 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Diffusion Posterior Sampling with Midpoint Guidance
Oct 13, 2024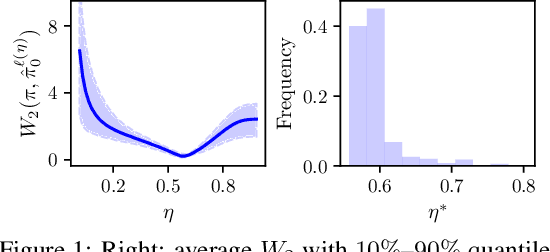
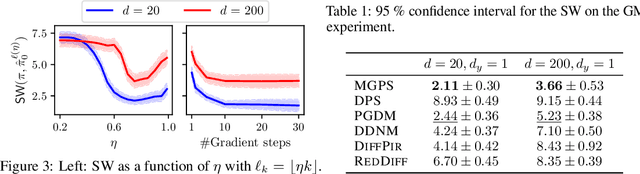

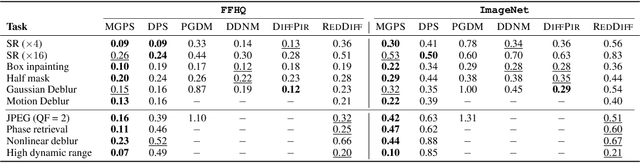
Diffusion models have recently shown considerable potential in solving Bayesian inverse problems when used as priors. However, sampling from the resulting denoising posterior distributions remains a challenge as it involves intractable terms. To tackle this issue, state-of-the-art approaches formulate the problem as that of sampling from a surrogate diffusion model targeting the posterior and decompose its scores into two terms: the prior score and an intractable guidance term. While the former is replaced by the pre-trained score of the considered diffusion model, the guidance term has to be estimated. In this paper, we propose a novel approach that utilises a decomposition of the transitions which, in contrast to previous methods, allows a trade-off between the complexity of the intractable guidance term and that of the prior transitions. We validate the proposed approach through extensive experiments on linear and nonlinear inverse problems, including challenging cases with latent diffusion models as priors, and demonstrate its effectiveness in reconstructing electrocardiogram (ECG) from partial measurements for accurate cardiac diagnosis.
ReALLM: A general framework for LLM compression and fine-tuning
May 21, 2024
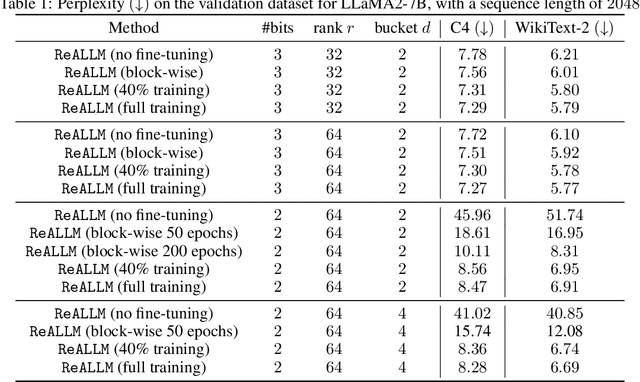
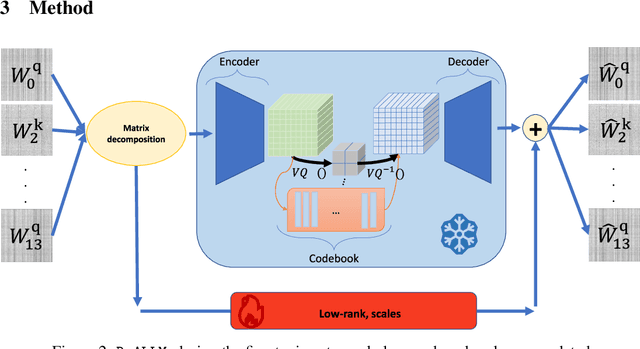
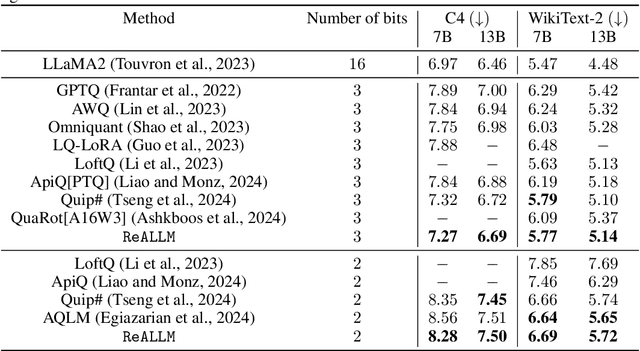
We introduce ReALLM, a novel approach for compression and memory-efficient adaptation of pre-trained language models that encompasses most of the post-training quantization and fine-tuning methods for a budget of <4 bits. Pre-trained matrices are decomposed into a high-precision low-rank component and a vector-quantized latent representation (using an autoencoder). During the fine-tuning step, only the low-rank components are updated. Our results show that pre-trained matrices exhibit different patterns. ReALLM adapts the shape of the encoder (small/large embedding, high/low bit VQ, etc.) to each matrix. ReALLM proposes to represent each matrix with a small embedding on $b$ bits and a neural decoder model $\mathcal{D}_\phi$ with its weights on $b_\phi$ bits. The decompression of a matrix requires only one embedding and a single forward pass with the decoder. Our weight-only quantization algorithm yields the best results on language generation tasks (C4 and WikiText-2) for a budget of $3$ bits without any training. With a budget of $2$ bits, ReALLM achieves state-of-the art performance after fine-tuning on a small calibration dataset.