 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Impact of Observation Space Design Choices On Training Reinforcement Learning Solutions for Spacecraft Problems
Jan 10, 2025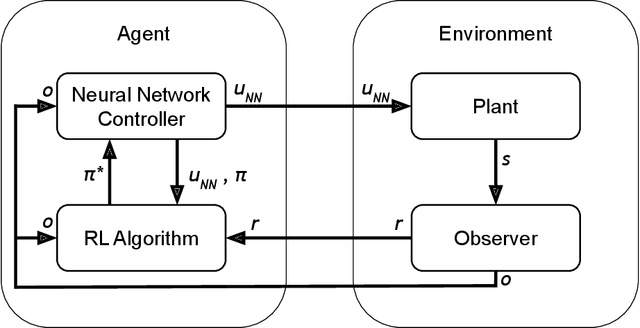
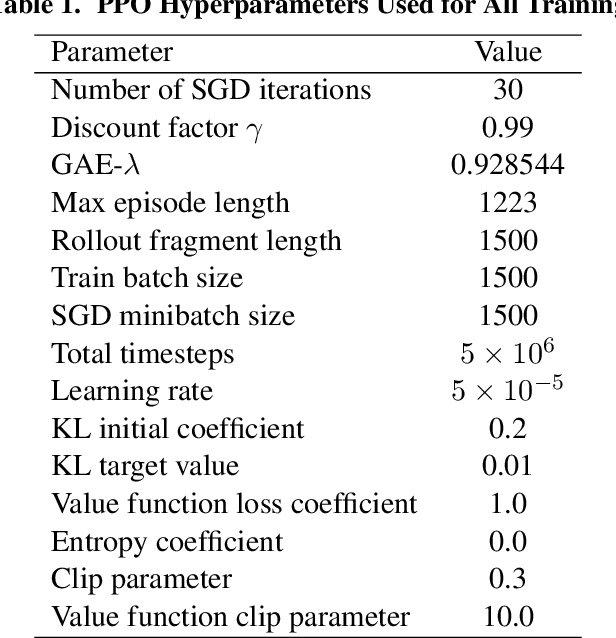
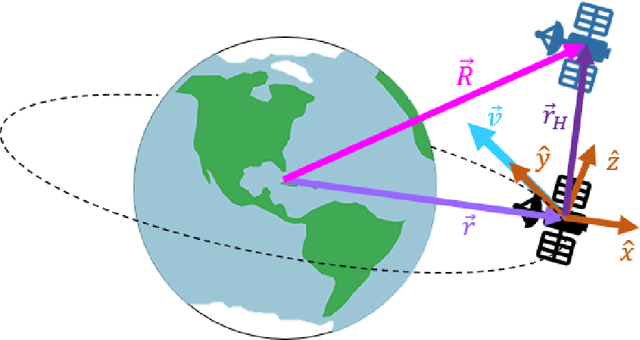
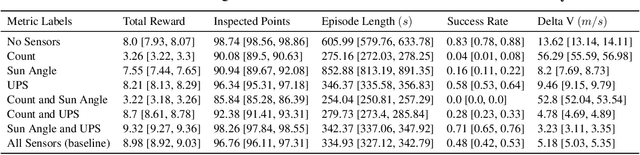
Recent research using Reinforcement Learning (RL) to learn autonomous control for spacecraft operations has shown great success. However, a recent study showed their performance could be improved by changing the action space, i.e. control outputs, used in the learning environment. This has opened the door for finding more improvements through further changes to the environment. The work in this paper focuses on how changes to the environment's observation space can impact the training and performance of RL agents learning the spacecraft inspection task. The studies are split into two groups. The first looks at the impact of sensors that were designed to help agents learn the task. The second looks at the impact of reference frames, reorienting the agent to see the world from a different perspective. The results show the sensors are not necessary, but most of them help agents learn more optimal behavior, and that the reference frame does not have a large impact, but is best kept consistent.
Investigating the Impact of Choice on Deep Reinforcement Learning for Space Controls
May 20, 2024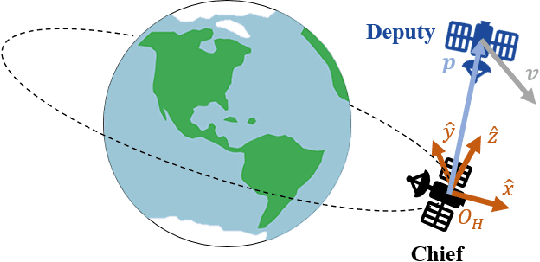
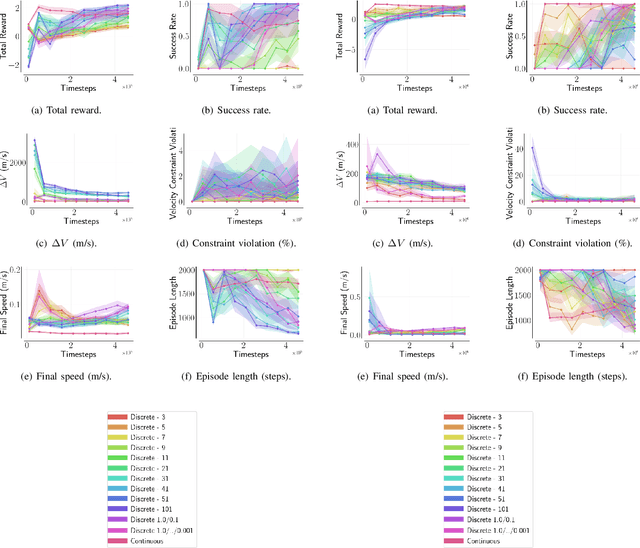
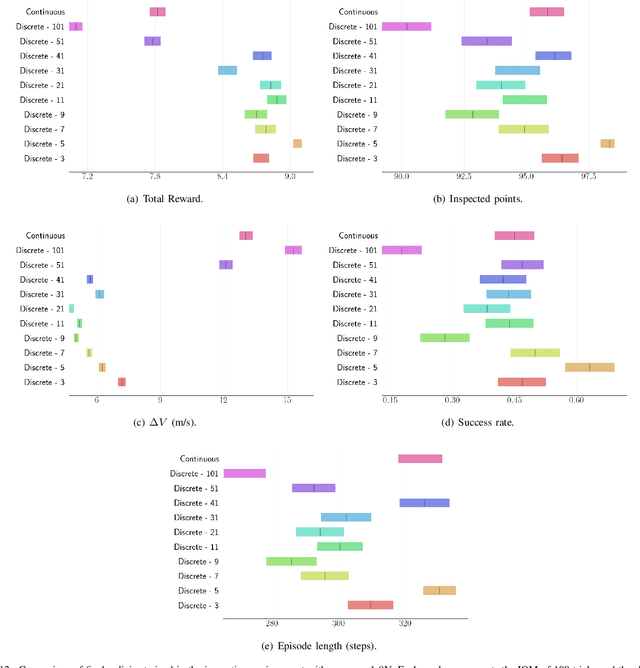
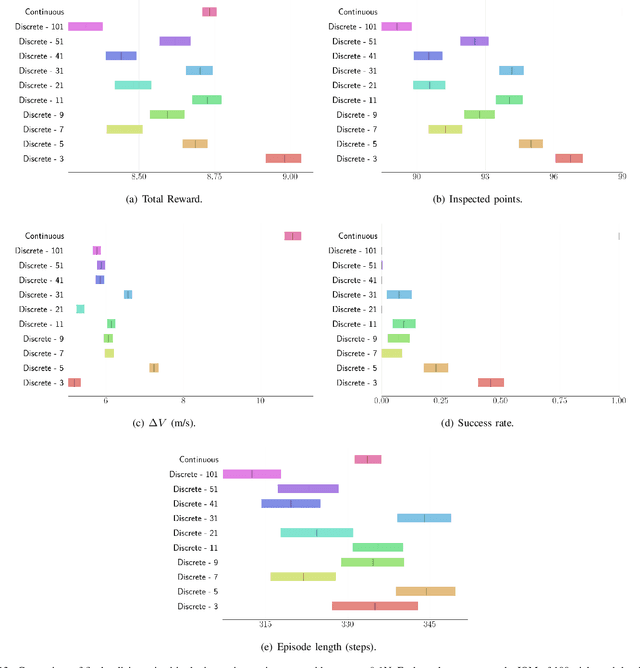
For many space applications, traditional control methods are often used during operation. However, as the number of space assets continues to grow, autonomous operation can enable rapid development of control methods for different space related tasks. One method of developing autonomous control is Reinforcement Learning (RL), which has become increasingly popular after demonstrating promising performance and success across many complex tasks. While it is common for RL agents to learn bounded continuous control values, this may not be realistic or practical for many space tasks that traditionally prefer an on/off approach for control. This paper analyzes using discrete action spaces, where the agent must choose from a predefined list of actions. The experiments explore how the number of choices provided to the agents affects their measured performance during and after training. This analysis is conducted for an inspection task, where the agent must circumnavigate an object to inspect points on its surface, and a docking task, where the agent must move into proximity of another spacecraft and "dock" with a low relative speed. A common objective of both tasks, and most space tasks in general, is to minimize fuel usage, which motivates the agent to regularly choose an action that uses no fuel. Our results show that a limited number of discrete choices leads to optimal performance for the inspection task, while continuous control leads to optimal performance for the docking task.
Collision Avoidance and Geofencing for Fixed-wing Aircraft with Control Barrier Functions
Mar 07, 2024



Safety-critical failures often have fatal consequences in aerospace control. Control systems on aircraft, therefore, must ensure the strict satisfaction of safety constraints, preferably with formal guarantees of safe behavior. This paper establishes the safety-critical control of fixed-wing aircraft in collision avoidance and geofencing tasks. A control framework is developed wherein a run-time assurance (RTA) system modulates the nominal flight controller of the aircraft whenever necessary to prevent it from colliding with other aircraft or crossing a boundary (geofence) in space. The RTA is formulated as a safety filter using control barrier functions (CBFs) with formal guarantees of safe behavior. CBFs are constructed and compared for a nonlinear kinematic fixed-wing aircraft model. The proposed CBF-based controllers showcase the capability of safely executing simultaneous collision avoidance and geofencing, as demonstrated by simulations on the kinematic model and a high-fidelity dynamical model.
Deep Reinforcement Learning for Autonomous Spacecraft Inspection using Illumination
Aug 04, 2023

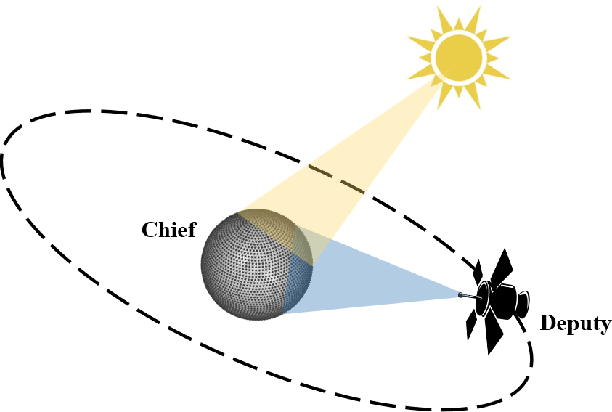
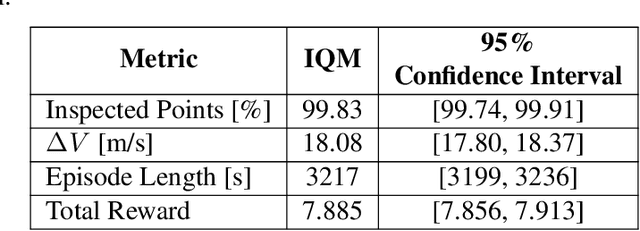
This paper investigates the problem of on-orbit spacecraft inspection using a single free-flying deputy spacecraft, equipped with an optical sensor, whose controller is a neural network control system trained with Reinforcement Learning (RL). This work considers the illumination of the inspected spacecraft (chief) by the Sun in order to incentivize acquisition of well-illuminated optical data. The agent's performance is evaluated through statistically efficient metrics. Results demonstrate that the RL agent is able to inspect all points on the chief successfully, while maximizing illumination on inspected points in a simulated environment, using only low-level actions. Due to the stochastic nature of RL, 10 policies were trained using 10 random seeds to obtain a more holistic measure of agent performance. Over these 10 seeds, the interquartile mean (IQM) percentage of inspected points for the finalized model was 98.82%.
Ablation Study of How Run Time Assurance Impacts the Training and Performance of Reinforcement Learning Agents
Jul 08, 2022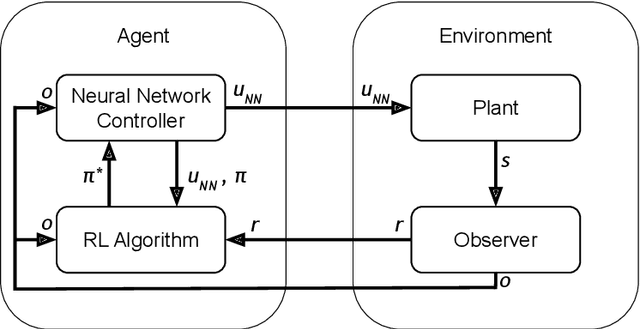

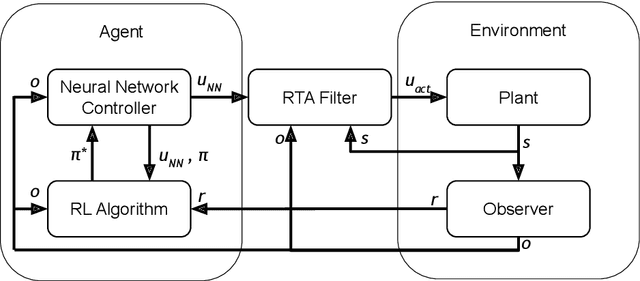
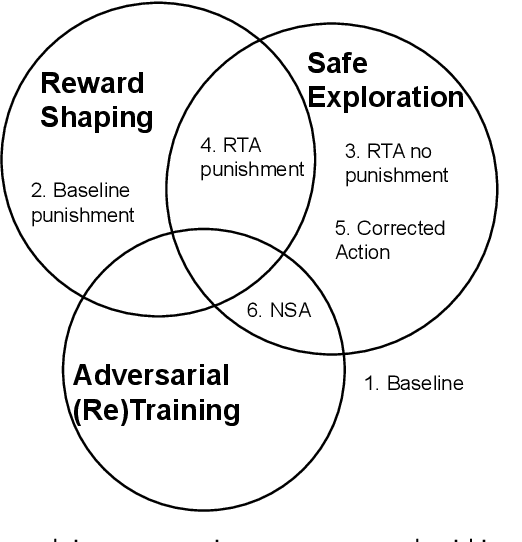
Reinforcement Learning (RL) has become an increasingly important research area as the success of machine learning algorithms and methods grows. To combat the safety concerns surrounding the freedom given to RL agents while training, there has been an increase in work concerning Safe Reinforcement Learning (SRL). However, these new and safe methods have been held to less scrutiny than their unsafe counterparts. For instance, comparisons among safe methods often lack fair evaluation across similar initial condition bounds and hyperparameter settings, use poor evaluation metrics, and cherry-pick the best training runs rather than averaging over multiple random seeds. In this work, we conduct an ablation study using evaluation best practices to investigate the impact of run time assurance (RTA), which monitors the system state and intervenes to assure safety, on effective learning. By studying multiple RTA approaches in both on-policy and off-policy RL algorithms, we seek to understand which RTA methods are most effective, whether the agents become dependent on the RTA, and the importance of reward shaping versus safe exploration in RL agent training. Our conclusions shed light on the most promising directions of SRL, and our evaluation methodology lays the groundwork for creating better comparisons in future SRL work.