 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating Mobile Manipulation in the Wild: A Metrics-Driven Approach
Jan 03, 2024



We present our general-purpose mobile manipulation system consisting of a custom robot platform and key algorithms spanning perception and planning. To extensively test the system in the wild and benchmark its performance, we choose a grocery shopping scenario in an actual, unmodified grocery store. We derive key performance metrics from detailed robot log data collected during six week-long field tests, spread across 18 months. These objective metrics, gained from complex yet repeatable tests, drive the direction of our research efforts and let us continuously improve our system's performance. We find that thorough end-to-end system-level testing of a complex mobile manipulation system can serve as a reality-check for state-of-the-art methods in robotics. This effectively grounds robotics research efforts in real world needs and challenges, which we deem highly useful for the advancement of the field. To this end, we share our key insights and takeaways to inspire and accelerate similar system-level research projects.
A Learned Stereo Depth System for Robotic Manipulation in Homes
Sep 23, 2021

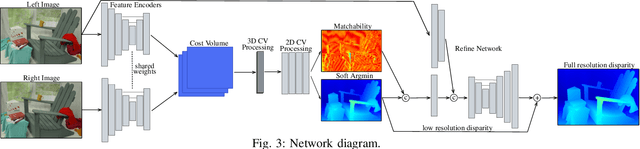

We present a passive stereo depth system that produces dense and accurate point clouds optimized for human environments, including dark, textureless, thin, reflective and specular surfaces and objects, at 2560x2048 resolution, with 384 disparities, in 30 ms. The system consists of an algorithm combining learned stereo matching with engineered filtering, a training and data-mixing methodology, and a sensor hardware design. Our architecture is 15x faster than approaches that perform similarly on the Middlebury and Flying Things Stereo Benchmarks. To effectively supervise the training of this model, we combine real data labelled using off-the-shelf depth sensors, as well as a number of different rendered, simulated labeled datasets. We demonstrate the efficacy of our system by presenting a large number of qualitative results in the form of depth maps and point-clouds, experiments validating the metric accuracy of our system and comparisons to other sensors on challenging objects and scenes. We also show the competitiveness of our algorithm compared to state-of-the-art learned models using the Middlebury and FlyingThings datasets.
A Mobile Manipulation System for One-Shot Teaching of Complex Tasks in Homes
Oct 03, 2019
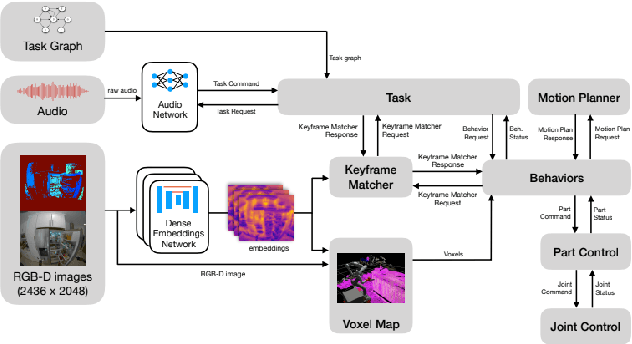
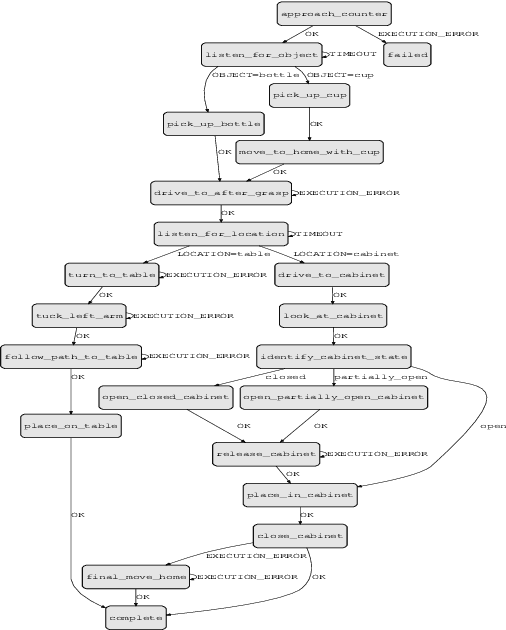

We describe a mobile manipulation hardware and software system capable of autonomously performing complex human-level tasks in real homes, after being taught the task with a single demonstration from a person in virtual reality. This is enabled by a highly capable mobile manipulation robot, whole-body task space hybrid position/force control, teaching of parameterized primitives linked to a robust learned dense visual embeddings representation of the scene, and a task graph of the taught behaviors. We demonstrate the robustness of the approach by presenting results for performing a variety of tasks, under different environmental conditions, in multiple real homes. Our approach achieves 85% overall success rate on three tasks that consist of an average of 45 behaviors each.