 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyIn: Discovering Subgoal Structure with Keyframe-based Video Prediction
Apr 11, 2019



Real-world image sequences can often be naturally decomposed into a small number of frames depicting interesting, highly stochastic moments (its $\textit{keyframes}$) and the low-variance frames in between them. In image sequences depicting trajectories to a goal, keyframes can be seen as capturing the $\textit{subgoals}$ of the sequence as they depict the high-variance moments of interest that ultimately led to the goal. In this paper, we introduce a video prediction model that discovers the keyframe structure of image sequences in an unsupervised fashion. We do so using a hierarchical Keyframe-Intermediate model (KeyIn) that stochastically predicts keyframes and their offsets in time and then uses these predictions to deterministically predict the intermediate frames. We propose a differentiable formulation of this problem that allows us to train the full hierarchical model using a sequence reconstruction loss. We show that our model is able to find meaningful keyframe structure in a simulated dataset of robotic demonstrations and that these keyframes can serve as subgoals for planning. Our model outperforms other hierarchical prediction approaches for planning on a simulated pushing task.
Sparseness Meets Deepness: 3D Human Pose Estimation from Monocular Video
Apr 28, 2016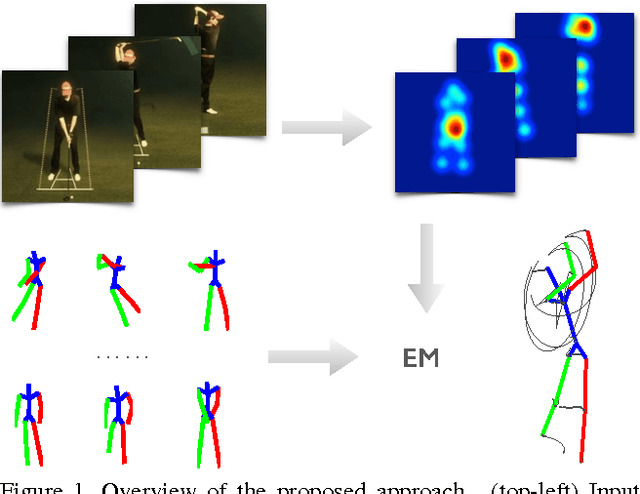

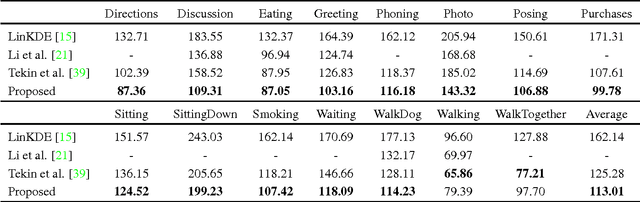
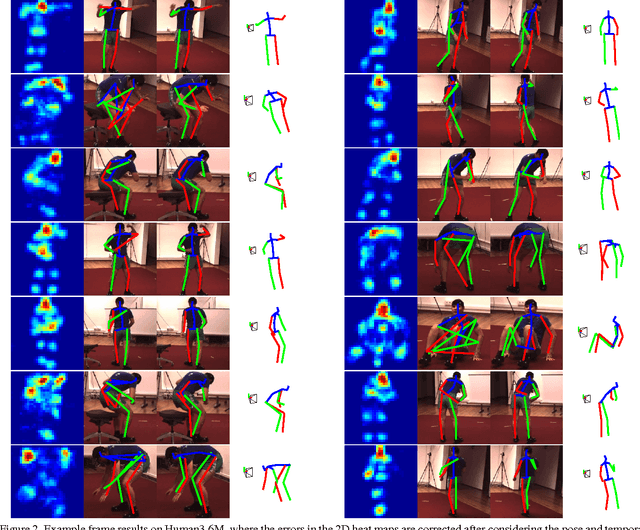
This paper addresses the challenge of 3D full-body human pose estimation from a monocular image sequence. Here, two cases are considered: (i) the image locations of the human joints are provided and (ii) the image locations of joints are unknown. In the former case, a novel approach is introduced that integrates a sparsity-driven 3D geometric prior and temporal smoothness. In the latter case, the former case is extended by treating the image locations of the joints as latent variables. A deep fully convolutional network is trained to predict the uncertainty maps of the 2D joint locations. The 3D pose estimates are realized via an Expectation-Maximization algorithm over the entire sequence, where it is shown that the 2D joint location uncertainties can be conveniently marginalized out during inference. Empirical evaluation on the Human3.6M dataset shows that the proposed approaches achieve greater 3D pose estimation accuracy over state-of-the-art baselines. Further, the proposed approach outperforms a publicly available 2D pose estimation baseline on the challenging PennAction dataset.