 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Educational AI Agents
Mar 12, 2026While scaling laws for Large Language Models (LLMs) have been extensively studied along dimensions of model parameters, training data, and compute, the scaling behavior of LLM-based educational agents remains unexplored. We propose that educational agent capability scales not merely with the underlying model size, but through structured dimensions that we collectively term the Agent Scaling Law: role definition clarity, skill depth, tool completeness, runtime capability, and educator expertise injection. Central to this framework is AgentProfile, a structured JSON-based specification that serves as the mechanism enabling systematic capability growth of educational agents. We present EduClaw, a profile-driven multi-agent platform that operationalizes this scaling law, demonstrating its effectiveness through the construction and deployment of 330+ educational agent profiles encompassing 1,100+ skill modules across K-12 subjects. Our empirical observations suggest that educational agent performance scales predictably with profile structural richness. We identify two complementary scaling axes -- Tool Scaling and Skill Scaling -- as future directions, arguing that the path to more capable educational AI lies not solely in larger models, but in stronger structured capability systems.
Automating Skill Acquisition through Large-Scale Mining of Open-Source Agentic Repositories: A Framework for Multi-Agent Procedural Knowledge Extraction
Mar 12, 2026The transition from monolithic large language models (LLMs) to modular, skill-equipped agents represents a fundamental architectural shift in artificial intelligence deployment. While general-purpose models demonstrate remarkable breadth in declarative knowledge, their utility in autonomous workflows is frequently constrained by insufficient specialized procedural expertise. This report investigates a systematic framework for automated acquisition of high-quality agent skills through mining of open-source repositories on platforms such as GitHub. We focus on the extraction of visualization and educational capabilities from state-of-the-art systems including TheoremExplainAgent and Code2Video, both utilizing the Manim mathematical animation engine. The framework encompasses repository structural analysis, semantic skill identification through dense retrieval, and translation to the standardized SKILL.md format. We demonstrate that systematic extraction from agentic repositories, combined with rigorous security governance and multi-dimensional evaluation metrics, enables scalable acquisition of procedural knowledge that augments LLM capabilities without requiring model retraining. Our analysis reveals that agent-generated educational content can achieve 40\% gains in knowledge transfer efficiency while maintaining pedagogical quality comparable to human-crafted tutorials.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
MetaCon: Unified Predictive Segments System with Trillion Concept Meta-Learning
Mar 09, 2022
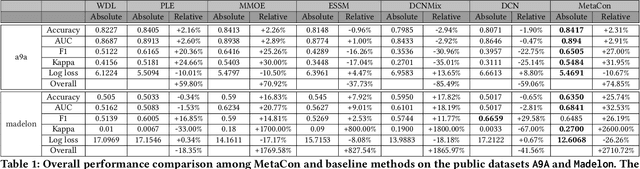
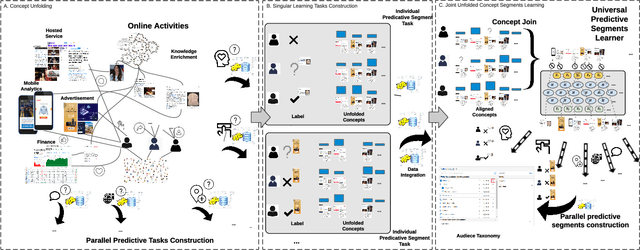
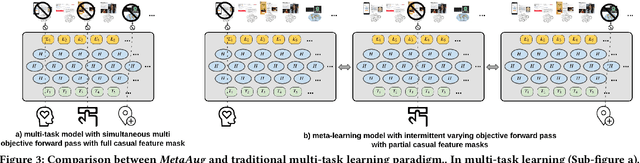
Accurate understanding of users in terms of predicative segments play an essential role in the day to day operation of modern internet enterprises. Nevertheless, there are significant challenges that limit the quality of data, especially on long tail predictive tasks. In this work, we present MetaCon, our unified predicative segments system with scalable, trillion concepts meta learning that addresses these challenges. It builds on top of a flat concept representation that summarizes entities' heterogeneous digital footprint, jointly considers the entire spectrum of predicative tasks as a single learning task, and leverages principled meta learning approach with efficient first order meta-optimization procedure under a provable performance guarantee in order to solve the learning task. Experiments on both proprietary production datasets and public structured learning tasks demonstrate that MetaCon can lead to substantial improvements over state of the art recommendation and ranking approaches.
SuperCone: Modeling Heterogeneous Experts with Concept Meta-learning for Unified Predictive Segments System
Mar 09, 2022



Understanding users through predicative segments play an essential role for modern enterprises for more efficient and efficient information exchange. For example, by predicting whether a user has particular interest in a particular area of sports or entertainment, we can better serve the user with more relevant and tailored content. However, there exists a large number of long tail prediction tasks that are hard to capture by off the shelf model architectures due to data scarcity and task heterogeneity. In this work, we present SuperCone, our unified predicative segments system that addresses the above challenges. It builds on top of a flat concept representation that summarizes each user's heterogeneous digital footprints, and uniformly models each of the prediction task using an approach called "super learning ", that is, combining prediction models with diverse architectures or learning method that are not compatible with each other or even completely unknown. Following this, we provide end to end deep learning architecture design that flexibly learns to attend to best suited heterogeneous experts while at the same time learns deep representations of the input concepts that augments the above experts by capturing unique signal. Experiments show that SuperCone can outperform state-of-the-art recommendation and ranking algorithms on a wide range of predicative segment tasks, as well as several public structured data learning benchmarks.