 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaired Completion: Flexible Quantification of Issue-framing at Scale with LLMs
Aug 19, 2024



Detecting and quantifying issue framing in textual discourse - the perspective one takes to a given topic (e.g. climate science vs. denialism, misogyny vs. gender equality) - is highly valuable to a range of end-users from social and political scientists to program evaluators and policy analysts. However, conceptual framing is notoriously challenging for automated natural language processing (NLP) methods since the words and phrases used by either `side' of an issue are often held in common, with only subtle stylistic flourishes separating their use. Here we develop and rigorously evaluate new detection methods for issue framing and narrative analysis within large text datasets. By introducing a novel application of next-token log probabilities derived from generative large language models (LLMs) we show that issue framing can be reliably and efficiently detected in large corpora with only a few examples of either perspective on a given issue, a method we call `paired completion'. Through 192 independent experiments over three novel, synthetic datasets, we evaluate paired completion against prompt-based LLM methods and labelled methods using traditional NLP and recent LLM contextual embeddings. We additionally conduct a cost-based analysis to mark out the feasible set of performant methods at production-level scales, and a model bias analysis. Together, our work demonstrates a feasible path to scalable, accurate and low-bias issue-framing in large corpora.
The Internet as Quantitative Social Science Platform: Insights from a Trillion Observations
Jan 19, 2017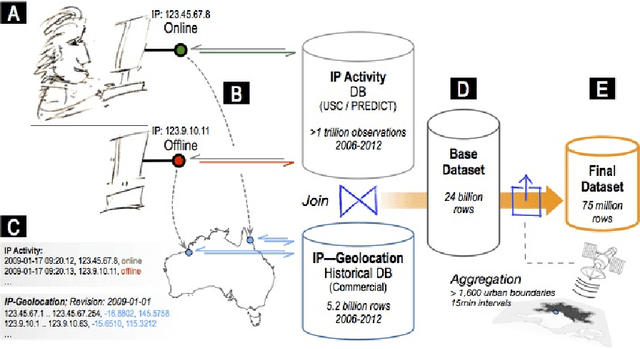
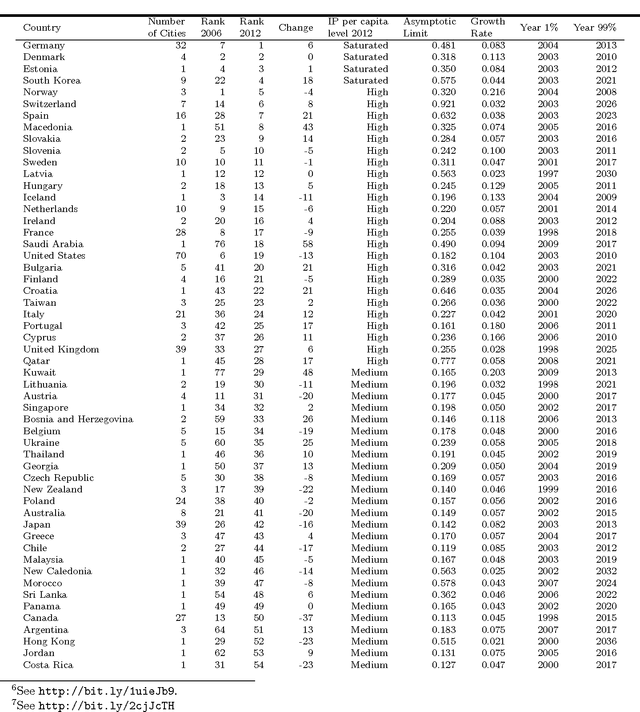

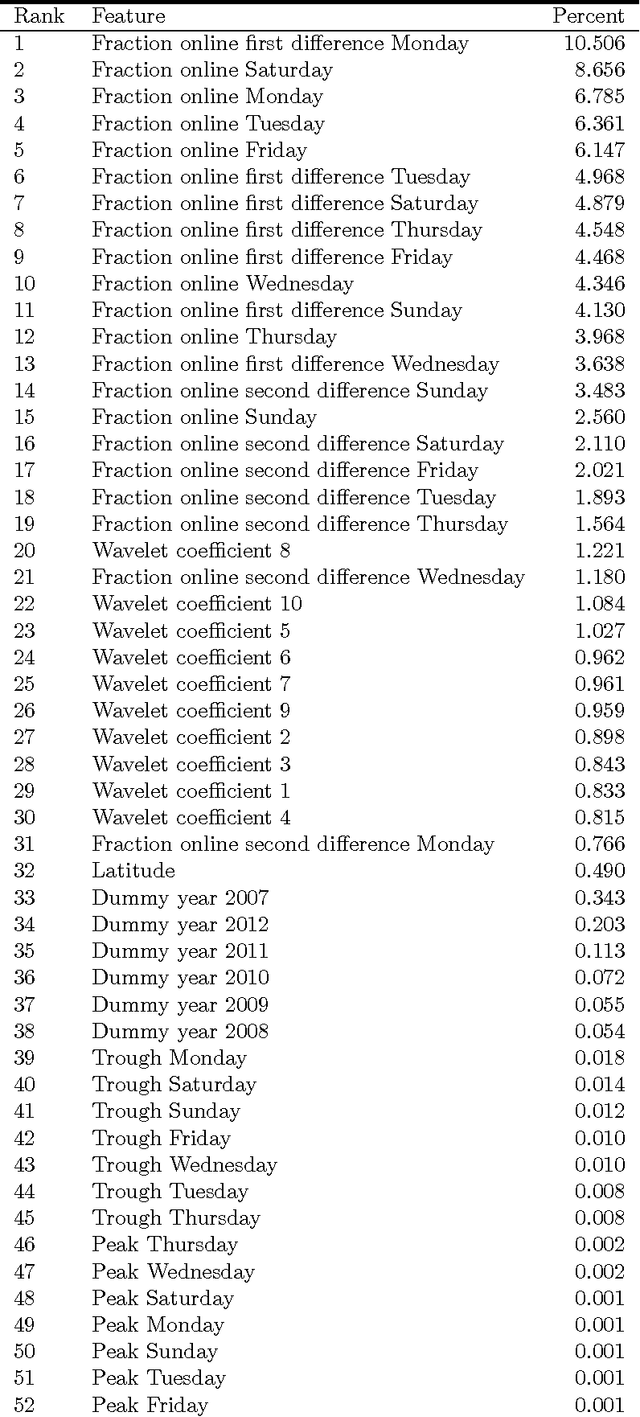
With the large-scale penetration of the internet, for the first time, humanity has become linked by a single, open, communications platform. Harnessing this fact, we report insights arising from a unified internet activity and location dataset of an unparalleled scope and accuracy drawn from over a trillion (1.5$\times 10^{12}$) observations of end-user internet connections, with temporal resolution of just 15min over 2006-2012. We first apply this dataset to the expansion of the internet itself over 1,647 urban agglomerations globally. We find that unique IP per capita counts reach saturation at approximately one IP per three people, and take, on average, 16.1 years to achieve; eclipsing the estimated 100- and 60- year saturation times for steam-power and electrification respectively. Next, we use intra-diurnal internet activity features to up-scale traditional over-night sleep observations, producing the first global estimate of over-night sleep duration in 645 cities over 7 years. We find statistically significant variation between continental, national and regional sleep durations including some evidence of global sleep duration convergence. Finally, we estimate the relationship between internet concentration and economic outcomes in 411 OECD regions and find that the internet's expansion is associated with negative or positive productivity gains, depending strongly on sectoral considerations. To our knowledge, our study is the first of its kind to use online/offline activity of the entire internet to infer social science insights, demonstrating the unparalleled potential of the internet as a social data-science platform.