 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmploying Multimodal Machine Learning for Stress Detection
Jun 15, 2023In the current age, human lifestyle has become more knowledge oriented leading to generation of sedentary employment. This has given rise to a number of health and mental disorders. Mental wellness is one of the most neglected but crucial aspects of today's world. Mental health issues can, both directly and indirectly, affect other sections of human physiology and impede an individual's day-to-day activities and performance. However, identifying the stress and finding the stress trend for an individual leading to serious mental ailments is challenging and involves multiple factors. Such identification can be achieved accurately by fusing these multiple modalities (due to various factors) arising from behavioral patterns. Certain techniques are identified in the literature for this purpose; however, very few machine learning-based methods are proposed for such multimodal fusion tasks. In this work, a multimodal AI-based framework is proposed to monitor a person's working behavior and stress levels. We propose a methodology for efficiently detecting stress due to workload by concatenating heterogeneous raw sensor data streams (e.g., face expressions, posture, heart rate, computer interaction). This data can be securely stored and analyzed to understand and discover personalized unique behavioral patterns leading to mental strain and fatigue. The contribution of this work is twofold; proposing a multimodal AI-based strategy for fusion to detect stress and its level and secondly identify a stress pattern over a period of time. We were able to achieve 96.09% accuracy on the test set in stress detection and classification. Further, we reduce the stress scale prediction model loss to 0.036 using these modalities. This work can prove important for the community at large, specifically those working sedentary jobs to monitor and identify stress levels, especially in current times of COVID-19.
WEDGE: A multi-weather autonomous driving dataset built from generative vision-language models
May 12, 2023



The open road poses many challenges to autonomous perception, including poor visibility from extreme weather conditions. Models trained on good-weather datasets frequently fail at detection in these out-of-distribution settings. To aid adversarial robustness in perception, we introduce WEDGE (WEather images by DALL-E GEneration): a synthetic dataset generated with a vision-language generative model via prompting. WEDGE consists of 3360 images in 16 extreme weather conditions manually annotated with 16513 bounding boxes, supporting research in the tasks of weather classification and 2D object detection. We have analyzed WEDGE from research standpoints, verifying its effectiveness for extreme-weather autonomous perception. We establish baseline performance for classification and detection with 53.87% test accuracy and 45.41 mAP. Most importantly, WEDGE can be used to fine-tune state-of-the-art detectors, improving SOTA performance on real-world weather benchmarks (such as DAWN) by 4.48 AP for well-generated classes like trucks. WEDGE has been collected under OpenAI's terms of use and is released for public use under the CC BY-NC-SA 4.0 license. The repository for this work and dataset is available at https://infernolia.github.io/WEDGE.
Transfer Learning for Real-time Deployment of a Screening Tool for Depression Detection Using Actigraphy
Mar 14, 2023Automated depression screening and diagnosis is a highly relevant problem today. There are a number of limitations of the traditional depression detection methods, namely, high dependence on clinicians and biased self-reporting. In recent years, research has suggested strong potential in machine learning (ML) based methods that make use of the user's passive data collected via wearable devices. However, ML is data hungry. Especially in the healthcare domain primary data collection is challenging. In this work, we present an approach based on transfer learning, from a model trained on a secondary dataset, for the real time deployment of the depression screening tool based on the actigraphy data of users. This approach enables machine learning modelling even with limited primary data samples. A modified version of leave one out cross validation approach performed on the primary set resulted in mean accuracy of 0.96, where in each iteration one subject's data from the primary set was set aside for testing.
RestoreX-AI: A Contrastive Approach towards Guiding Image Restoration via Explainable AI Systems
Apr 03, 2022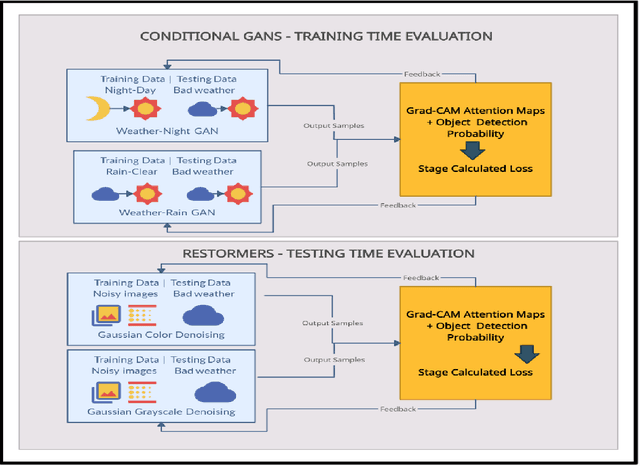
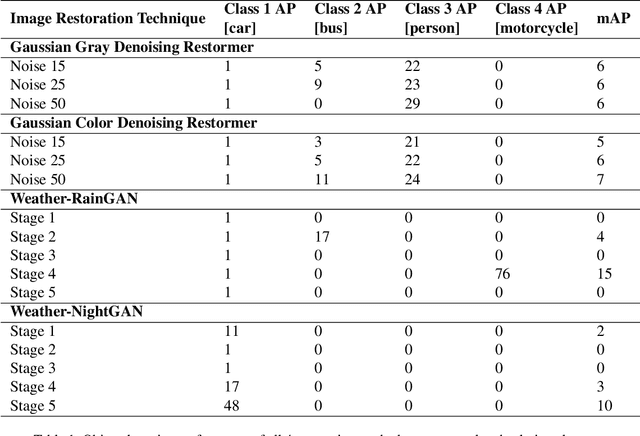


Modern applications such as self-driving cars and drones rely heavily upon robust object detection techniques. However, weather corruptions can hinder the object detectability and pose a serious threat to their navigation and reliability. Thus, there is a need for efficient denoising, deraining, and restoration techniques. Generative adversarial networks and transformers have been widely adopted for image restoration. However, the training of these methods is often unstable and time-consuming. Furthermore, when used for object detection (OD), the output images generated by these methods may provide unsatisfactory results despite image clarity. In this work, we propose a contrastive approach towards mitigating this problem, by evaluating images generated by restoration models during and post training. This approach leverages OD scores combined with attention maps for predicting the usefulness of restored images for the OD task. We conduct experiments using two novel use-cases of conditional GANs and two transformer methods that probe the robustness of the proposed approach on multi-weather corruptions in the OD task. Our approach achieves an averaged 178 percent increase in mAP between the input and restored images under adverse weather conditions like dust tornadoes and snowfall. We report unique cases where greater denoising does not improve OD performance and conversely where noisy generated images demonstrate good results. We conclude the need for explainability frameworks to bridge the gap between human and machine perception, especially in the context of robust object detection for autonomous vehicles.
In Rain or Shine: Understanding and Overcoming Dataset Bias for Improving Robustness Against Weather Corruptions for Autonomous Vehicles
Apr 03, 2022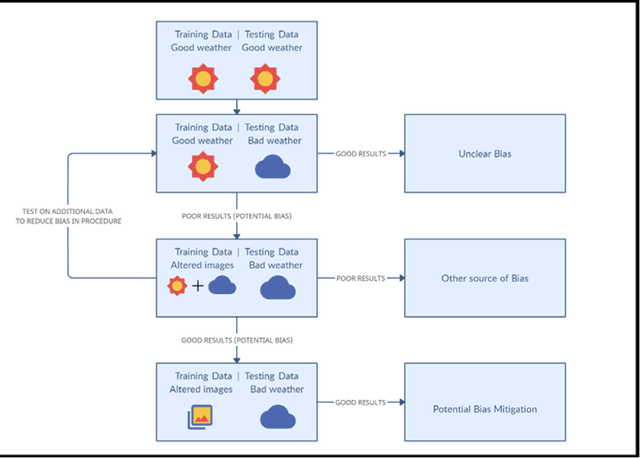
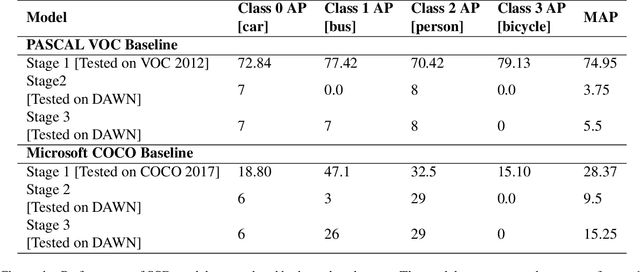
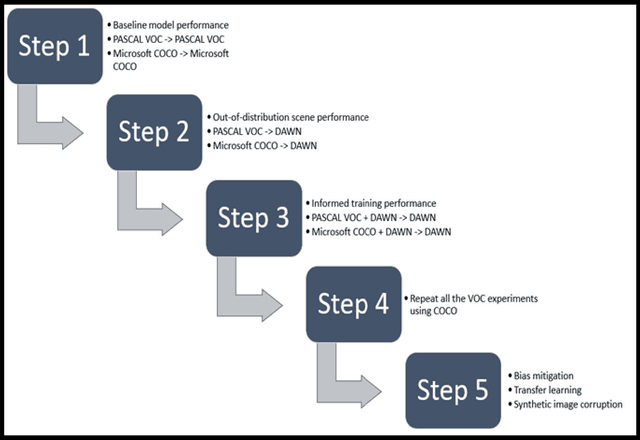
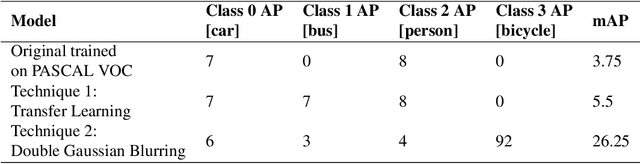
Several popular computer vision (CV) datasets, specifically employed for Object Detection (OD) in autonomous driving tasks exhibit biases due to a range of factors including weather and lighting conditions. These biases may impair a model's generalizability, rendering it ineffective for OD in novel and unseen datasets. Especially, in autonomous driving, it may prove extremely high risk and unsafe for the vehicle and its surroundings. This work focuses on understanding these datasets better by identifying such "good-weather" bias. Methods to mitigate such bias which allows the OD models to perform better and improve the robustness are also demonstrated. A simple yet effective OD framework for studying bias mitigation is proposed. Using this framework, the performance on popular datasets is analyzed and a significant difference in model performance is observed. Additionally, a knowledge transfer technique and a synthetic image corruption technique are proposed to mitigate the identified bias. Finally, using the DAWN dataset, the findings are validated on the OD task, demonstrating the effectiveness of our techniques in mitigating real-world "good-weather" bias. The experiments show that the proposed techniques outperform baseline methods by averaged fourfold improvement.
Explainable Misinformation Detection Across Multiple Social Media Platforms
Mar 20, 2022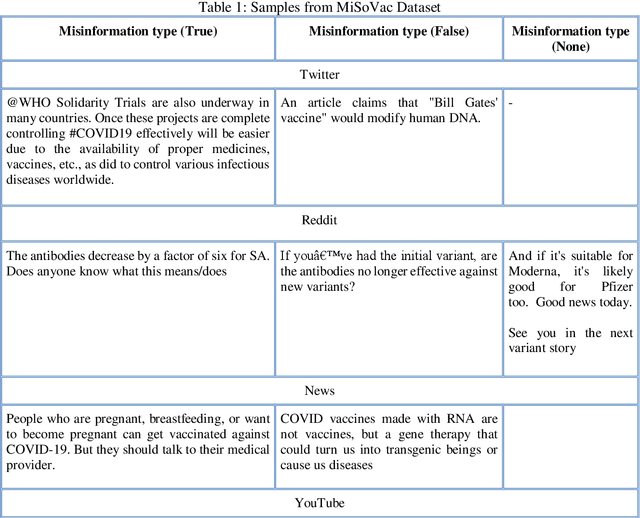
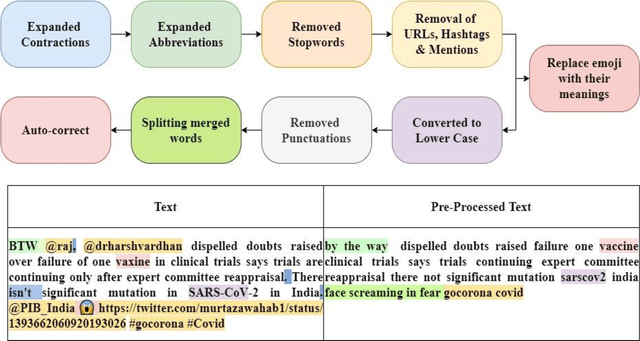
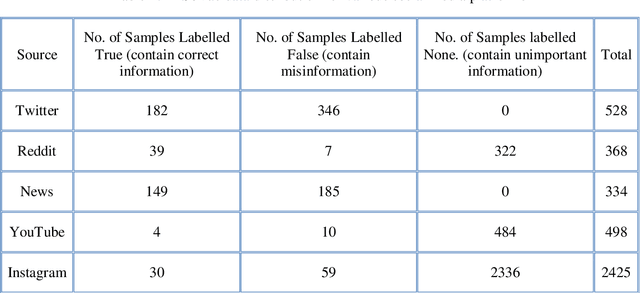
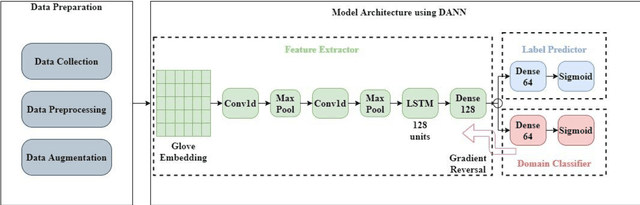
In this work, the integration of two machine learning approaches, namely domain adaptation and explainable AI, is proposed to address these two issues of generalized detection and explainability. Firstly the Domain Adversarial Neural Network (DANN) develops a generalized misinformation detector across multiple social media platforms DANN is employed to generate the classification results for test domains with relevant but unseen data. The DANN-based model, a traditional black-box model, cannot justify its outcome, i.e., the labels for the target domain. Hence a Local Interpretable Model-Agnostic Explanations (LIME) explainable AI model is applied to explain the outcome of the DANN mode. To demonstrate these two approaches and their integration for effective explainable generalized detection, COVID-19 misinformation is considered a case study. We experimented with two datasets, namely CoAID and MiSoVac, and compared results with and without DANN implementation. DANN significantly improves the accuracy measure F1 classification score and increases the accuracy and AUC performance. The results obtained show that the proposed framework performs well in the case of domain shift and can learn domain-invariant features while explaining the target labels with LIME implementation enabling trustworthy information processing and extraction to combat misinformation effectively.
A comprehensive survey on computational learning methods for analysis of gene expression data in genomics
Feb 16, 2022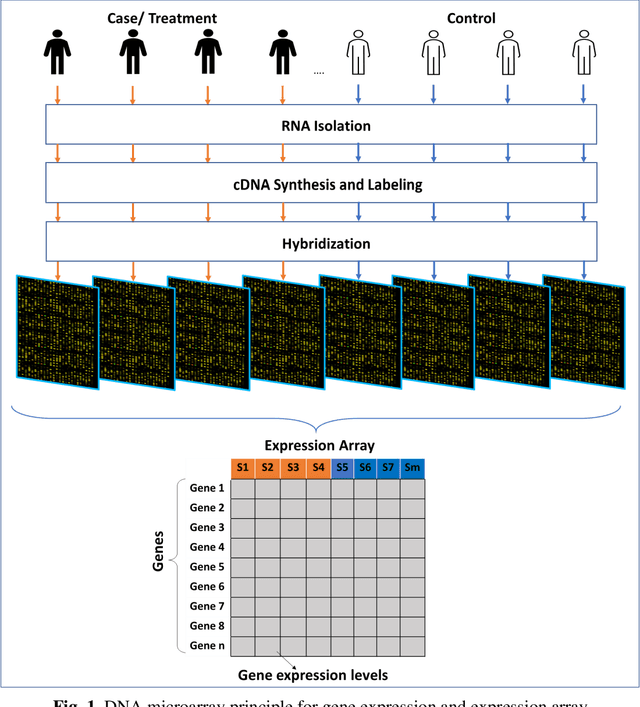

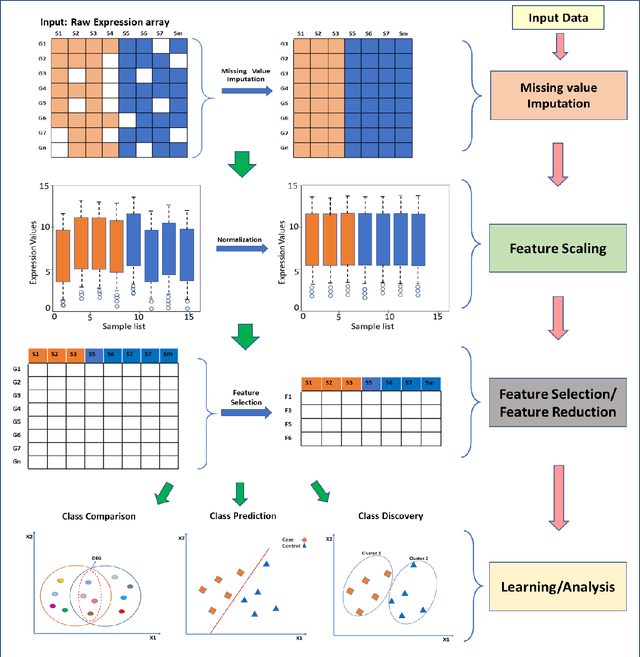
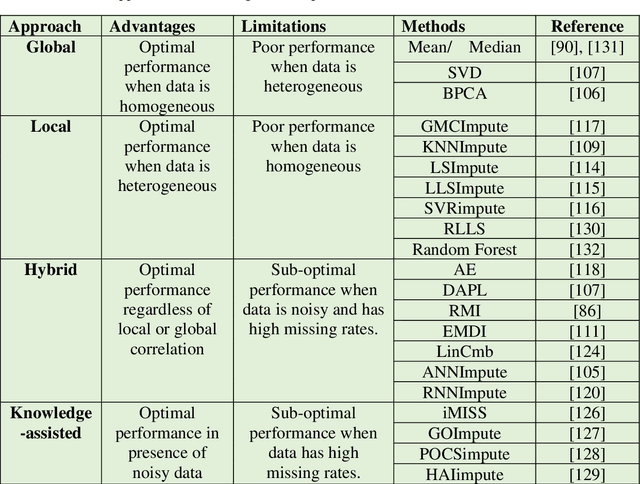
Computational analysis methods including machine learning have a significant impact in the fields of genomics and medicine. High-throughput gene expression analysis methods such as microarray technology and RNA sequencing produce enormous amounts of data. Traditionally, statistical methods are used for comparative analysis of the gene expression data. However, more complex analysis for classification and discovery of feature genes or sample observations requires sophisticated computational approaches. In this review, we compile various statistical and computational tools used in analysis of expression microarray data. Even though, the methods are discussed in the context of expression microarray data, they can also be applied for the analysis of RNA sequencing or quantitative proteomics datasets. We specifically discuss methods for missing value (gene expression) imputation, feature gene scaling, selection and extraction of features for dimensionality reduction, and learning and analysis of expression data. We discuss the types of missing values and the methods and approaches usually employed in their imputation. We also discuss methods of data transformation and feature scaling viz. normalization and standardization. Various approaches used in feature selection and extraction are also reviewed. Lastly, learning and analysis methods including class comparison, class prediction, and class discovery along with their evaluation parameters are described in detail. We have described the process of generation of a microarray gene expression data along with advantages and limitations of the above-mentioned techniques. We believe that this detailed review will help the users to select appropriate methods based on the type of data and the expected outcome.
Incremental learning of LSTM framework for sensor fusion in attitude estimation
Aug 04, 2021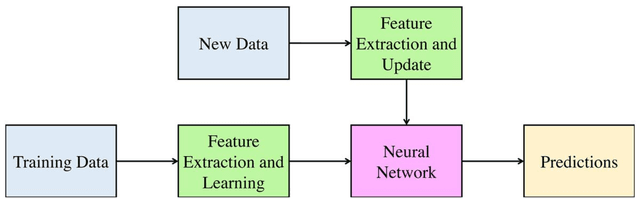
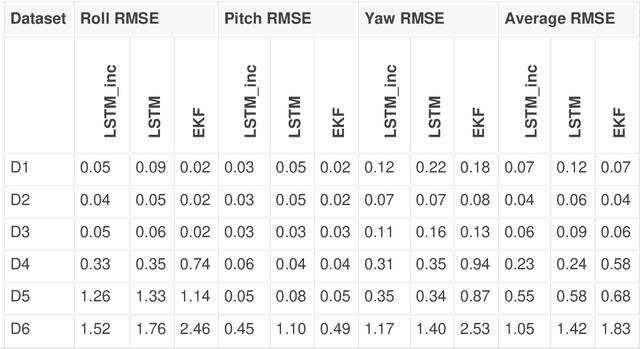
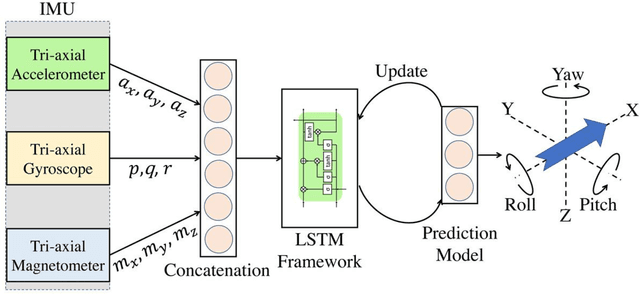
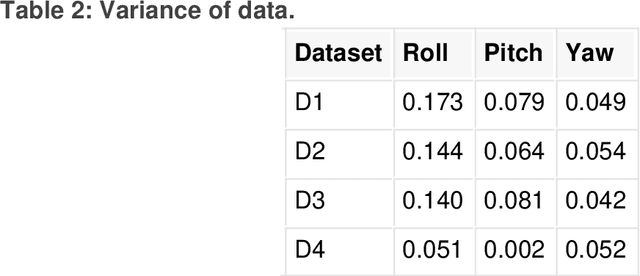
This paper presents a novel method for attitude estimation of an object in 3D space by incremental learning of the Long-Short Term Memory (LSTM) network. Gyroscope, accelerometer, and magnetometer are few widely used sensors in attitude estimation applications. Traditionally, multi-sensor fusion methods such as the Extended Kalman Filter and Complementary Filter are employed to fuse the measurements from these sensors. However, these methods exhibit limitations in accounting for the uncertainty, unpredictability, and dynamic nature of the motion in real-world situations. In this paper, the inertial sensors data are fed to the LSTM network which are then updated incrementally to incorporate the dynamic changes in motion occurring in the run time. The robustness and efficiency of the proposed framework is demonstrated on the dataset collected from a commercially available inertial measurement unit. The proposed framework offers a significant improvement in the results compared to the traditional method, even in the case of a highly dynamic environment. The LSTM framework-based attitude estimation approach can be deployed on a standard AI-supported processing module for real-time applications.
Multimodal Co-learning: Challenges, Applications with Datasets, Recent Advances and Future Directions
Jul 29, 2021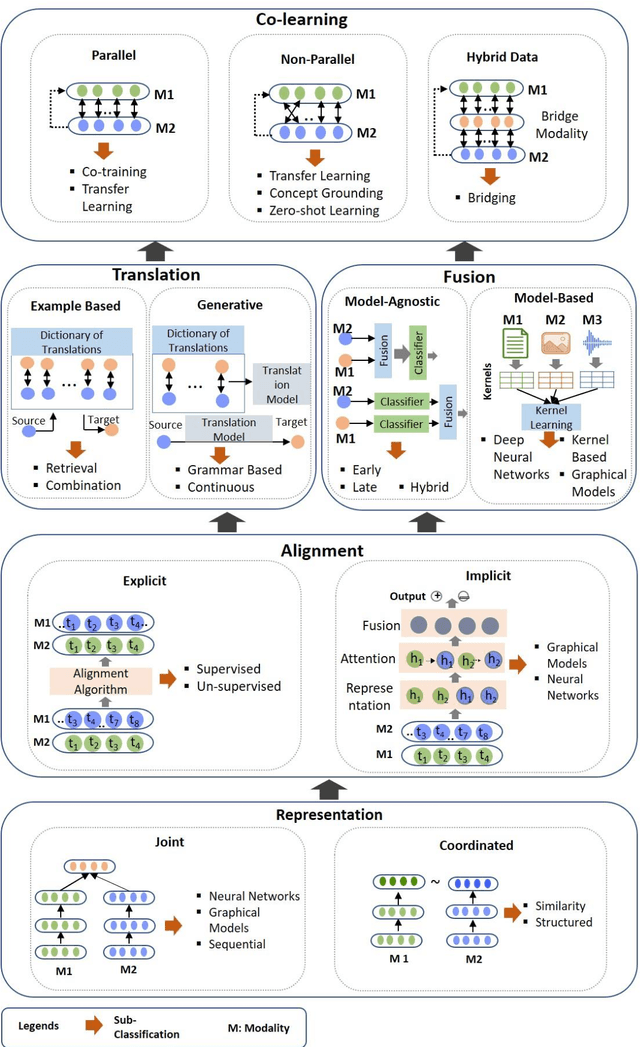
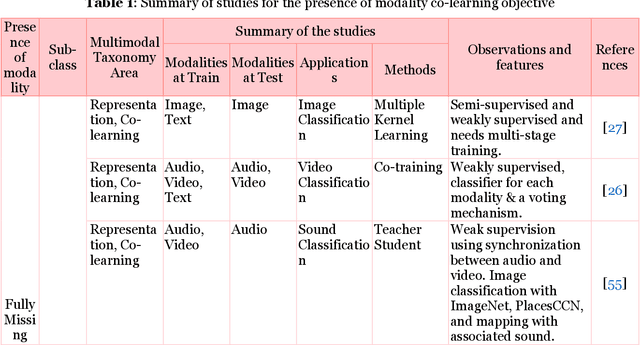
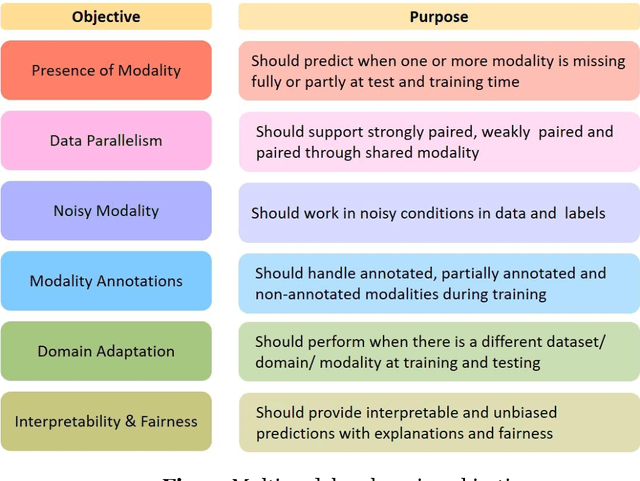
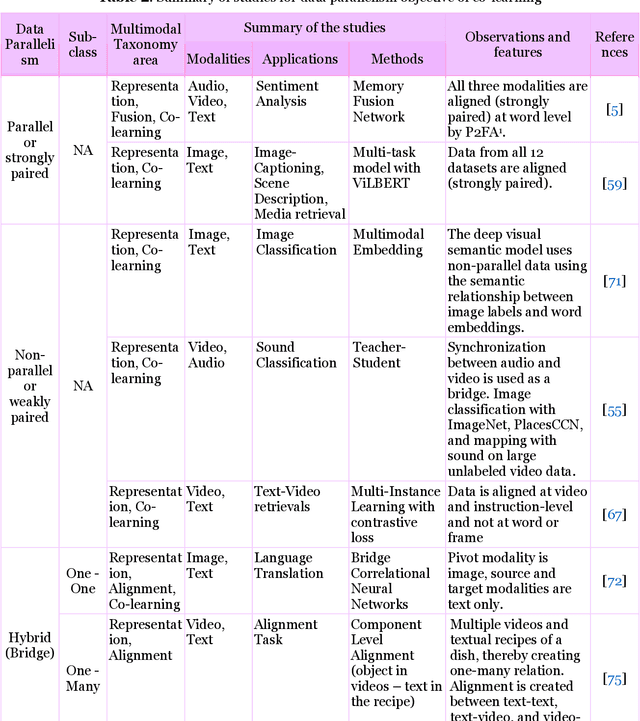
Multimodal deep learning systems which employ multiple modalities like text, image, audio, video, etc., are showing better performance in comparison with individual modalities (i.e., unimodal) systems. Multimodal machine learning involves multiple aspects: representation, translation, alignment, fusion, and co-learning. In the current state of multimodal machine learning, the assumptions are that all modalities are present, aligned, and noiseless during training and testing time. However, in real-world tasks, typically, it is observed that one or more modalities are missing, noisy, lacking annotated data, have unreliable labels, and are scarce in training or testing and or both. This challenge is addressed by a learning paradigm called multimodal co-learning. The modeling of a (resource-poor) modality is aided by exploiting knowledge from another (resource-rich) modality using transfer of knowledge between modalities, including their representations and predictive models. Co-learning being an emerging area, there are no dedicated reviews explicitly focusing on all challenges addressed by co-learning. To that end, in this work, we provide a comprehensive survey on the emerging area of multimodal co-learning that has not been explored in its entirety yet. We review implementations that overcome one or more co-learning challenges without explicitly considering them as co-learning challenges. We present the comprehensive taxonomy of multimodal co-learning based on the challenges addressed by co-learning and associated implementations. The various techniques employed to include the latest ones are reviewed along with some of the applications and datasets. Our final goal is to discuss challenges and perspectives along with the important ideas and directions for future work that we hope to be beneficial for the entire research community focusing on this exciting domain.
Gas Detection and Identification Using Multimodal Artificial Intelligence Based Sensor Fusion
Jun 11, 2021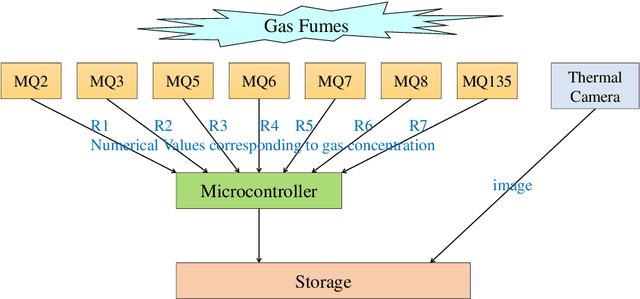
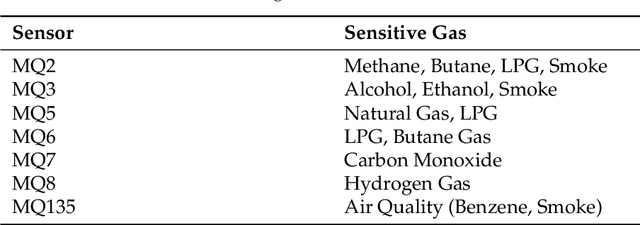
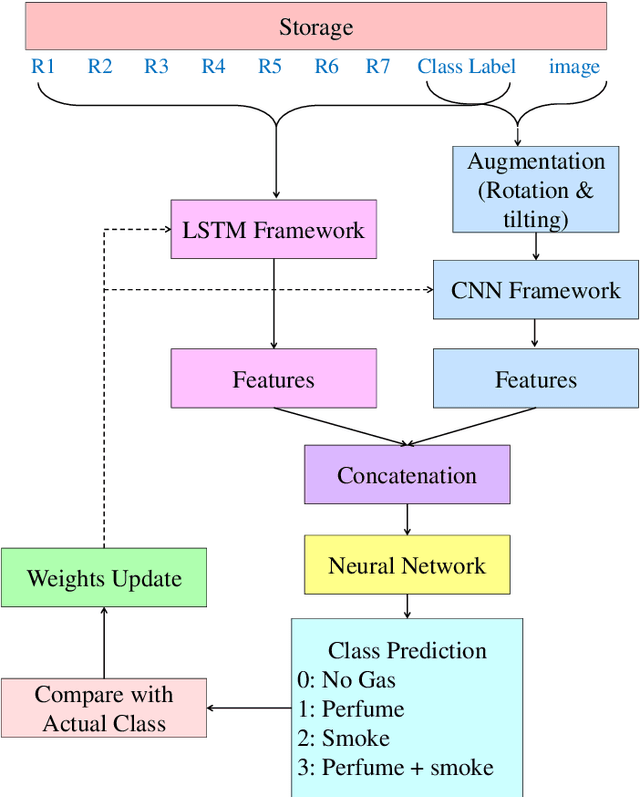
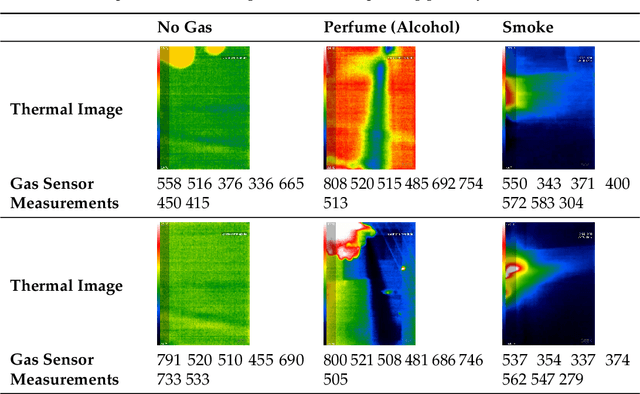
With the rapid industrialization and technological advancements, innovative engineering technologies which are cost effective, faster and easier to implement are essential. One such area of concern is the rising number of accidents happening due to gas leaks at coal mines, chemical industries, home appliances etc. In this paper we propose a novel approach to detect and identify the gaseous emissions using the multimodal AI fusion techniques. Most of the gases and their fumes are colorless, odorless, and tasteless, thereby challenging our normal human senses. Sensing based on a single sensor may not be accurate, and sensor fusion is essential for robust and reliable detection in several real-world applications. We manually collected 6400 gas samples (1600 samples per class for four classes) using two specific sensors: the 7-semiconductor gas sensors array, and a thermal camera. The early fusion method of multimodal AI, is applied The network architecture consists of a feature extraction module for individual modality, which is then fused using a merged layer followed by a dense layer, which provides a single output for identifying the gas. We obtained the testing accuracy of 96% (for fused model) as opposed to individual model accuracies of 82% (based on Gas Sensor data using LSTM) and 93% (based on thermal images data using CNN model). Results demonstrate that the fusion of multiple sensors and modalities outperforms the outcome of a single sensor.
* 14 Pages, 9 Figures