 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Actor-Critic with Inhibitory Networks for Faster Retraining
Feb 08, 2022
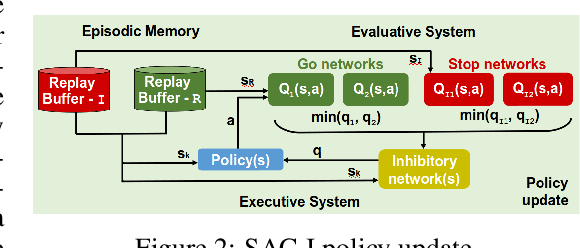

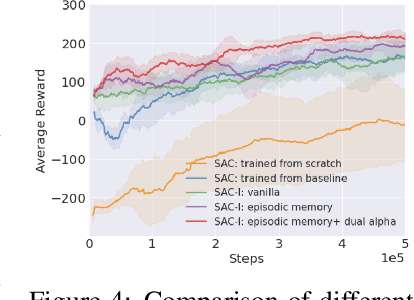
Reusing previously trained models is critical in deep reinforcement learning to speed up training of new agents. However, it is unclear how to acquire new skills when objectives and constraints are in conflict with previously learned skills. Moreover, when retraining, there is an intrinsic conflict between exploiting what has already been learned and exploring new skills. In soft actor-critic (SAC) methods, a temperature parameter can be dynamically adjusted to weight the action entropy and balance the explore $\times$ exploit trade-off. However, controlling a single coefficient can be challenging within the context of retraining, even more so when goals are contradictory. In this work, inspired by neuroscience research, we propose a novel approach using inhibitory networks to allow separate and adaptive state value evaluations, as well as distinct automatic entropy tuning. Ultimately, our approach allows for controlling inhibition to handle conflict between exploiting less risky, acquired behaviors and exploring novel ones to overcome more challenging tasks. We validate our method through experiments in OpenAI Gym environments.
Hierarchical Reinforcement Learning for Air-to-Air Combat
May 03, 2021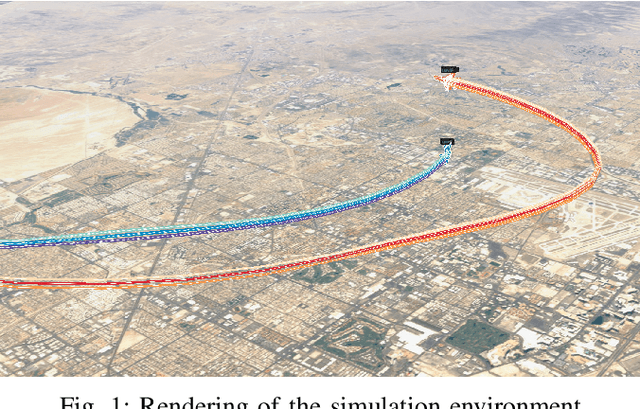

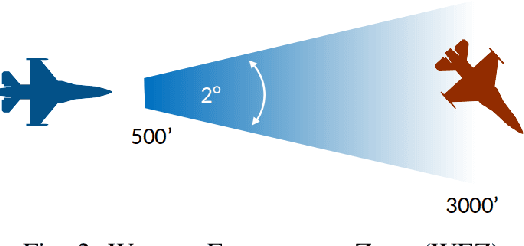
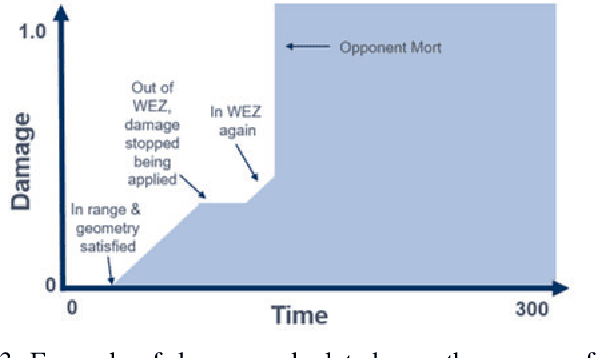
Artificial Intelligence (AI) is becoming a critical component in the defense industry, as recently demonstrated by DARPA`s AlphaDogfight Trials (ADT). ADT sought to vet the feasibility of AI algorithms capable of piloting an F-16 in simulated air-to-air combat. As a participant in ADT, Lockheed Martin`s (LM) approach combines a hierarchical architecture with maximum-entropy reinforcement learning (RL), integrates expert knowledge through reward shaping, and supports modularity of policies. This approach achieved a $2^{nd}$ place finish in the final ADT event (among eight total competitors) and defeated a graduate of the US Air Force's (USAF) F-16 Weapons Instructor Course in match play.