 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaired Completion: Flexible Quantification of Issue-framing at Scale with LLMs
Aug 19, 2024



Detecting and quantifying issue framing in textual discourse - the perspective one takes to a given topic (e.g. climate science vs. denialism, misogyny vs. gender equality) - is highly valuable to a range of end-users from social and political scientists to program evaluators and policy analysts. However, conceptual framing is notoriously challenging for automated natural language processing (NLP) methods since the words and phrases used by either `side' of an issue are often held in common, with only subtle stylistic flourishes separating their use. Here we develop and rigorously evaluate new detection methods for issue framing and narrative analysis within large text datasets. By introducing a novel application of next-token log probabilities derived from generative large language models (LLMs) we show that issue framing can be reliably and efficiently detected in large corpora with only a few examples of either perspective on a given issue, a method we call `paired completion'. Through 192 independent experiments over three novel, synthetic datasets, we evaluate paired completion against prompt-based LLM methods and labelled methods using traditional NLP and recent LLM contextual embeddings. We additionally conduct a cost-based analysis to mark out the feasible set of performant methods at production-level scales, and a model bias analysis. Together, our work demonstrates a feasible path to scalable, accurate and low-bias issue-framing in large corpora.
Creating Powerful and Interpretable Models withRegression Networks
Jul 30, 2021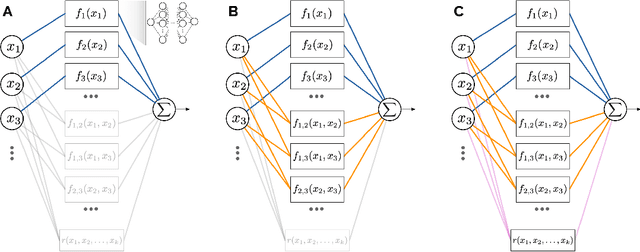

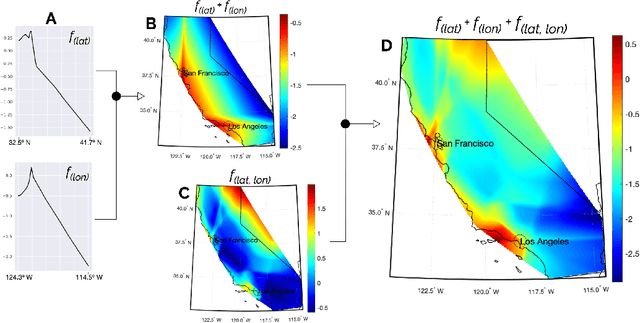
As the discipline has evolved, research in machine learning has been focused more and more on creating more powerful neural networks, without regard for the interpretability of these networks. Such "black-box models" yield state-of-the-art results, but we cannot understand why they make a particular decision or prediction. Sometimes this is acceptable, but often it is not. We propose a novel architecture, Regression Networks, which combines the power of neural networks with the understandability of regression analysis. While some methods for combining these exist in the literature, our architecture generalizes these approaches by taking interactions into account, offering the power of a dense neural network without forsaking interpretability. We demonstrate that the models exceed the state-of-the-art performance of interpretable models on several benchmark datasets, matching the power of a dense neural network. Finally, we discuss how these techniques can be generalized to other neural architectures, such as convolutional and recurrent neural networks.
Proximity Forest: An effective and scalable distance-based classifier for time series
Aug 31, 2018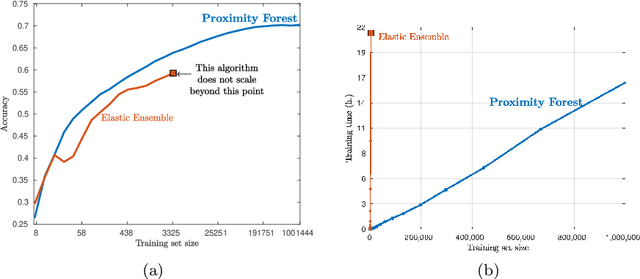
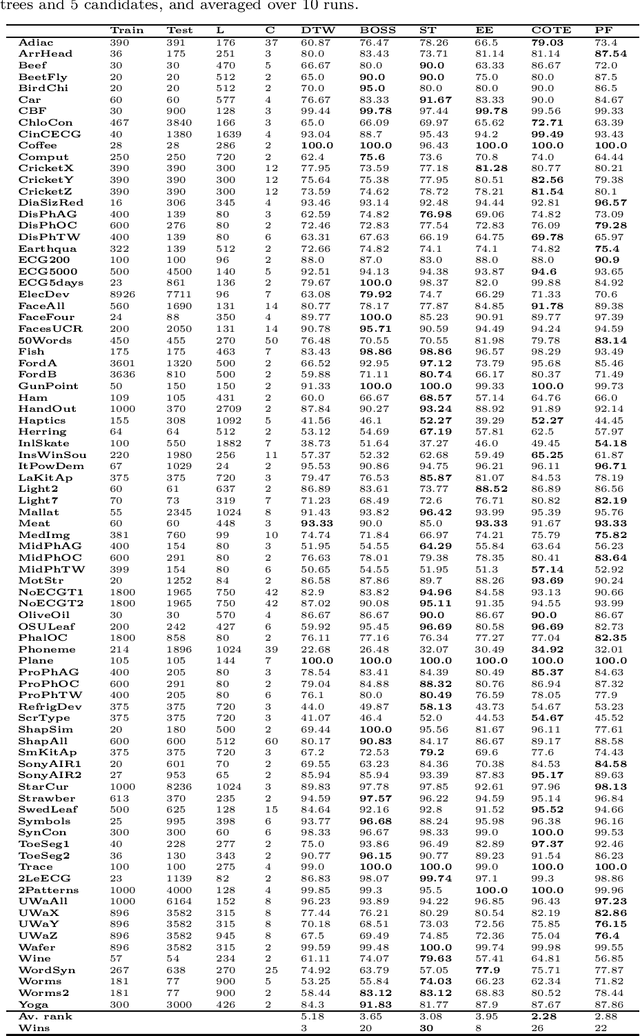
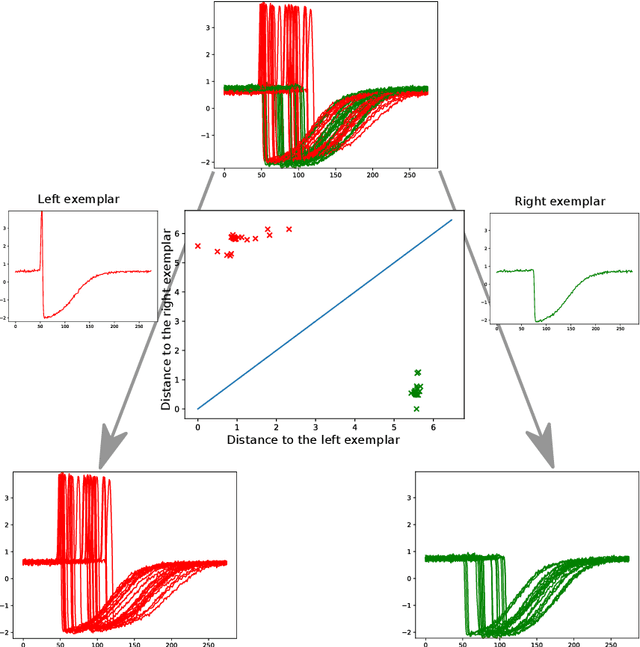
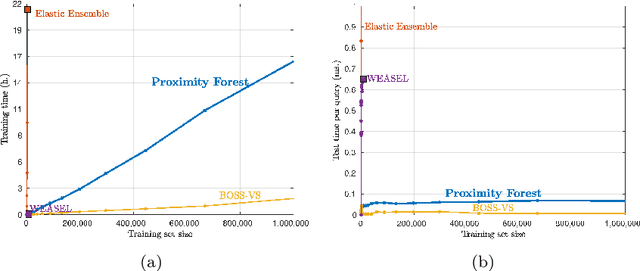
Research into the classification of time series has made enormous progress in the last decade. The UCR time series archive has played a significant role in challenging and guiding the development of new learners for time series classification. The largest dataset in the UCR archive holds 10 thousand time series only; which may explain why the primary research focus has been in creating algorithms that have high accuracy on relatively small datasets. This paper introduces Proximity Forest, an algorithm that learns accurate models from datasets with millions of time series, and classifies a time series in milliseconds. The models are ensembles of highly randomized Proximity Trees. Whereas conventional decision trees branch on attribute values (and usually perform poorly on time series), Proximity Trees branch on the proximity of time series to one exemplar time series or another; allowing us to leverage the decades of work into developing relevant measures for time series. Proximity Forest gains both efficiency and accuracy by stochastic selection of both exemplars and similarity measures. Our work is motivated by recent time series applications that provide orders of magnitude more time series than the UCR benchmarks. Our experiments demonstrate that Proximity Forest is highly competitive on the UCR archive: it ranks among the most accurate classifiers while being significantly faster. We demonstrate on a 1M time series Earth observation dataset that Proximity Forest retains this accuracy on datasets that are many orders of magnitude greater than those in the UCR repository, while learning its models at least 100,000 times faster than current state of the art models Elastic Ensemble and COTE.