 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-Splitting Multiple Access for 6G Networks: Ten Promising Scenarios and Applications
Jun 22, 2023



In the upcoming 6G era, multiple access (MA) will play an essential role in achieving high throughput performances required in a wide range of wireless applications. Since MA and interference management are closely related issues, the conventional MA techniques are limited in that they cannot provide near-optimal performance in universal interference regimes. Recently, rate-splitting multiple access (RSMA) has been gaining much attention. RSMA splits an individual message into two parts: a common part, decodable by every user, and a private part, decodable only by the intended user. Each user first decodes the common message and then decodes its private message by applying successive interference cancellation (SIC). By doing so, RSMA not only embraces the existing MA techniques as special cases but also provides significant performance gains by efficiently mitigating inter-user interference in a broad range of interference regimes. In this article, we first present the theoretical foundation of RSMA. Subsequently, we put forth four key benefits of RSMA: spectral efficiency, robustness, scalability, and flexibility. Upon this, we describe how RSMA can enable ten promising scenarios and applications along with future research directions to pave the way for 6G.
Resolution of Unidentified Words in Machine Translation
Jul 28, 2010

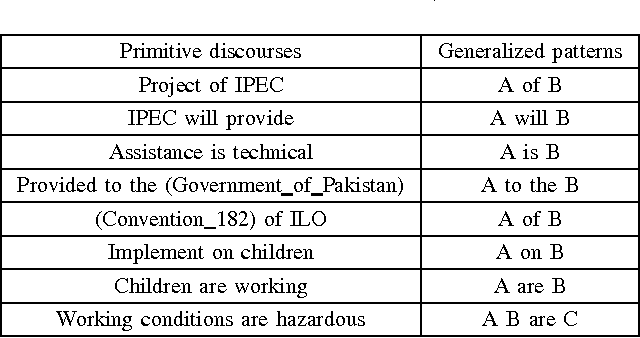
This paper presents a mechanism of resolving unidentified lexical units in Text-based Machine Translation (TBMT). In a Machine Translation (MT) system it is unlikely to have a complete lexicon and hence there is intense need of a new mechanism to handle the problem of unidentified words. These unknown words could be abbreviations, names, acronyms and newly introduced terms. We have proposed an algorithm for the resolution of the unidentified words. This algorithm takes discourse unit (primitive discourse) as a unit of analysis and provides real time updates to the lexicon. We have manually applied the algorithm to news paper fragments. Along with anaphora and cataphora resolution, many unknown words especially names and abbreviations were updated to the lexicon.
A Discourse-based Approach in Text-based Machine Translation
Jul 28, 2010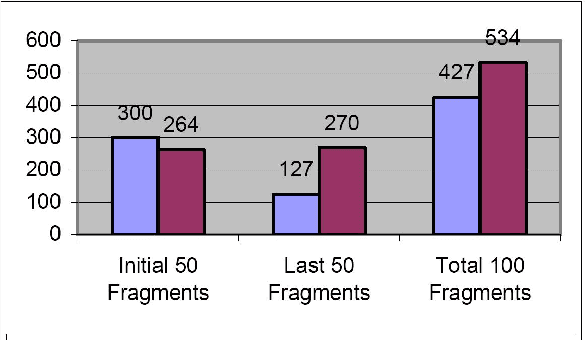
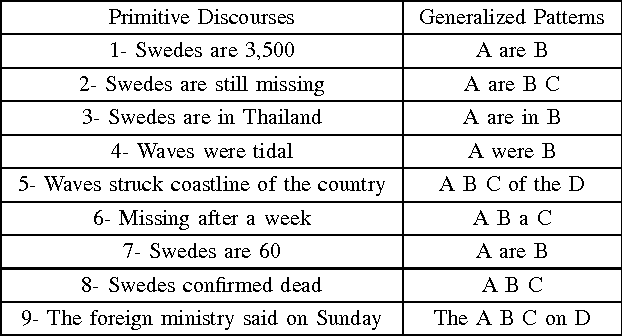
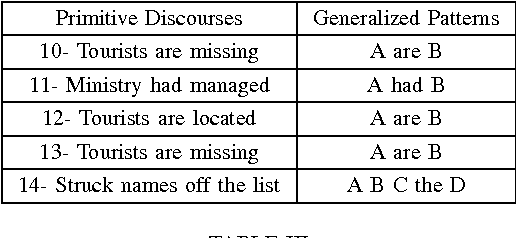

This paper presents a theoretical research based approach to ellipsis resolution in machine translation. The formula of discourse is applied in order to resolve ellipses. The validity of the discourse formula is analyzed by applying it to the real world text, i.e., newspaper fragments. The source text is converted into mono-sentential discourses where complex discourses require further dissection either directly into primitive discourses or first into compound discourses and later into primitive ones. The procedure of dissection needs further improvement, i.e., discovering as many primitive discourse forms as possible. An attempt has been made to investigate new primitive discourses or patterns from the given text.