 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneously Updating All Persistence Values in Reinforcement Learning
Nov 21, 2022In reinforcement learning, the performance of learning agents is highly sensitive to the choice of time discretization. Agents acting at high frequencies have the best control opportunities, along with some drawbacks, such as possible inefficient exploration and vanishing of the action advantages. The repetition of the actions, i.e., action persistence, comes into help, as it allows the agent to visit wider regions of the state space and improve the estimation of the action effects. In this work, we derive a novel All-Persistence Bellman Operator, which allows an effective use of both the low-persistence experience, by decomposition into sub-transition, and the high-persistence experience, thanks to the introduction of a suitable bootstrap procedure. In this way, we employ transitions collected at any time scale to update simultaneously the action values of the considered persistence set. We prove the contraction property of the All-Persistence Bellman Operator and, based on it, we extend classic Q-learning and DQN. After providing a study on the effects of persistence, we experimentally evaluate our approach in both tabular contexts and more challenging frameworks, including some Atari games.
Delayed Reinforcement Learning by Imitation
May 11, 2022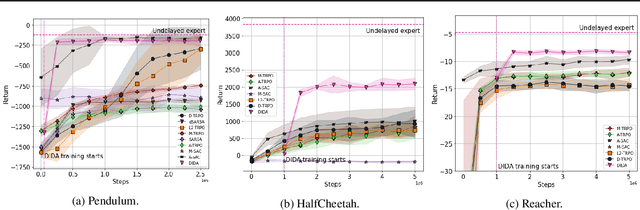

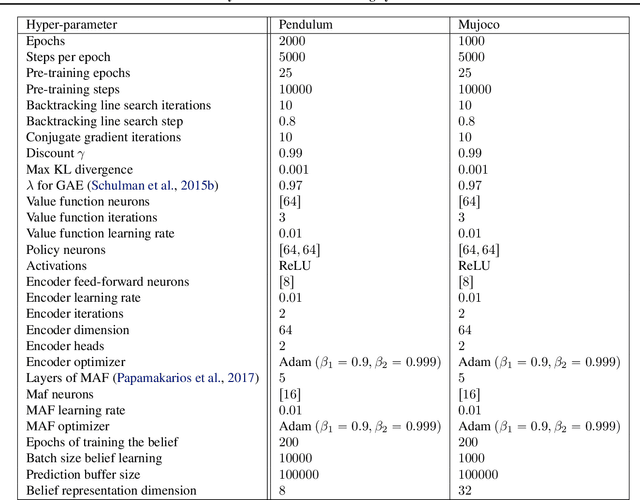
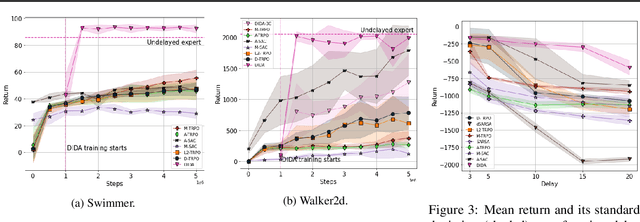
When the agent's observations or interactions are delayed, classic reinforcement learning tools usually fail. In this paper, we propose a simple yet new and efficient solution to this problem. We assume that, in the undelayed environment, an efficient policy is known or can be easily learned, but the task may suffer from delays in practice and we thus want to take them into account. We present a novel algorithm, Delayed Imitation with Dataset Aggregation (DIDA), which builds upon imitation learning methods to learn how to act in a delayed environment from undelayed demonstrations. We provide a theoretical analysis of the approach that will guide the practical design of DIDA. These results are also of general interest in the delayed reinforcement learning literature by providing bounds on the performance between delayed and undelayed tasks, under smoothness conditions. We show empirically that DIDA obtains high performances with a remarkable sample efficiency on a variety of tasks, including robotic locomotion, classic control, and trading.
Control Frequency Adaptation via Action Persistence in Batch Reinforcement Learning
Feb 17, 2020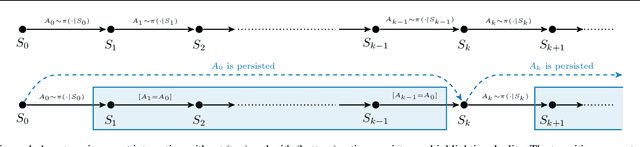
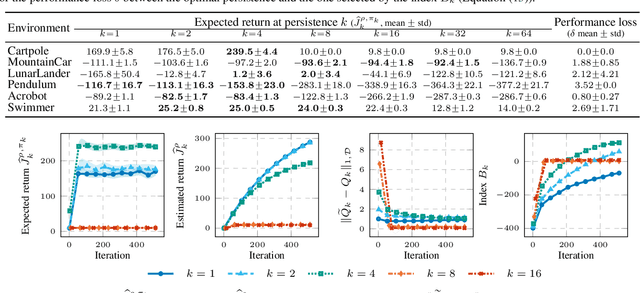

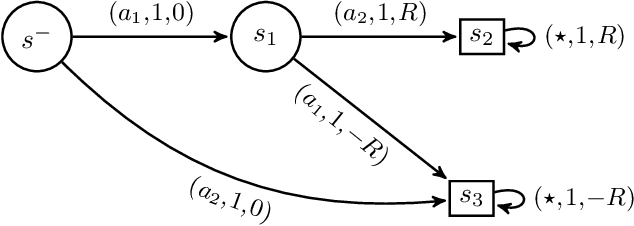
The choice of the control frequency of a system has a relevant impact on the ability of reinforcement learning algorithms to learn a highly performing policy. In this paper, we introduce the notion of action persistence that consists in the repetition of an action for a fixed number of decision steps, having the effect of modifying the control frequency. We start analyzing how action persistence affects the performance of the optimal policy, and then we present a novel algorithm, Persistent Fitted Q-Iteration (PFQI), that extends FQI, with the goal of learning the optimal value function at a given persistence. After having provided a theoretical study of PFQI and a heuristic approach to identify the optimal persistence, we present an experimental campaign on benchmark domains to show the advantages of action persistence and proving the effectiveness of our persistence selection method.
Risk-Averse Trust Region Optimization for Reward-Volatility Reduction
Dec 06, 2019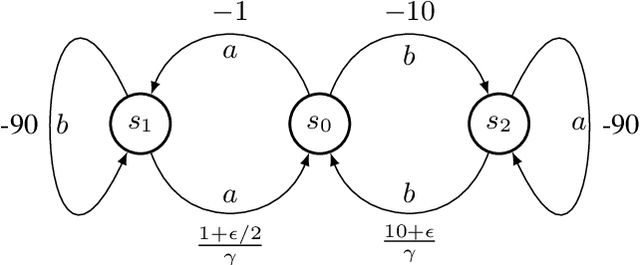
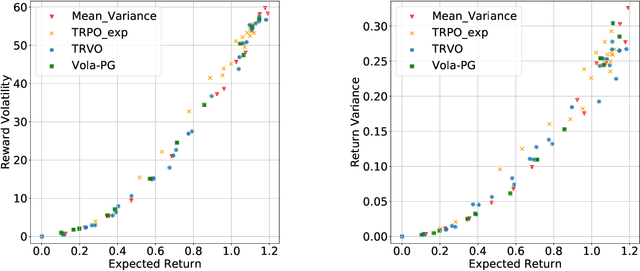
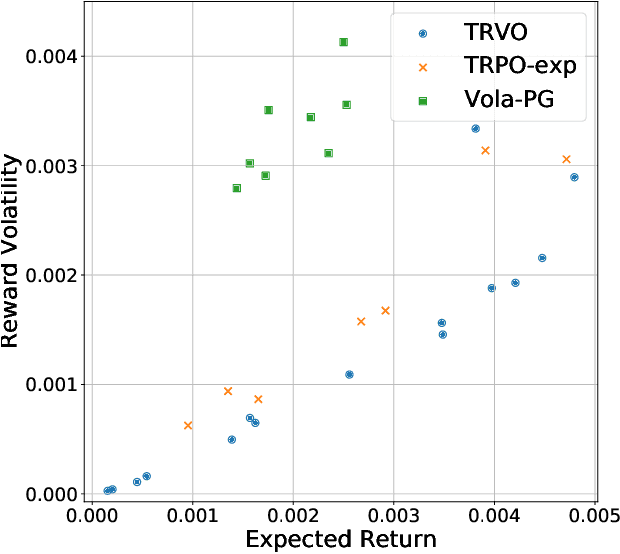
In real-world decision-making problems, for instance in the fields of finance, robotics or autonomous driving, keeping uncertainty under control is as important as maximizing expected returns. Risk aversion has been addressed in the reinforcement learning literature through risk measures related to the variance of returns. However, in many cases, the risk is measured not only on a long-term perspective, but also on the step-wise rewards (e.g., in trading, to ensure the stability of the investment bank, it is essential to monitor the risk of portfolio positions on a daily basis). In this paper, we define a novel measure of risk, which we call reward volatility, consisting of the variance of the rewards under the state-occupancy measure. We show that the reward volatility bounds the return variance so that reducing the former also constrains the latter. We derive a policy gradient theorem with a new objective function that exploits the mean-volatility relationship, and develop an actor-only algorithm. Furthermore, thanks to the linearity of the Bellman equations defined under the new objective function, it is possible to adapt the well-known policy gradient algorithms with monotonic improvement guarantees such as TRPO in a risk-averse manner. Finally, we test the proposed approach in two simulated financial environments.