complexity, particularly regarding energy consumption dominated by data movement. While existing literature emphasizes inference, training is considerably more resource-intensive. This paper proposes a novel mathematical principle by introducing the notion of Boolean variation such that neurons made of Boolean weights and inputs can be trained -- for the first time -- efficiently in Boolean domain using Boolean logic instead of gradient descent and real arithmetic. We explore its convergence, conduct extensively experimental benchmarking, and provide consistent complexity evaluation by considering chip architecture, memory hierarchy, dataflow, and arithmetic precision. Our approach achieves baseline full-precision accuracy in ImageNet classification and surpasses state-of-the-art results in semantic segmentation, with notable performance in image super-resolution, and natural language understanding with transformer-based models. Moreover, it significantly reduces energy consumption during both training and inference.
ReALLM: A general framework for LLM compression and fine-tuning
May 21, 2024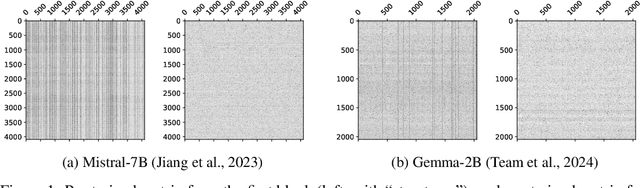
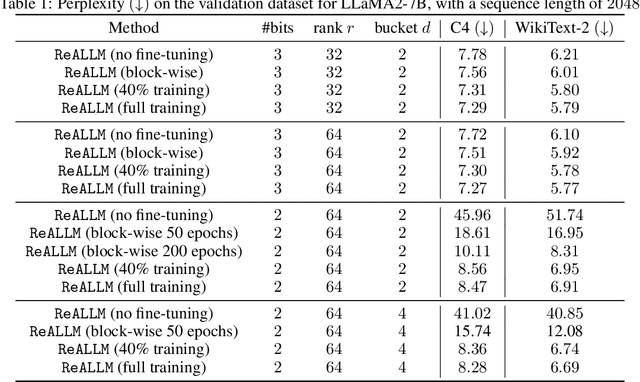
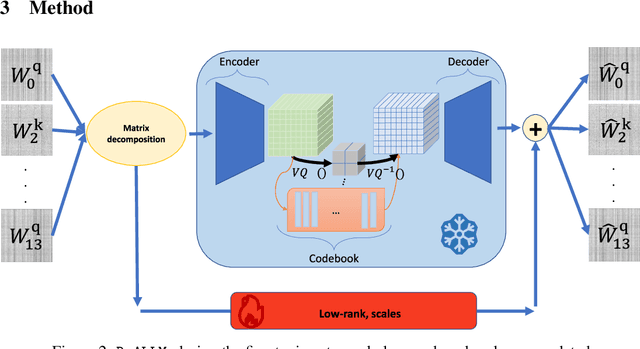
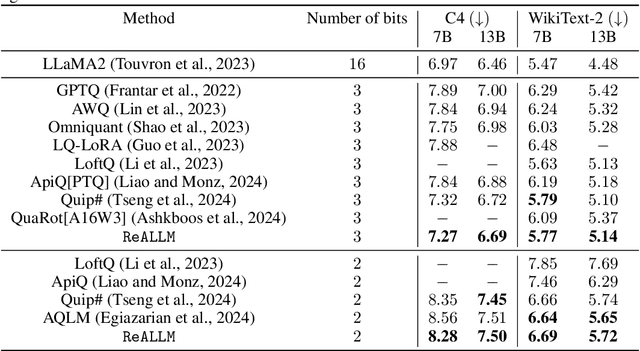
We introduce ReALLM, a novel approach for compression and memory-efficient adaptation of pre-trained language models that encompasses most of the post-training quantization and fine-tuning methods for a budget of <4 bits. Pre-trained matrices are decomposed into a high-precision low-rank component and a vector-quantized latent representation (using an autoencoder). During the fine-tuning step, only the low-rank components are updated. Our results show that pre-trained matrices exhibit different patterns. ReALLM adapts the shape of the encoder (small/large embedding, high/low bit VQ, etc.) to each matrix. ReALLM proposes to represent each matrix with a small embedding on $b$ bits and a neural decoder model $\mathcal{D}_\phi$ with its weights on $b_\phi$ bits. The decompression of a matrix requires only one embedding and a single forward pass with the decoder. Our weight-only quantization algorithm yields the best results on language generation tasks (C4 and WikiText-2) for a budget of $3$ bits without any training. With a budget of $2$ bits, ReALLM achieves state-of-the art performance after fine-tuning on a small calibration dataset.
Boolean Logic as an Error feedback mechanism
Jan 29, 2024The notion of Boolean logic backpropagation was introduced to build neural networks with weights and activations being Boolean numbers. Most of computations can be done with Boolean logic instead of real arithmetic, both during training and inference phases. But the underlying discrete optimization problem is NP-hard, and the Boolean logic has no guarantee. In this work we propose the first convergence analysis, under standard non-convex assumptions.
FAVAS: Federated AVeraging with ASynchronous clients
May 25, 2023In this paper, we propose a novel centralized Asynchronous Federated Learning (FL) framework, FAVAS, for training Deep Neural Networks (DNNs) in resource-constrained environments. Despite its popularity, ``classical'' federated learning faces the increasingly difficult task of scaling synchronous communication over large wireless networks. Moreover, clients typically have different computing resources and therefore computing speed, which can lead to a significant bias (in favor of ``fast'' clients) when the updates are asynchronous. Therefore, practical deployment of FL requires to handle users with strongly varying computing speed in communication/resource constrained setting. We provide convergence guarantees for FAVAS in a smooth, non-convex environment and carefully compare the obtained convergence guarantees with existing bounds, when they are available. Experimental results show that the FAVAS algorithm outperforms current methods on standard benchmarks.
AskewSGD : An Annealed interval-constrained Optimisation method to train Quantized Neural Networks
Nov 07, 2022



In this paper, we develop a new algorithm, Annealed Skewed SGD - AskewSGD - for training deep neural networks (DNNs) with quantized weights. First, we formulate the training of quantized neural networks (QNNs) as a smoothed sequence of interval-constrained optimization problems. Then, we propose a new first-order stochastic method, AskewSGD, to solve each constrained optimization subproblem. Unlike algorithms with active sets and feasible directions, AskewSGD avoids projections or optimization under the entire feasible set and allows iterates that are infeasible. The numerical complexity of AskewSGD is comparable to existing approaches for training QNNs, such as the straight-through gradient estimator used in BinaryConnect, or other state of the art methods (ProxQuant, LUQ). We establish convergence guarantees for AskewSGD (under general assumptions for the objective function). Experimental results show that the AskewSGD algorithm performs better than or on par with state of the art methods in classical benchmarks.
Decoupled Greedy Learning of CNNs for Synchronous and Asynchronous Distributed Learning
Jun 11, 2021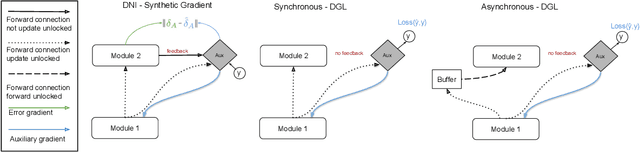
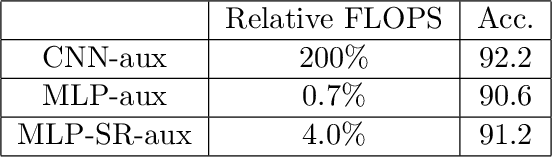
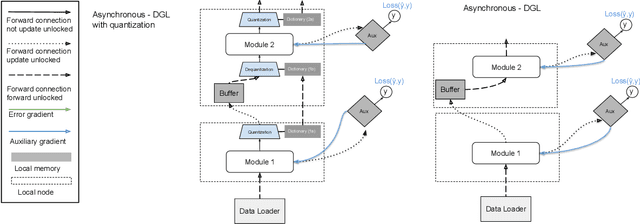

A commonly cited inefficiency of neural network training using back-propagation is the update locking problem: each layer must wait for the signal to propagate through the full network before updating. Several alternatives that can alleviate this issue have been proposed. In this context, we consider a simple alternative based on minimal feedback, which we call Decoupled Greedy Learning (DGL). It is based on a classic greedy relaxation of the joint training objective, recently shown to be effective in the context of Convolutional Neural Networks (CNNs) on large-scale image classification. We consider an optimization of this objective that permits us to decouple the layer training, allowing for layers or modules in networks to be trained with a potentially linear parallelization. With the use of a replay buffer we show that this approach can be extended to asynchronous settings, where modules can operate and continue to update with possibly large communication delays. To address bandwidth and memory issues we propose an approach based on online vector quantization. This allows to drastically reduce the communication bandwidth between modules and required memory for replay buffers. We show theoretically and empirically that this approach converges and compare it to the sequential solvers. We demonstrate the effectiveness of DGL against alternative approaches on the CIFAR-10 dataset and on the large-scale ImageNet dataset.
Interferometric Graph Transform for Community Labeling
Jun 04, 2021
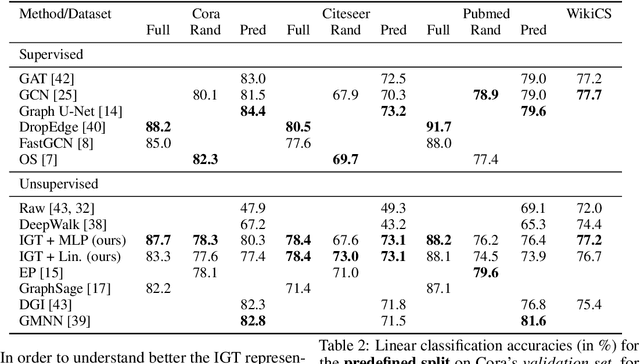

We present a new approach for learning unsupervised node representations in community graphs. We significantly extend the Interferometric Graph Transform (IGT) to community labeling: this non-linear operator iteratively extracts features that take advantage of the graph topology through demodulation operations. An unsupervised feature extraction step cascades modulus non-linearity with linear operators that aim at building relevant invariants for community labeling. Via a simplified model, we show that the IGT concentrates around the E-IGT: those two representations are related through some ergodicity properties. Experiments on community labeling tasks show that this unsupervised representation achieves performances at the level of the state of the art on the standard and challenging datasets Cora, Citeseer, Pubmed and WikiCS.