 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Impact of Observation Space Design Choices On Training Reinforcement Learning Solutions for Spacecraft Problems
Jan 10, 2025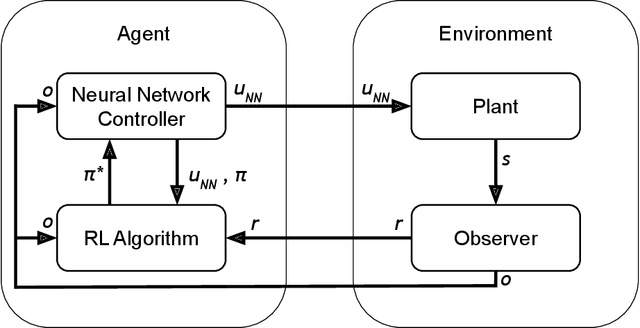
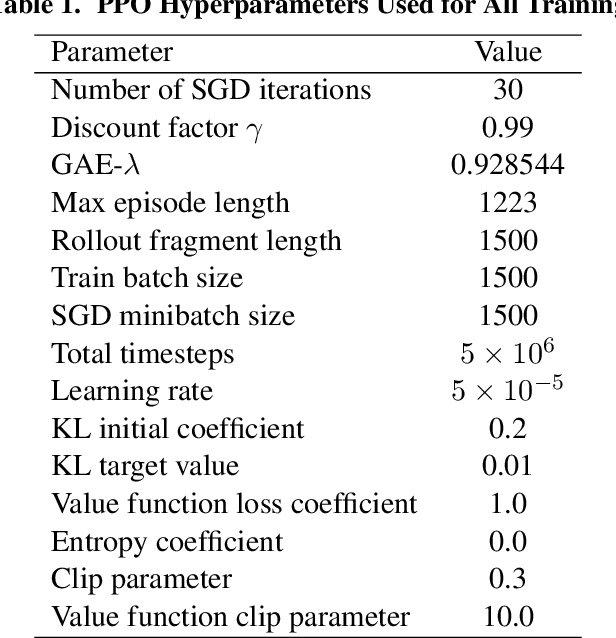
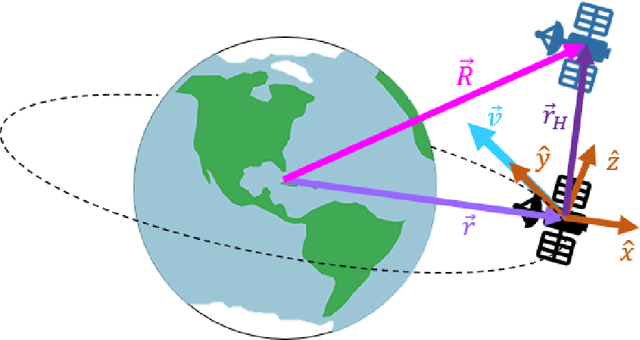
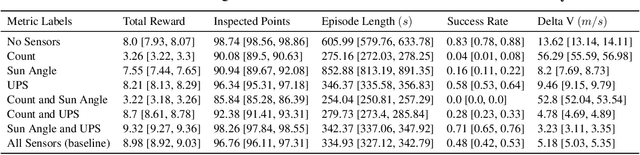
Recent research using Reinforcement Learning (RL) to learn autonomous control for spacecraft operations has shown great success. However, a recent study showed their performance could be improved by changing the action space, i.e. control outputs, used in the learning environment. This has opened the door for finding more improvements through further changes to the environment. The work in this paper focuses on how changes to the environment's observation space can impact the training and performance of RL agents learning the spacecraft inspection task. The studies are split into two groups. The first looks at the impact of sensors that were designed to help agents learn the task. The second looks at the impact of reference frames, reorienting the agent to see the world from a different perspective. The results show the sensors are not necessary, but most of them help agents learn more optimal behavior, and that the reference frame does not have a large impact, but is best kept consistent.
Ablation Study of How Run Time Assurance Impacts the Training and Performance of Reinforcement Learning Agents
Jul 08, 2022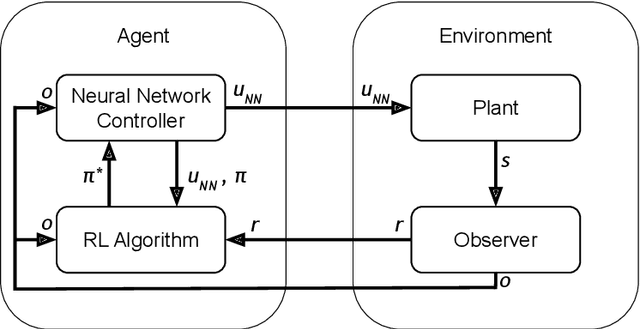

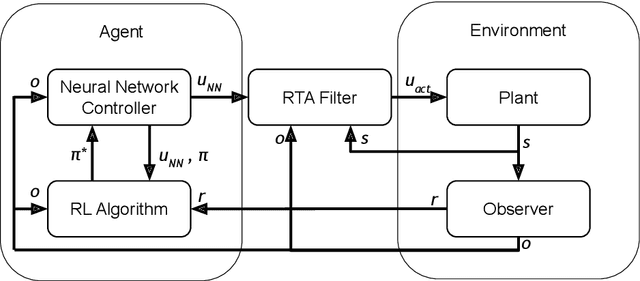
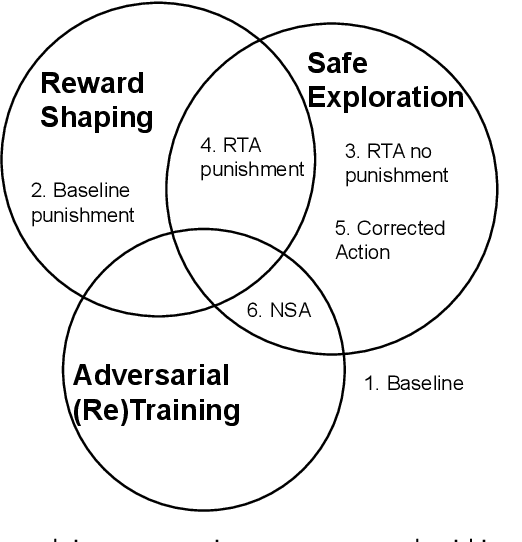
Reinforcement Learning (RL) has become an increasingly important research area as the success of machine learning algorithms and methods grows. To combat the safety concerns surrounding the freedom given to RL agents while training, there has been an increase in work concerning Safe Reinforcement Learning (SRL). However, these new and safe methods have been held to less scrutiny than their unsafe counterparts. For instance, comparisons among safe methods often lack fair evaluation across similar initial condition bounds and hyperparameter settings, use poor evaluation metrics, and cherry-pick the best training runs rather than averaging over multiple random seeds. In this work, we conduct an ablation study using evaluation best practices to investigate the impact of run time assurance (RTA), which monitors the system state and intervenes to assure safety, on effective learning. By studying multiple RTA approaches in both on-policy and off-policy RL algorithms, we seek to understand which RTA methods are most effective, whether the agents become dependent on the RTA, and the importance of reward shaping versus safe exploration in RL agent training. Our conclusions shed light on the most promising directions of SRL, and our evaluation methodology lays the groundwork for creating better comparisons in future SRL work.