 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Actor-Critic with Inhibitory Networks for Faster Retraining
Feb 08, 2022
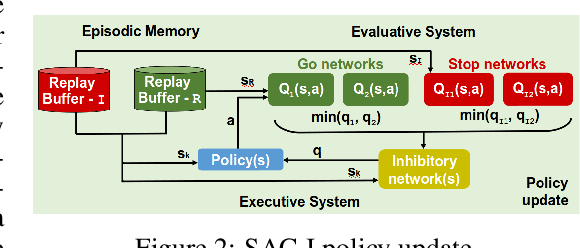

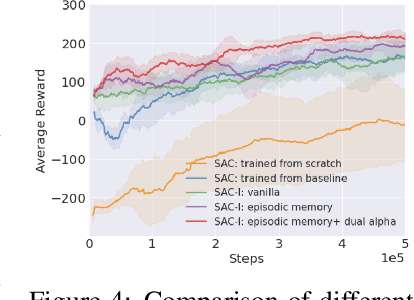
Reusing previously trained models is critical in deep reinforcement learning to speed up training of new agents. However, it is unclear how to acquire new skills when objectives and constraints are in conflict with previously learned skills. Moreover, when retraining, there is an intrinsic conflict between exploiting what has already been learned and exploring new skills. In soft actor-critic (SAC) methods, a temperature parameter can be dynamically adjusted to weight the action entropy and balance the explore $\times$ exploit trade-off. However, controlling a single coefficient can be challenging within the context of retraining, even more so when goals are contradictory. In this work, inspired by neuroscience research, we propose a novel approach using inhibitory networks to allow separate and adaptive state value evaluations, as well as distinct automatic entropy tuning. Ultimately, our approach allows for controlling inhibition to handle conflict between exploiting less risky, acquired behaviors and exploring novel ones to overcome more challenging tasks. We validate our method through experiments in OpenAI Gym environments.