 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelays in Reinforcement Learning
Sep 20, 2023Delays are inherent to most dynamical systems. Besides shifting the process in time, they can significantly affect their performance. For this reason, it is usually valuable to study the delay and account for it. Because they are dynamical systems, it is of no surprise that sequential decision-making problems such as Markov decision processes (MDP) can also be affected by delays. These processes are the foundational framework of reinforcement learning (RL), a paradigm whose goal is to create artificial agents capable of learning to maximise their utility by interacting with their environment. RL has achieved strong, sometimes astonishing, empirical results, but delays are seldom explicitly accounted for. The understanding of the impact of delay on the MDP is limited. In this dissertation, we propose to study the delay in the agent's observation of the state of the environment or in the execution of the agent's actions. We will repeatedly change our point of view on the problem to reveal some of its structure and peculiarities. A wide spectrum of delays will be considered, and potential solutions will be presented. This dissertation also aims to draw links between celebrated frameworks of the RL literature and the one of delays.
Delayed Reinforcement Learning by Imitation
May 11, 2022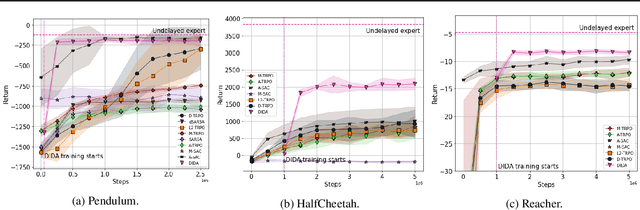

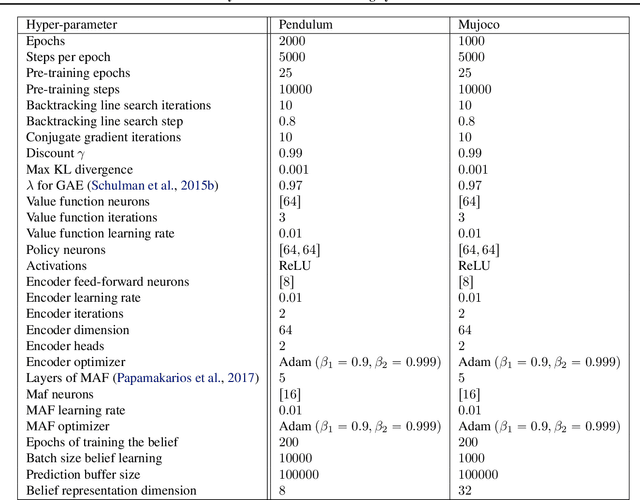
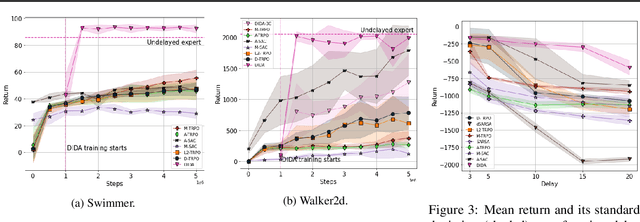
When the agent's observations or interactions are delayed, classic reinforcement learning tools usually fail. In this paper, we propose a simple yet new and efficient solution to this problem. We assume that, in the undelayed environment, an efficient policy is known or can be easily learned, but the task may suffer from delays in practice and we thus want to take them into account. We present a novel algorithm, Delayed Imitation with Dataset Aggregation (DIDA), which builds upon imitation learning methods to learn how to act in a delayed environment from undelayed demonstrations. We provide a theoretical analysis of the approach that will guide the practical design of DIDA. These results are also of general interest in the delayed reinforcement learning literature by providing bounds on the performance between delayed and undelayed tasks, under smoothness conditions. We show empirically that DIDA obtains high performances with a remarkable sample efficiency on a variety of tasks, including robotic locomotion, classic control, and trading.
Lifelong Hyper-Policy Optimization with Multiple Importance Sampling Regularization
Dec 13, 2021



Learning in a lifelong setting, where the dynamics continually evolve, is a hard challenge for current reinforcement learning algorithms. Yet this would be a much needed feature for practical applications. In this paper, we propose an approach which learns a hyper-policy, whose input is time, that outputs the parameters of the policy to be queried at that time. This hyper-policy is trained to maximize the estimated future performance, efficiently reusing past data by means of importance sampling, at the cost of introducing a controlled bias. We combine the future performance estimate with the past performance to mitigate catastrophic forgetting. To avoid overfitting the collected data, we derive a differentiable variance bound that we embed as a penalization term. Finally, we empirically validate our approach, in comparison with state-of-the-art algorithms, on realistic environments, including water resource management and trading.