 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolution of Unidentified Words in Machine Translation
Jul 28, 2010

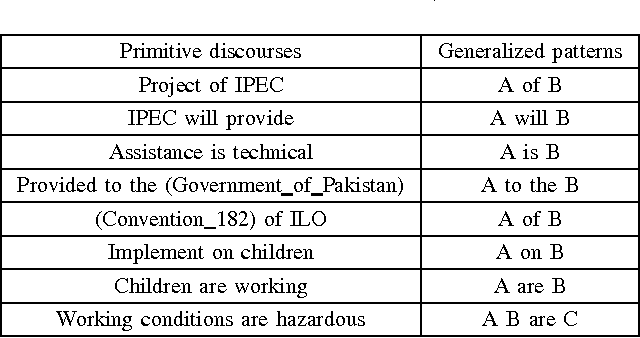
This paper presents a mechanism of resolving unidentified lexical units in Text-based Machine Translation (TBMT). In a Machine Translation (MT) system it is unlikely to have a complete lexicon and hence there is intense need of a new mechanism to handle the problem of unidentified words. These unknown words could be abbreviations, names, acronyms and newly introduced terms. We have proposed an algorithm for the resolution of the unidentified words. This algorithm takes discourse unit (primitive discourse) as a unit of analysis and provides real time updates to the lexicon. We have manually applied the algorithm to news paper fragments. Along with anaphora and cataphora resolution, many unknown words especially names and abbreviations were updated to the lexicon.