 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Misinformation Detection Across Multiple Social Media Platforms
Mar 20, 2022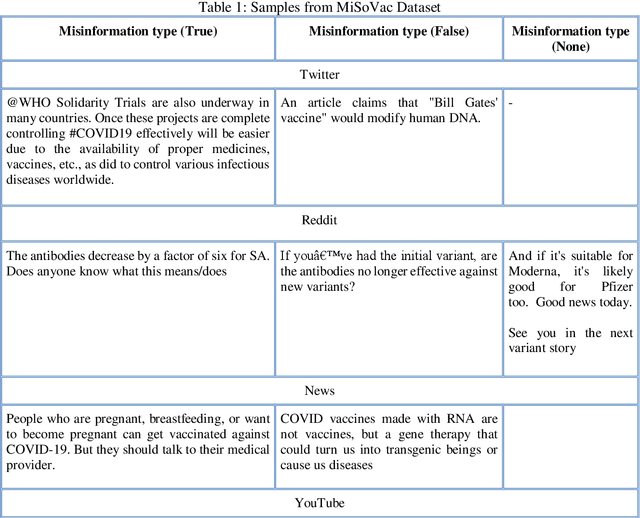
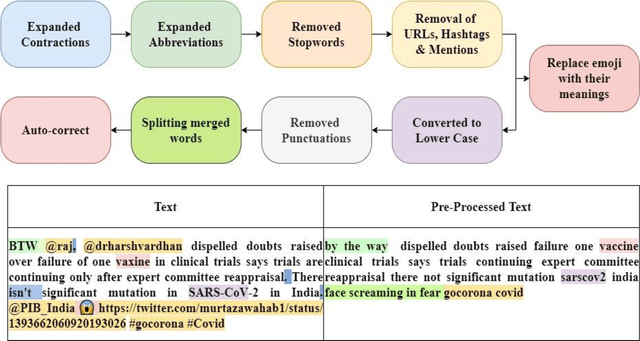
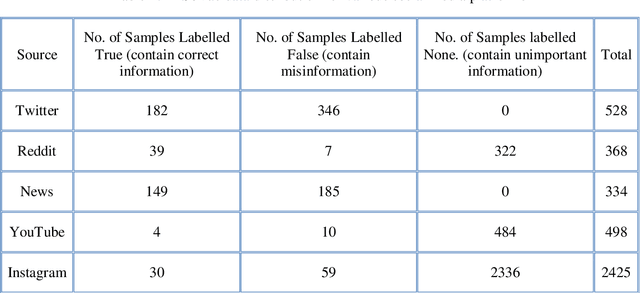
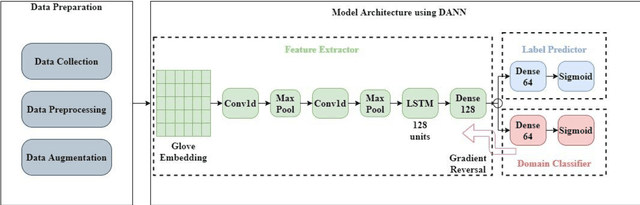
In this work, the integration of two machine learning approaches, namely domain adaptation and explainable AI, is proposed to address these two issues of generalized detection and explainability. Firstly the Domain Adversarial Neural Network (DANN) develops a generalized misinformation detector across multiple social media platforms DANN is employed to generate the classification results for test domains with relevant but unseen data. The DANN-based model, a traditional black-box model, cannot justify its outcome, i.e., the labels for the target domain. Hence a Local Interpretable Model-Agnostic Explanations (LIME) explainable AI model is applied to explain the outcome of the DANN mode. To demonstrate these two approaches and their integration for effective explainable generalized detection, COVID-19 misinformation is considered a case study. We experimented with two datasets, namely CoAID and MiSoVac, and compared results with and without DANN implementation. DANN significantly improves the accuracy measure F1 classification score and increases the accuracy and AUC performance. The results obtained show that the proposed framework performs well in the case of domain shift and can learn domain-invariant features while explaining the target labels with LIME implementation enabling trustworthy information processing and extraction to combat misinformation effectively.
Role of Artificial Intelligence in Detection of Hateful Speech for Hinglish Data on Social Media
May 11, 2021

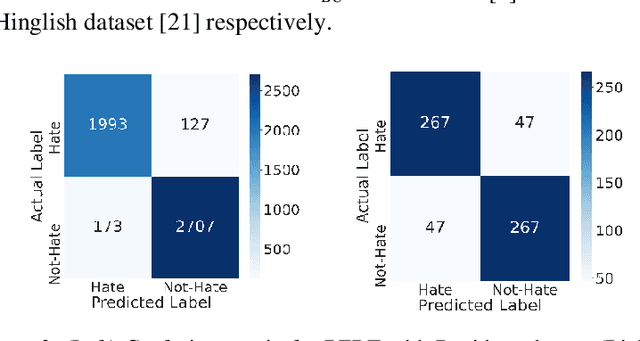

Social networking platforms provide a conduit to disseminate our ideas, views and thoughts and proliferate information. This has led to the amalgamation of English with natively spoken languages. Prevalence of Hindi-English code-mixed data (Hinglish) is on the rise with most of the urban population all over the world. Hate speech detection algorithms deployed by most social networking platforms are unable to filter out offensive and abusive content posted in these code-mixed languages. Thus, the worldwide hate speech detection rate of around 44% drops even more considering the content in Indian colloquial languages and slangs. In this paper, we propose a methodology for efficient detection of unstructured code-mix Hinglish language. Fine-tuning based approaches for Hindi-English code-mixed language are employed by utilizing contextual based embeddings such as ELMo (Embeddings for Language Models), FLAIR, and transformer-based BERT (Bidirectional Encoder Representations from Transformers). Our proposed approach is compared against the pre-existing methods and results are compared for various datasets. Our model outperforms the other methods and frameworks.