 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Physician Disagreement in HealthBench
Feb 26, 2026We decompose physician disagreement in the HealthBench medical AI evaluation dataset to understand where variance resides and what observable features can explain it. Rubric identity accounts for 15.8% of met/not-met label variance but only 3.6-6.9% of disagreement variance; physician identity accounts for just 2.4%. The dominant 81.8% case-level residual is not reduced by HealthBench's metadata labels (z = -0.22, p = 0.83), normative rubric language (pseudo R^2 = 1.2%), medical specialty (0/300 Tukey pairs significant), surface-feature triage (AUC = 0.58), or embeddings (AUC = 0.485). Disagreement follows an inverted-U with completion quality (AUC = 0.689), confirming physicians agree on clearly good or bad outputs but split on borderline cases. Physician-validated uncertainty categories reveal that reducible uncertainty (missing context, ambiguous phrasing) more than doubles disagreement odds (OR = 2.55, p < 10^(-24)), while irreducible uncertainty (genuine medical ambiguity) has no effect (OR = 1.01, p = 0.90), though even the former explains only ~3% of total variance. The agreement ceiling in medical AI evaluation is thus largely structural, but the reducible/irreducible dissociation suggests that closing information gaps in evaluation scenarios could lower disagreement where inherent clinical ambiguity does not, pointing toward actionable evaluation design improvements.
Bayesian Neural Network Versus Ex-Post Calibration For Prediction Uncertainty
Sep 29, 2022
Probabilistic predictions from neural networks which account for predictive uncertainty during classification is crucial in many real-world and high-impact decision making settings. However, in practice most datasets are trained on non-probabilistic neural networks which by default do not capture this inherent uncertainty. This well-known problem has led to the development of post-hoc calibration procedures, such as Platt scaling (logistic), isotonic and beta calibration, which transforms the scores into well calibrated empirical probabilities. A plausible alternative to the calibration approach is to use Bayesian neural networks, which directly models a predictive distribution. Although they have been applied to images and text datasets, they have seen limited adoption in the tabular and small data regime. In this paper, we demonstrate that Bayesian neural networks yields competitive performance when compared to calibrated neural networks and conduct experiments across a wide array of datasets.
Creating Powerful and Interpretable Models withRegression Networks
Jul 30, 2021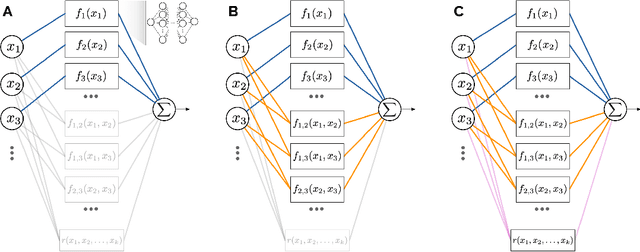

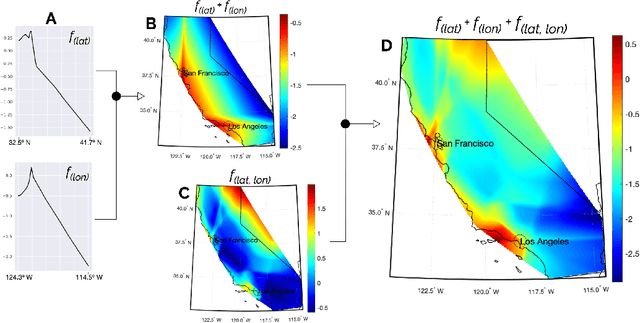
As the discipline has evolved, research in machine learning has been focused more and more on creating more powerful neural networks, without regard for the interpretability of these networks. Such "black-box models" yield state-of-the-art results, but we cannot understand why they make a particular decision or prediction. Sometimes this is acceptable, but often it is not. We propose a novel architecture, Regression Networks, which combines the power of neural networks with the understandability of regression analysis. While some methods for combining these exist in the literature, our architecture generalizes these approaches by taking interactions into account, offering the power of a dense neural network without forsaking interpretability. We demonstrate that the models exceed the state-of-the-art performance of interpretable models on several benchmark datasets, matching the power of a dense neural network. Finally, we discuss how these techniques can be generalized to other neural architectures, such as convolutional and recurrent neural networks.