 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlant Species Recognition with Optimized 3D Polynomial Neural Networks and Variably Overlapping Time-Coherent Sliding Window
Mar 04, 2022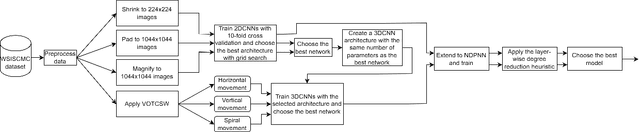
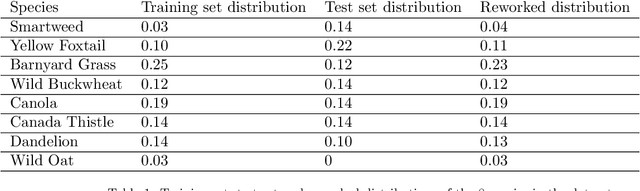
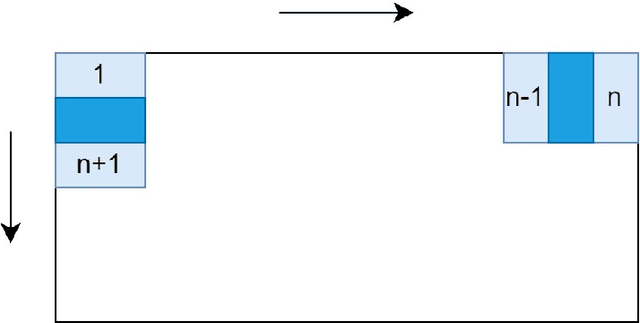
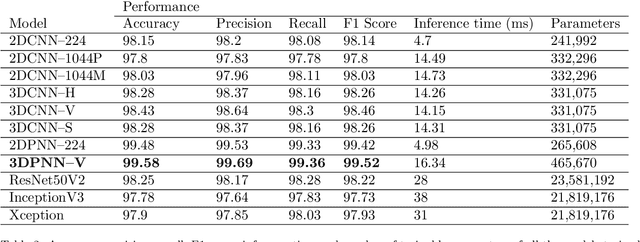
Recently, the EAGL-I system was developed to rapidly create massive labeled datasets of plants intended to be commonly used by farmers and researchers to create AI-driven solutions in agriculture. As a result, a publicly available plant species recognition dataset composed of 40,000 images with different sizes consisting of 8 plant species was created with the system in order to demonstrate its capabilities. This paper proposes a novel method, called Variably Overlapping Time-Coherent Sliding Window (VOTCSW), that transforms a dataset composed of images with variable size to a 3D representation with fixed size that is suitable for convolutional neural networks, and demonstrates that this representation is more informative than resizing the images of the dataset to a given size. We theoretically formalized the use cases of the method as well as its inherent properties and we proved that it has an oversampling and a regularization effect on the data. By combining the VOTCSW method with the 3D extension of a recently proposed machine learning model called 1-Dimensional Polynomial Neural Networks, we were able to create a model that achieved a state-of-the-art accuracy of 99.9% on the dataset created by the EAGL-I system, surpassing well-known architectures such as ResNet and Inception. In addition, we created a heuristic algorithm that enables the degree reduction of any pre-trained N-Dimensional Polynomial Neural Network and which compresses it without altering its performance, thus making the model faster and lighter. Furthermore, we established that the currently available dataset could not be used for machine learning in its present form, due to a substantial class imbalance between the training set and the test set. Hence, we created a specific preprocessing and a model development framework that enabled us to improve the accuracy from 49.23% to 99.9%.
Machine Learning of polymer types from the spectral signature of Raman spectroscopy microplastics data
Jan 14, 2022
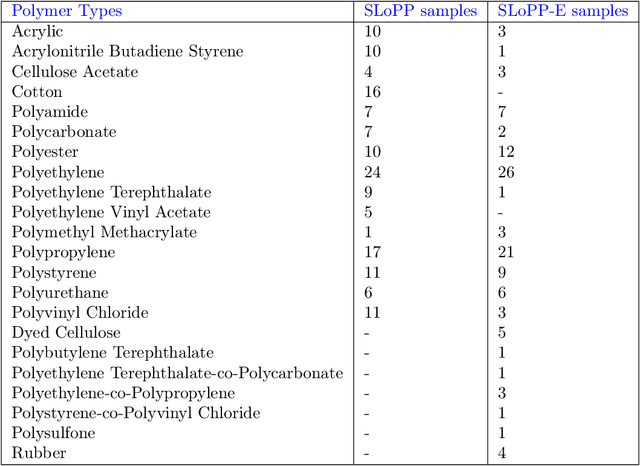
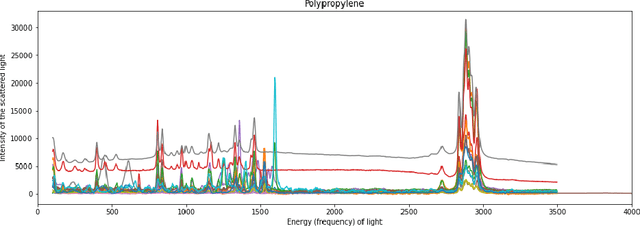

The tools and technology that are currently used to analyze chemical compound structures that identify polymer types in microplastics are not well-calibrated for environmentally weathered microplastics. Microplastics that have been degraded by environmental weathering factors can offer less analytic certainty than samples of microplastics that have not been exposed to weathering processes. Machine learning tools and techniques allow us to better calibrate the research tools for certainty in microplastics analysis. In this paper, we investigate whether the signatures (Raman shift values) are distinct enough such that well studied machine learning (ML) algorithms can learn to identify polymer types using a relatively small amount of labeled input data when the samples have not been impacted by environmental degradation. Several ML models were trained on a well-known repository, Spectral Libraries of Plastic Particles (SLOPP), that contain Raman shift and intensity results for a range of plastic particles, then tested on environmentally aged plastic particles (SloPP-E) consisting of 22 polymer types. After extensive preprocessing and augmentation, the trained random forest model was then tested on the SloPP-E dataset resulting in an improvement in classification accuracy of 93.81% from 89%.
Multimodal Co-learning: Challenges, Applications with Datasets, Recent Advances and Future Directions
Jul 29, 2021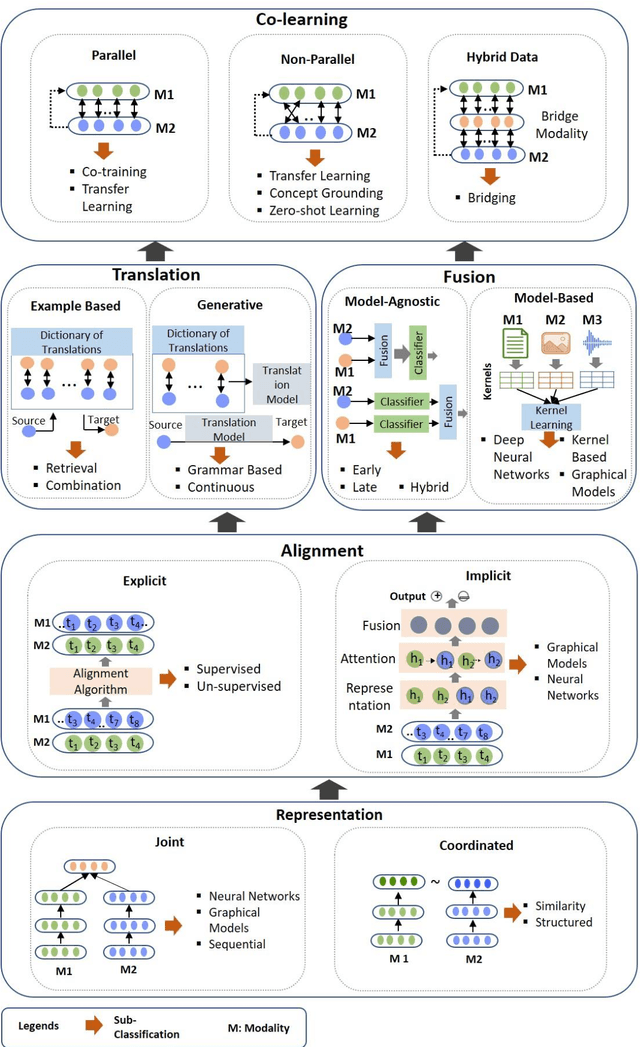
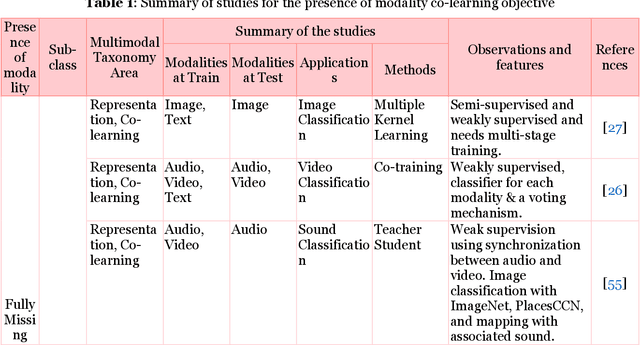
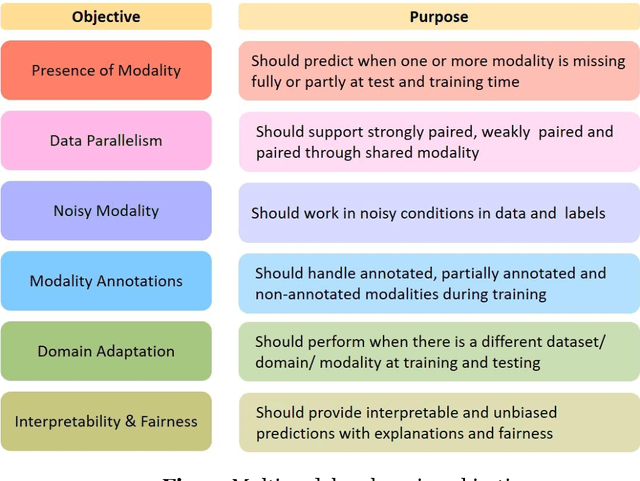
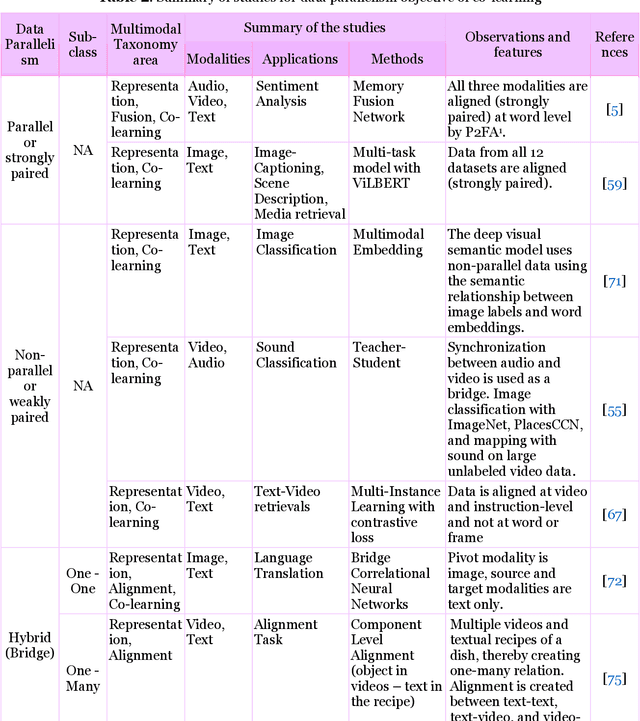
Multimodal deep learning systems which employ multiple modalities like text, image, audio, video, etc., are showing better performance in comparison with individual modalities (i.e., unimodal) systems. Multimodal machine learning involves multiple aspects: representation, translation, alignment, fusion, and co-learning. In the current state of multimodal machine learning, the assumptions are that all modalities are present, aligned, and noiseless during training and testing time. However, in real-world tasks, typically, it is observed that one or more modalities are missing, noisy, lacking annotated data, have unreliable labels, and are scarce in training or testing and or both. This challenge is addressed by a learning paradigm called multimodal co-learning. The modeling of a (resource-poor) modality is aided by exploiting knowledge from another (resource-rich) modality using transfer of knowledge between modalities, including their representations and predictive models. Co-learning being an emerging area, there are no dedicated reviews explicitly focusing on all challenges addressed by co-learning. To that end, in this work, we provide a comprehensive survey on the emerging area of multimodal co-learning that has not been explored in its entirety yet. We review implementations that overcome one or more co-learning challenges without explicitly considering them as co-learning challenges. We present the comprehensive taxonomy of multimodal co-learning based on the challenges addressed by co-learning and associated implementations. The various techniques employed to include the latest ones are reviewed along with some of the applications and datasets. Our final goal is to discuss challenges and perspectives along with the important ideas and directions for future work that we hope to be beneficial for the entire research community focusing on this exciting domain.
Fully Automated 2D and 3D Convolutional Neural Networks Pipeline for Video Segmentation and Myocardial Infarction Detection in Echocardiography
Mar 26, 2021

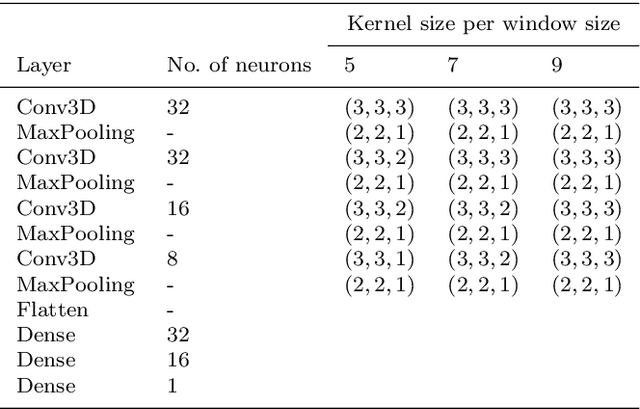
Cardiac imaging known as echocardiography is a non-invasive tool utilized to produce data including images and videos, which cardiologists use to diagnose cardiac abnormalities in general and myocardial infarction (MI) in particular. Echocardiography machines can deliver abundant amounts of data that need to be quickly analyzed by cardiologists to help them make a diagnosis and treat cardiac conditions. However, the acquired data quality varies depending on the acquisition conditions and the patient's responsiveness to the setup instructions. These constraints are challenging to doctors especially when patients are facing MI and their lives are at stake. In this paper, we propose an innovative real-time end-to-end fully automated model based on convolutional neural networks (CNN) to detect MI depending on regional wall motion abnormalities (RWMA) of the left ventricle (LV) from videos produced by echocardiography. Our model is implemented as a pipeline consisting of a 2D CNN that performs data preprocessing by segmenting the LV chamber from the apical four-chamber (A4C) view, followed by a 3D CNN that performs a binary classification to detect if the segmented echocardiography shows signs of MI. We trained both CNNs on a dataset composed of 165 echocardiography videos each acquired from a distinct patient. The 2D CNN achieved an accuracy of 97.18% on data segmentation while the 3D CNN achieved 90.9% of accuracy, 100% of precision and 95% of recall on MI detection. Our results demonstrate that creating a fully automated system for MI detection is feasible and propitious.
1-Dimensional polynomial neural networks for audio signal related problems
Sep 09, 2020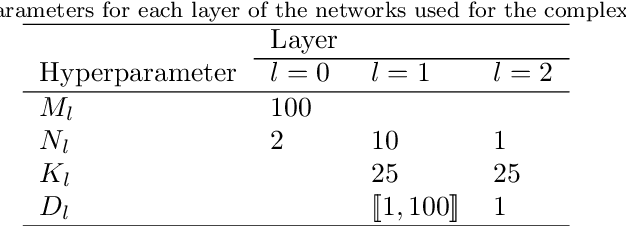
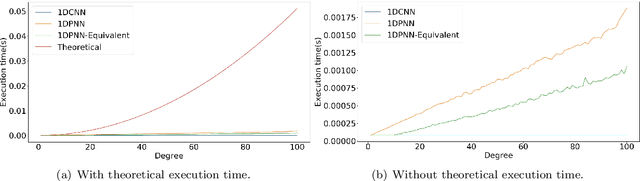
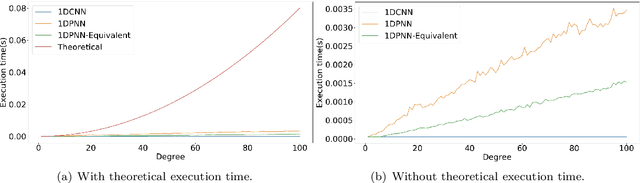

In addition to being extremely non-linear, modern problems require millions if not billions of parameters to solve or at least to get a good approximation of the solution, and neural networks are known to assimilate that complexity by deepening and widening their topology in order to increase the level of non-linearity needed for a better approximation. However, compact topologies are always preferred to deeper ones as they offer the advantage of using less computational units and less parameters. This compacity comes at the price of reduced non-linearity and thus, of limited solution search space. We propose the 1-Dimensional Polynomial Neural Network (1DPNN) model that uses automatic polynomial kernel estimation for 1-Dimensional Convolutional Neural Networks (1DCNNs) and that introduces a high degree of non-linearity from the first layer which can compensate the need for deep and/or wide topologies. We show that this non-linearity introduces more computational complexity but enables the model to yield better results than a regular 1DCNN that has the same number of training parameters on various classification and regression problems related to audio signals. The experiments were conducted on three publicly available datasets and demonstrate that the proposed model can achieve a much faster convergence than a 1DCNN on the tackled regression problems.
Near real-time map building with multi-class image set labelling and classification of road conditions using convolutional neural networks
Jan 27, 2020
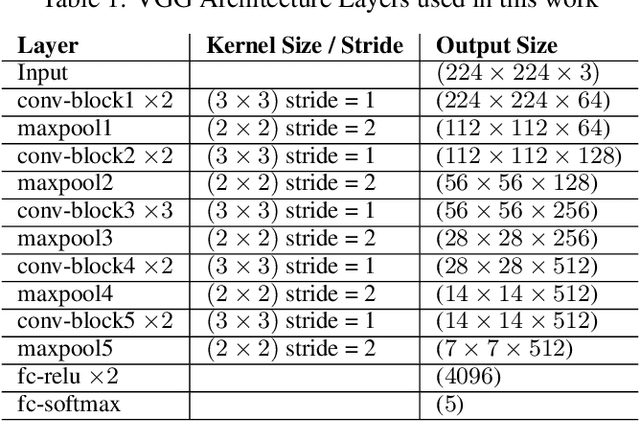
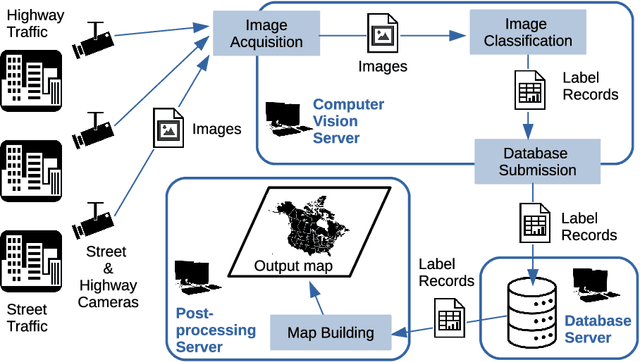
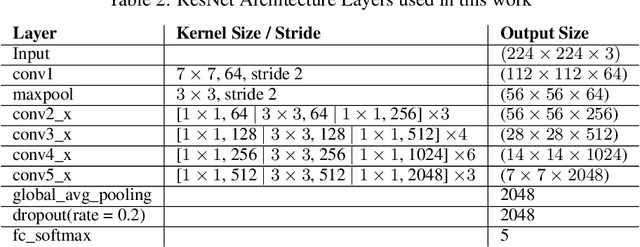
Weather is an important factor affecting transportation and road safety. In this paper, we leverage state-of-the-art convolutional neural networks in labelling images taken by street and highway cameras located across across North America. Road camera snapshots were used in experiments with multiple deep learning frameworks to classify images by road condition. The training data for these experiments used images labelled as dry, wet, snow/ice, poor, and offline. The experiments tested different configurations of six convolutional neural networks (VGG-16, ResNet50, Xception, InceptionResNetV2, EfficientNet-B0 and EfficientNet-B4) to assess their suitability to this problem. The precision, accuracy, and recall were measured for each framework configuration. In addition, the training sets were varied both in overall size and by size of individual classes. The final training set included 47,000 images labelled using the five aforementioned classes. The EfficientNet-B4 framework was found to be most suitable to this problem, achieving validation accuracy of 90.6%, although EfficientNet-B0 achieved an accuracy of 90.3% with half the execution time. It was observed that VGG-16 with transfer learning proved to be very useful for data acquisition and pseudo-labelling with limited hardware resources, throughout this project. The EfficientNet-B4 framework was then placed into a real-time production environment, where images could be classified in real-time on an ongoing basis. The classified images were then used to construct a map showing real-time road conditions at various camera locations across North America. The choice of these frameworks and our analysis take into account unique requirements of real-time map building functions. A detailed analysis of the process of semi-automated dataset labelling using these frameworks is also presented in this paper.