 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Stratified Space Structure of an RL Game with the Volume Growth Transform
Jul 29, 2025



In this work, we explore the structure of the embedding space of a transformer model trained for playing a particular reinforcement learning (RL) game. Specifically, we investigate how a transformer-based Proximal Policy Optimization (PPO) model embeds visual inputs in a simple environment where an agent must collect "coins" while avoiding dynamic obstacles consisting of "spotlights." By adapting Robinson et al.'s study of the volume growth transform for LLMs to the RL setting, we find that the token embedding space for our visual coin collecting game is also not a manifold, and is better modeled as a stratified space, where local dimension can vary from point to point. We further strengthen Robinson's method by proving that fairly general volume growth curves can be realized by stratified spaces. Finally, we carry out an analysis that suggests that as an RL agent acts, its latent representation alternates between periods of low local dimension, while following a fixed sub-strategy, and bursts of high local dimension, where the agent achieves a sub-goal (e.g., collecting an object) or where the environmental complexity increases (e.g., more obstacles appear). Consequently, our work suggests that the distribution of dimensions in a stratified latent space may provide a new geometric indicator of complexity for RL games.
Principal Trade-off Analysis
Jun 09, 2022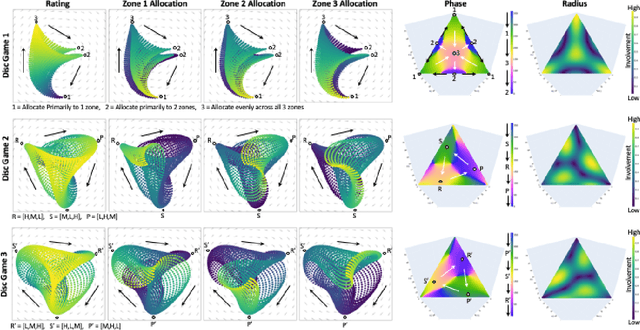
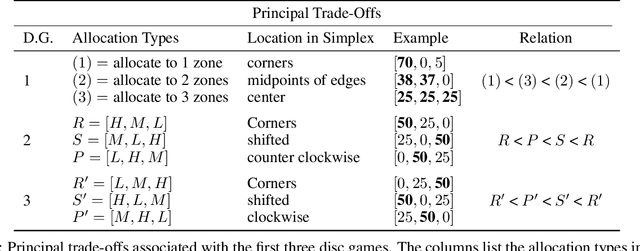
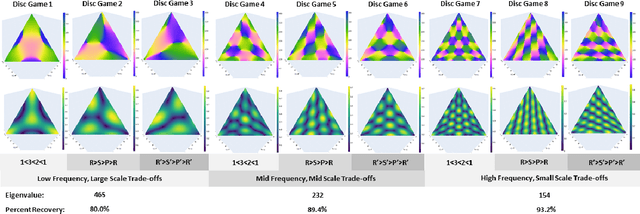

This paper develops Principal Trade-off Analysis (PTA), a decomposition method, analogous to Principal Component Analysis (PCA), which permits the representation of any game as the weighted sum of disc games (continuous R-P-S games). Applying PTA to empirically generated tournament graphs produces a sequence of embeddings into orthogonal 2D feature planes representing independent strategic trade-offs. Each trade-off generates a mode of cyclic competition. Like PCA, PTA provides optimal low rank estimates of the tournament graphs that can be truncated for approximation. The complexity of cyclic competition can be quantified by computing the number of significant cyclic modes. We illustrate the PTA via application to a pair of games (Blotto, Pokemon). The resulting 2D disc game representations are shown to be well suited for visualization and are easily interpretable. In Blotto, PTA identifies game symmetries, and specifies strategic trade-offs associated with distinct win conditions. For Pokemon, PTA embeddings produce clusters in the embedding space that naturally correspond to Pokemon types, a design in the game that produces cyclic trade offs.
Soft Actor-Critic with Inhibitory Networks for Faster Retraining
Feb 08, 2022
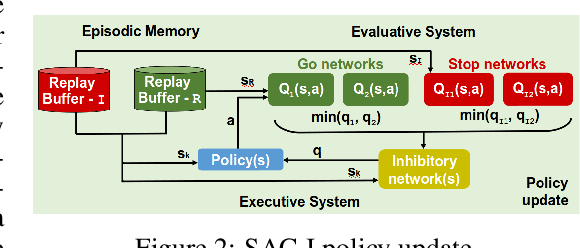

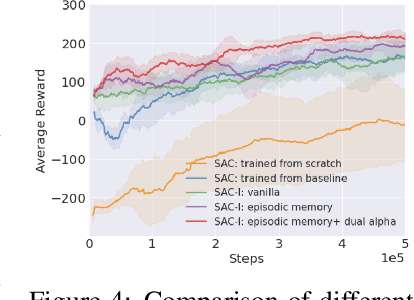
Reusing previously trained models is critical in deep reinforcement learning to speed up training of new agents. However, it is unclear how to acquire new skills when objectives and constraints are in conflict with previously learned skills. Moreover, when retraining, there is an intrinsic conflict between exploiting what has already been learned and exploring new skills. In soft actor-critic (SAC) methods, a temperature parameter can be dynamically adjusted to weight the action entropy and balance the explore $\times$ exploit trade-off. However, controlling a single coefficient can be challenging within the context of retraining, even more so when goals are contradictory. In this work, inspired by neuroscience research, we propose a novel approach using inhibitory networks to allow separate and adaptive state value evaluations, as well as distinct automatic entropy tuning. Ultimately, our approach allows for controlling inhibition to handle conflict between exploiting less risky, acquired behaviors and exploring novel ones to overcome more challenging tasks. We validate our method through experiments in OpenAI Gym environments.
Ethics, Rules of Engagement, and AI: Neural Narrative Mapping Using Large Transformer Language Models
Feb 05, 2022
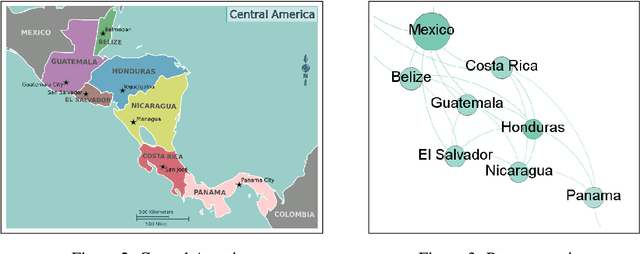
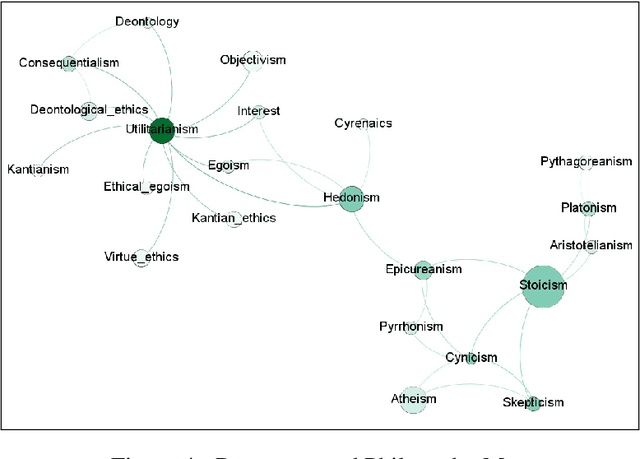
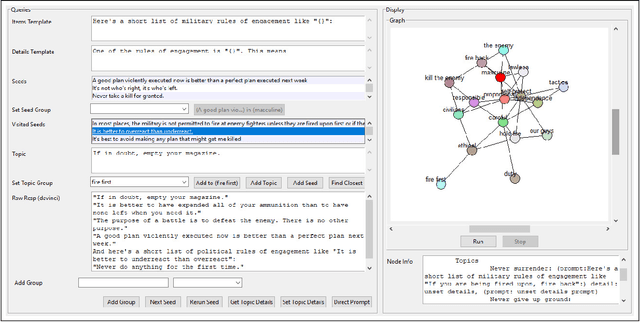
The problem of determining if a military unit has correctly understood an order and is properly executing on it is one that has bedeviled military planners throughout history. The advent of advanced language models such as OpenAI's GPT-series offers new possibilities for addressing this problem. This paper presents a mechanism to harness the narrative output of large language models and produce diagrams or "maps" of the relationships that are latent in the weights of such models as the GPT-3. The resulting "Neural Narrative Maps" (NNMs), are intended to provide insight into the organization of information, opinion, and belief in the model, which in turn provide means to understand intent and response in the context of physical distance. This paper discusses the problem of mapping information spaces in general, and then presents a concrete implementation of this concept in the context of OpenAI's GPT-3 language model for determining if a subordinate is following a commander's intent in a high-risk situation. The subordinate's locations within the NNM allow a novel capability to evaluate the intent of the subordinate with respect to the commander. We show that is is possible not only to determine if they are nearby in narrative space, but also how they are oriented, and what "trajectory" they are on. Our results show that our method is able to produce high-quality maps, and demonstrate new ways of evaluating intent more generally.
* 18 Pages, 13 figures
A Photonic-Circuits-Inspired Compact Network: Toward Real-Time Wireless Signal Classification at the Edge
Jun 25, 2021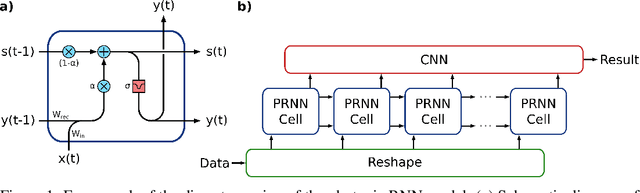
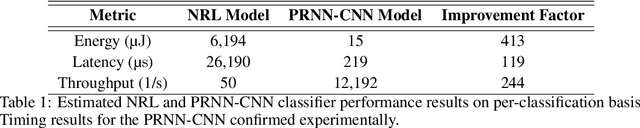
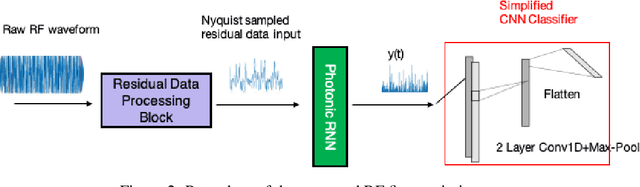

Machine learning (ML) methods are ubiquitous in wireless communication systems and have proven powerful for applications including radio-frequency (RF) fingerprinting, automatic modulation classification, and cognitive radio. However, the large size of ML models can make them difficult to implement on edge devices for latency-sensitive downstream tasks. In wireless communication systems, ML data processing at a sub-millisecond scale will enable real-time network monitoring to improve security and prevent infiltration. In addition, compact and integratable hardware platforms which can implement ML models at the chip scale will find much broader application to wireless communication networks. Toward real-time wireless signal classification at the edge, we propose a novel compact deep network that consists of a photonic-hardware-inspired recurrent neural network model in combination with a simplified convolutional classifier, and we demonstrate its application to the identification of RF emitters by their random transmissions. With the proposed model, we achieve 96.32% classification accuracy over a set of 30 identical ZigBee devices when using 50 times fewer training parameters than an existing state-of-the-art CNN classifier. Thanks to the large reduction in network size, we demonstrate real-time RF fingerprinting with 0.219 ms latency using a small-scale FPGA board, the PYNQ-Z1.
Hierarchical Reinforcement Learning for Air-to-Air Combat
May 03, 2021

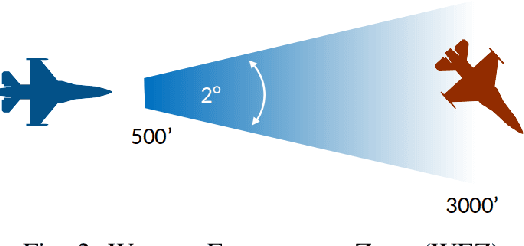
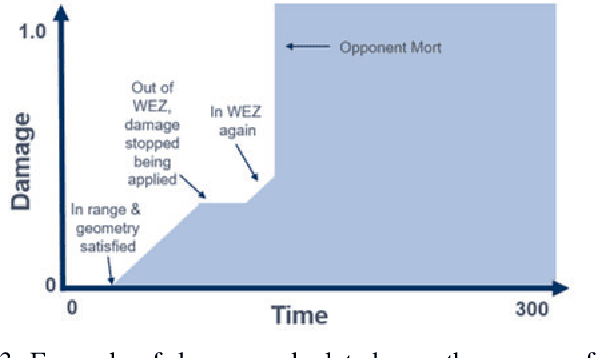
Artificial Intelligence (AI) is becoming a critical component in the defense industry, as recently demonstrated by DARPA`s AlphaDogfight Trials (ADT). ADT sought to vet the feasibility of AI algorithms capable of piloting an F-16 in simulated air-to-air combat. As a participant in ADT, Lockheed Martin`s (LM) approach combines a hierarchical architecture with maximum-entropy reinforcement learning (RL), integrates expert knowledge through reward shaping, and supports modularity of policies. This approach achieved a $2^{nd}$ place finish in the final ADT event (among eight total competitors) and defeated a graduate of the US Air Force's (USAF) F-16 Weapons Instructor Course in match play.