Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Discourse-based Approach in Text-based Machine Translation
Paper and Code
Jul 28, 2010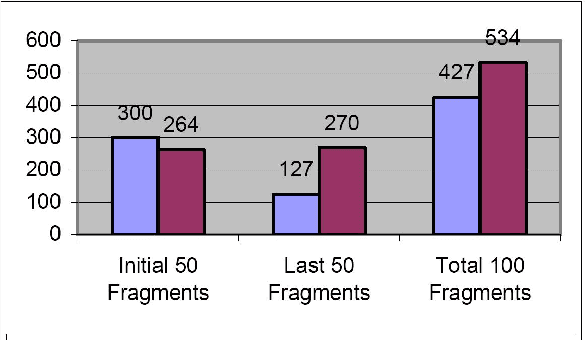
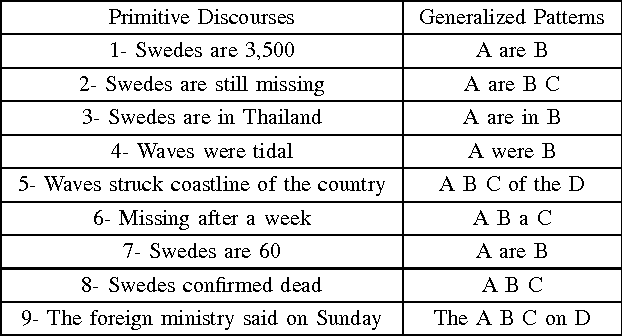
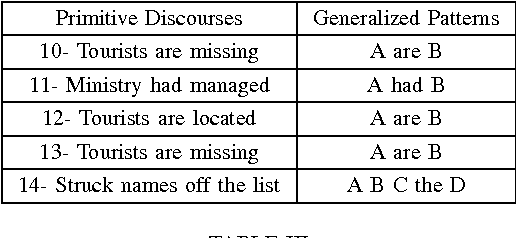

This paper presents a theoretical research based approach to ellipsis resolution in machine translation. The formula of discourse is applied in order to resolve ellipses. The validity of the discourse formula is analyzed by applying it to the real world text, i.e., newspaper fragments. The source text is converted into mono-sentential discourses where complex discourses require further dissection either directly into primitive discourses or first into compound discourses and later into primitive ones. The procedure of dissection needs further improvement, i.e., discovering as many primitive discourse forms as possible. An attempt has been made to investigate new primitive discourses or patterns from the given text.
* 1 figure, 3 tables, ICCIT 07, Vol. 3, pp 1073-1074, Busan, June 2007
View paper on