 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferability Through Cooperative Competitions
Mar 29, 2026This paper presents a novel framework for cooperative robotics competitions (coopetitions) that promote the transferability and composability of robotics modules, including software, hardware, and data, across heterogeneous robotic systems. The framework is designed to incentivize collaboration between teams through structured task design, shared infrastructure, and a royalty-based scoring system. As a case study, the paper details the implementation and outcomes of the first euROBIN Coopetition, held under the European Robotics and AI Network (euROBIN), which featured fifteen robotic platforms competing across Industrial, Service, and Outdoor domains. The study highlights the practical challenges of achieving module reuse in real-world scenarios, particularly in terms of integration complexity and system compatibility. It also examines participant performance, integration behavior, and team feedback to assess the effectiveness of the framework. The paper concludes with lessons learned and recommendations for future coopetitions, including improveme
Latent Perspective-Taking via a Schrödinger Bridge in Influence-Augmented Local Models
Feb 02, 2026Operating in environments alongside humans requires robots to make decisions under uncertainty. In addition to exogenous dynamics, they must reason over others' hidden mental-models and mental-states. While Interactive POMDPs and Bayesian Theory of Mind formulations are principled, exact nested-belief inference is intractable, and hand-specified models are brittle in open-world settings. We address both by learning structured mental-models and an estimator of others' mental-states. Building on the Influence-Based Abstraction, we instantiate an Influence-Augmented Local Model to decompose socially-aware robot tasks into local dynamics, social influences, and exogenous factors. We propose (a) a neuro-symbolic world model instantiating a factored, discrete Dynamic Bayesian Network, and (b) a perspective-shift operator modeled as an amortized Schrödinger Bridge over the learned local dynamics that transports factored egocentric beliefs into other-centric beliefs. We show that this architecture enables agents to synthesize socially-aware policies in model-based reinforcement learning, via decision-time mental-state planning (a Schrödinger Bridge in belief space), with preliminary results in a MiniGrid social navigation task.
Perspective-Shifted Neuro-Symbolic World Models: A Framework for Socially-Aware Robot Navigation
Mar 26, 2025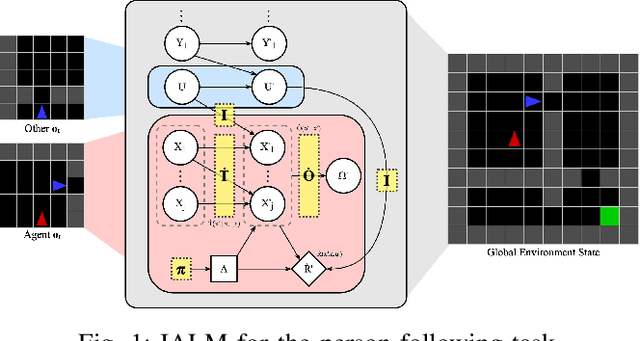
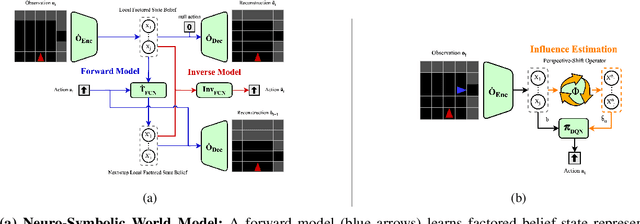
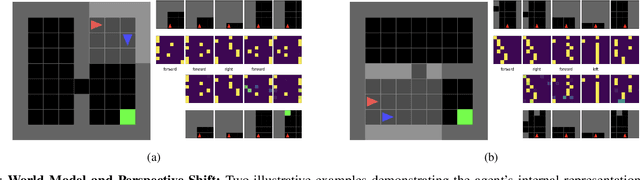
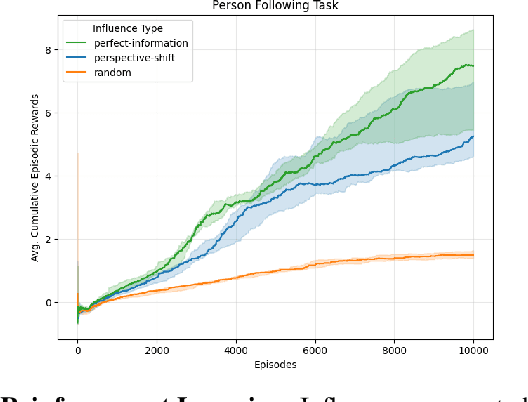
Navigating in environments alongside humans requires agents to reason under uncertainty and account for the beliefs and intentions of those around them. Under a sequential decision-making framework, egocentric navigation can naturally be represented as a Markov Decision Process (MDP). However, social navigation additionally requires reasoning about the hidden beliefs of others, inherently leading to a Partially Observable Markov Decision Process (POMDP), where agents lack direct access to others' mental states. Inspired by Theory of Mind and Epistemic Planning, we propose (1) a neuro-symbolic model-based reinforcement learning architecture for social navigation, addressing the challenge of belief tracking in partially observable environments; and (2) a perspective-shift operator for belief estimation, leveraging recent work on Influence-based Abstractions (IBA) in structured multi-agent settings.
Principal Trade-off Analysis
Jun 09, 2022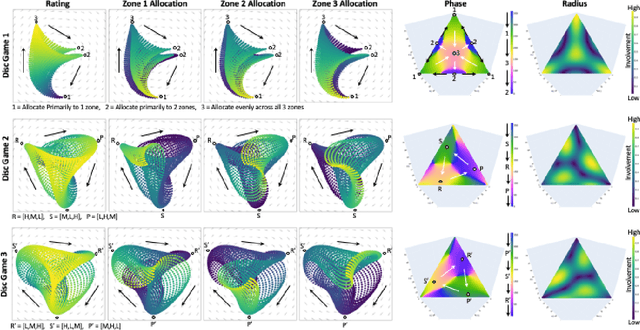
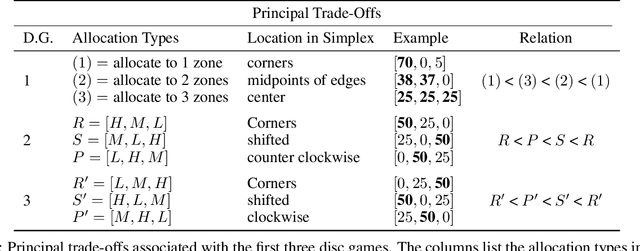
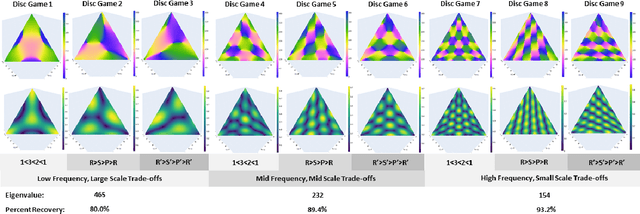

This paper develops Principal Trade-off Analysis (PTA), a decomposition method, analogous to Principal Component Analysis (PCA), which permits the representation of any game as the weighted sum of disc games (continuous R-P-S games). Applying PTA to empirically generated tournament graphs produces a sequence of embeddings into orthogonal 2D feature planes representing independent strategic trade-offs. Each trade-off generates a mode of cyclic competition. Like PCA, PTA provides optimal low rank estimates of the tournament graphs that can be truncated for approximation. The complexity of cyclic competition can be quantified by computing the number of significant cyclic modes. We illustrate the PTA via application to a pair of games (Blotto, Pokemon). The resulting 2D disc game representations are shown to be well suited for visualization and are easily interpretable. In Blotto, PTA identifies game symmetries, and specifies strategic trade-offs associated with distinct win conditions. For Pokemon, PTA embeddings produce clusters in the embedding space that naturally correspond to Pokemon types, a design in the game that produces cyclic trade offs.
Soft Actor-Critic with Inhibitory Networks for Faster Retraining
Feb 08, 2022
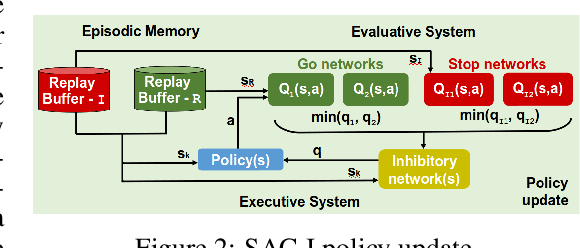

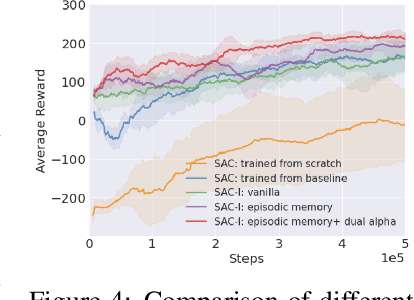
Reusing previously trained models is critical in deep reinforcement learning to speed up training of new agents. However, it is unclear how to acquire new skills when objectives and constraints are in conflict with previously learned skills. Moreover, when retraining, there is an intrinsic conflict between exploiting what has already been learned and exploring new skills. In soft actor-critic (SAC) methods, a temperature parameter can be dynamically adjusted to weight the action entropy and balance the explore $\times$ exploit trade-off. However, controlling a single coefficient can be challenging within the context of retraining, even more so when goals are contradictory. In this work, inspired by neuroscience research, we propose a novel approach using inhibitory networks to allow separate and adaptive state value evaluations, as well as distinct automatic entropy tuning. Ultimately, our approach allows for controlling inhibition to handle conflict between exploiting less risky, acquired behaviors and exploring novel ones to overcome more challenging tasks. We validate our method through experiments in OpenAI Gym environments.
Hierarchical Reinforcement Learning for Air-to-Air Combat
May 03, 2021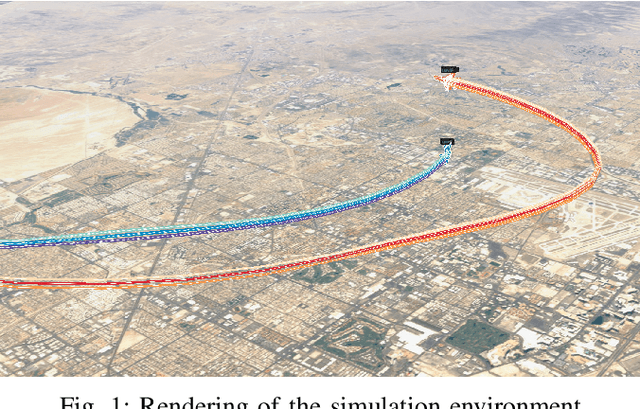

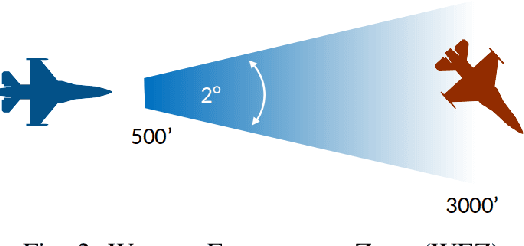
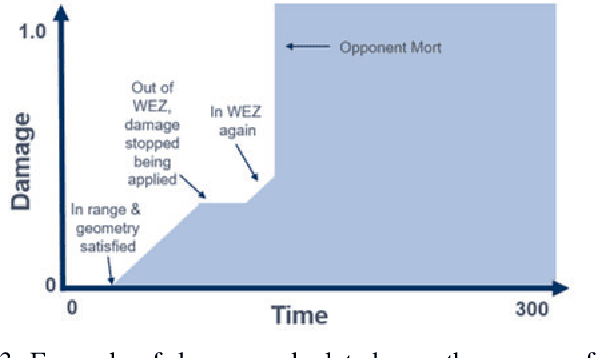
Artificial Intelligence (AI) is becoming a critical component in the defense industry, as recently demonstrated by DARPA`s AlphaDogfight Trials (ADT). ADT sought to vet the feasibility of AI algorithms capable of piloting an F-16 in simulated air-to-air combat. As a participant in ADT, Lockheed Martin`s (LM) approach combines a hierarchical architecture with maximum-entropy reinforcement learning (RL), integrates expert knowledge through reward shaping, and supports modularity of policies. This approach achieved a $2^{nd}$ place finish in the final ADT event (among eight total competitors) and defeated a graduate of the US Air Force's (USAF) F-16 Weapons Instructor Course in match play.