 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulating Vehicle 3D Shapes through Latent Space Editing
Oct 31, 2024Although 3D object editing has the potential to significantly influence various industries, recent research in 3D generation and editing has primarily focused on converting text and images into 3D models, often overlooking the need for fine-grained control over the editing of existing 3D objects. This paper introduces a framework that employs a pre-trained regressor, enabling continuous, precise, attribute-specific modifications to both the stylistic and geometric attributes of vehicle 3D models. Our method not only preserves the inherent identity of vehicle 3D objects, but also supports multi-attribute editing, allowing for extensive customization without compromising the model's structural integrity. Experimental results demonstrate the efficacy of our approach in achieving detailed edits on various vehicle 3D models.
Improving the Reliability of Semantic Segmentation of Medical Images by Uncertainty Modeling with Bayesian Deep Networks and Curriculum Learning
Aug 26, 2021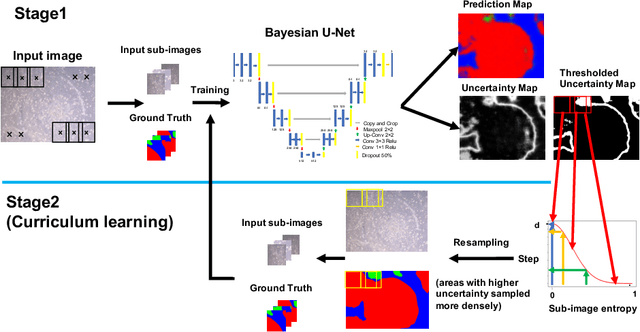
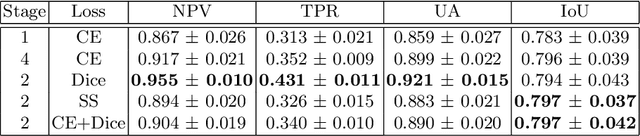

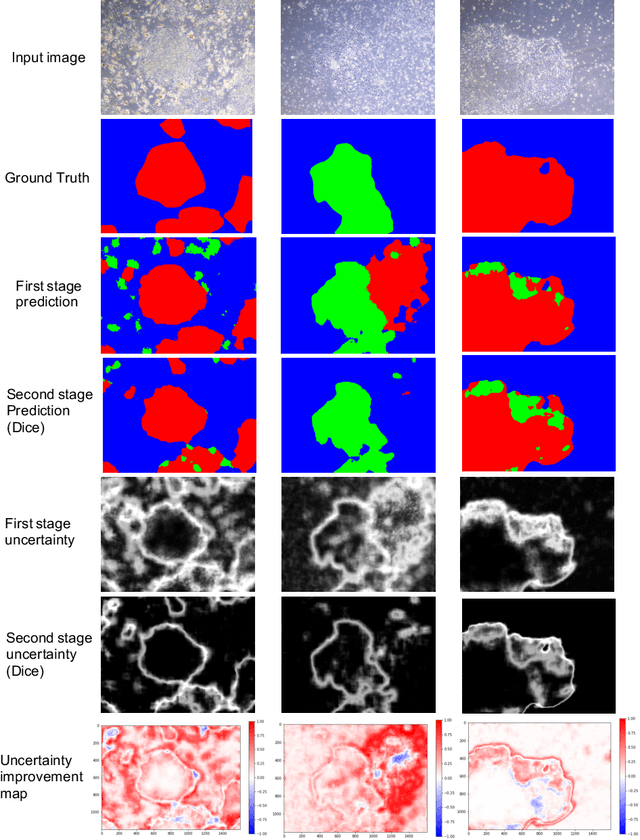
In this paper we propose a novel method which leverages the uncertainty measures provided by Bayesian deep networks through curriculum learning so that the uncertainty estimates are fed back to the system to resample the training data more densely in areas where uncertainty is high. We show in the concrete setting of a semantic segmentation task (iPS cell colony segmentation) that the proposed system is able to increase significantly the reliability of the model.
Which visual questions are difficult to answer? Analysis with Entropy of Answer Distributions
Apr 12, 2020
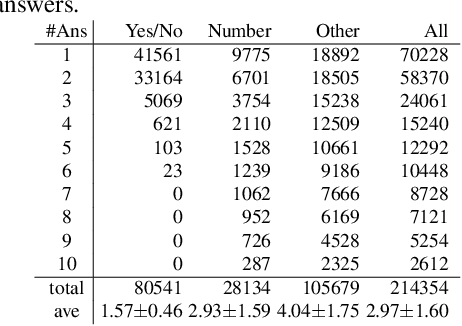
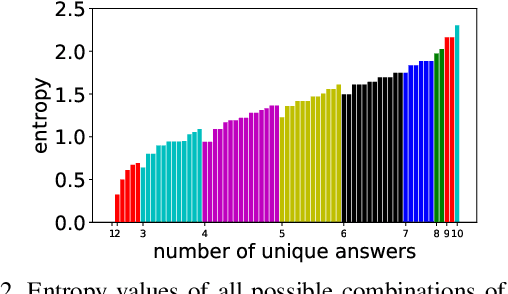
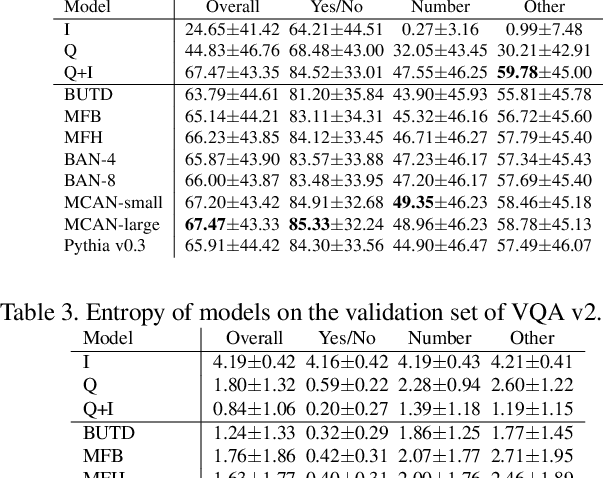
We propose a novel approach to identify the difficulty of visual questions for Visual Question Answering (VQA) without direct supervision or annotations to the difficulty. Prior works have considered the diversity of ground-truth answers of human annotators. In contrast, we analyze the difficulty of visual questions based on the behavior of multiple different VQA models. We propose to cluster the entropy values of the predicted answer distributions obtained by three different models: a baseline method that takes as input images and questions, and two variants that take as input images only and questions only. We use a simple k-means to cluster the visual questions of the VQA v2 validation set. Then we use state-of-the-art methods to determine the accuracy and the entropy of the answer distributions for each cluster. A benefit of the proposed method is that no annotation of the difficulty is required, because the accuracy of each cluster reflects the difficulty of visual questions that belong to it. Our approach can identify clusters of difficult visual questions that are not answered correctly by state-of-the-art methods. Detailed analysis on the VQA v2 dataset reveals that 1) all methods show poor performances on the most difficult cluster (about 10% accuracy), 2) as the cluster difficulty increases, the answers predicted by the different methods begin to differ, and 3) the values of cluster entropy are highly correlated with the cluster accuracy. We show that our approach has the advantage of being able to assess the difficulty of visual questions without ground-truth (i.e. the test set of VQA v2) by assigning them to one of the clusters. We expect that this can stimulate the development of novel directions of research and new algorithms. Clustering results are available online at https://github.com/tttamaki/vqd .
Rephrasing visual questions by specifying the entropy of the answer distribution
Apr 10, 2020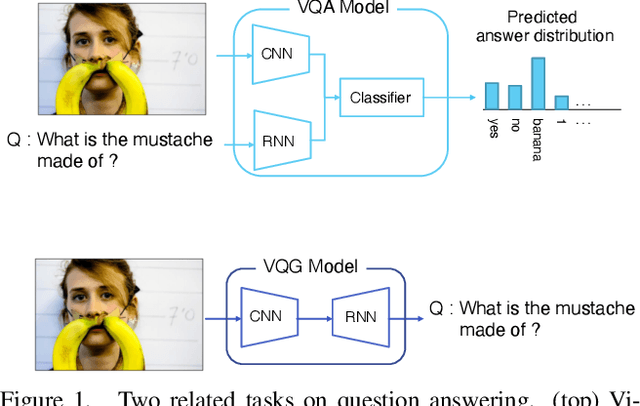


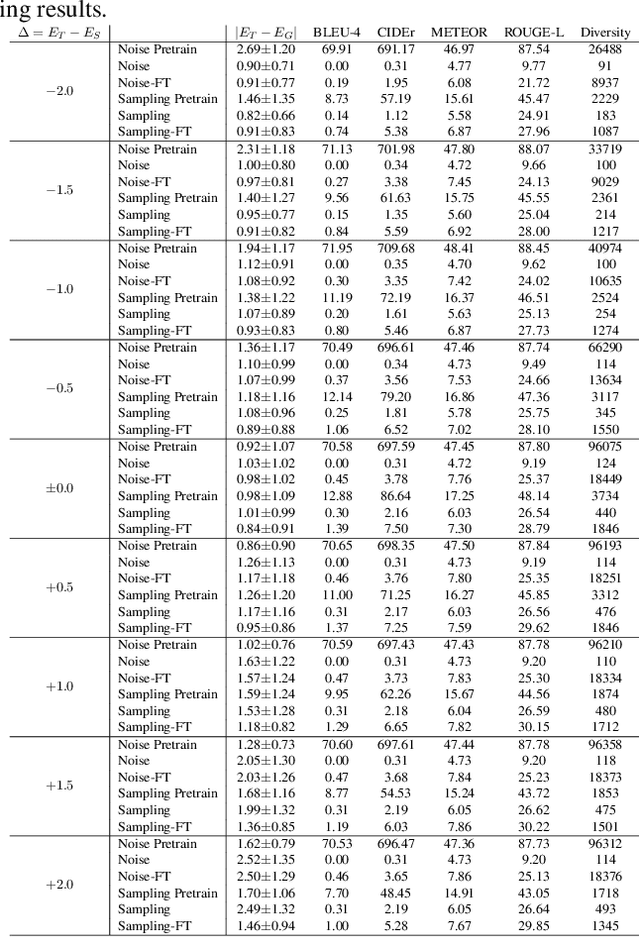
Visual question answering (VQA) is a task of answering a visual question that is a pair of question and image. Some visual questions are ambiguous and some are clear, and it may be appropriate to change the ambiguity of questions from situation to situation. However, this issue has not been addressed by any prior work. We propose a novel task, rephrasing the questions by controlling the ambiguity of the questions. The ambiguity of a visual question is defined by the use of the entropy of the answer distribution predicted by a VQA model. The proposed model rephrases a source question given with an image so that the rephrased question has the ambiguity (or entropy) specified by users. We propose two learning strategies to train the proposed model with the VQA v2 dataset, which has no ambiguity information. We demonstrate the advantage of our approach that can control the ambiguity of the rephrased questions, and an interesting observation that it is harder to increase than to reduce ambiguity.
On-line non-overlapping camera calibration net
Feb 19, 2020

We propose an easy-to-use non-overlapping camera calibration method. First, successive images are fed to a PoseNet-based network to obtain ego-motion of cameras between frames. Next, the pose between cameras are estimated. Instead of using a batch method, we propose an on-line method of the inter-camera pose estimation. Furthermore, we implement the entire procedure on a computation graph. Experiments with simulations and the KITTI dataset show the proposed method to be effective in simulation.
* 7 pages
Improved Activity Forecasting for Generating Trajectories
Dec 12, 2019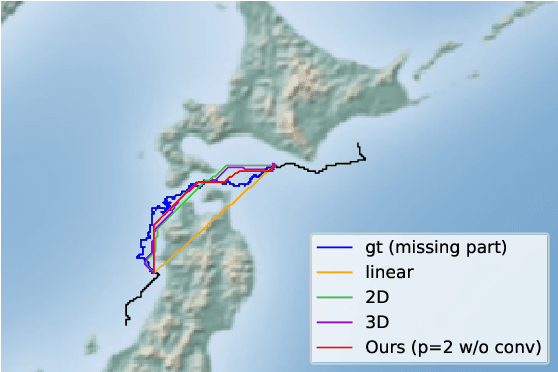
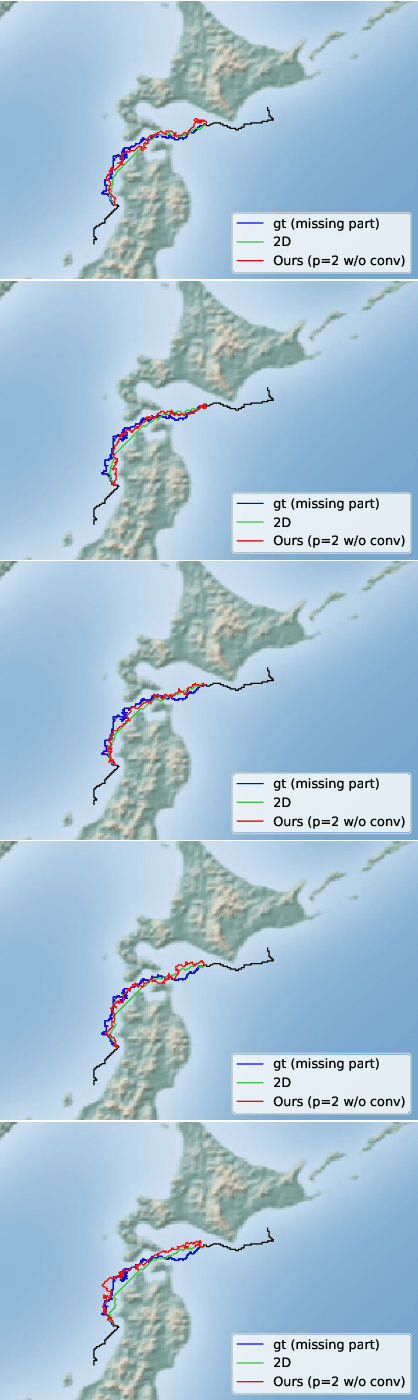
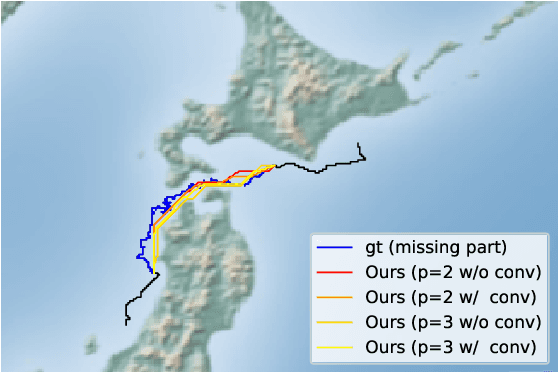
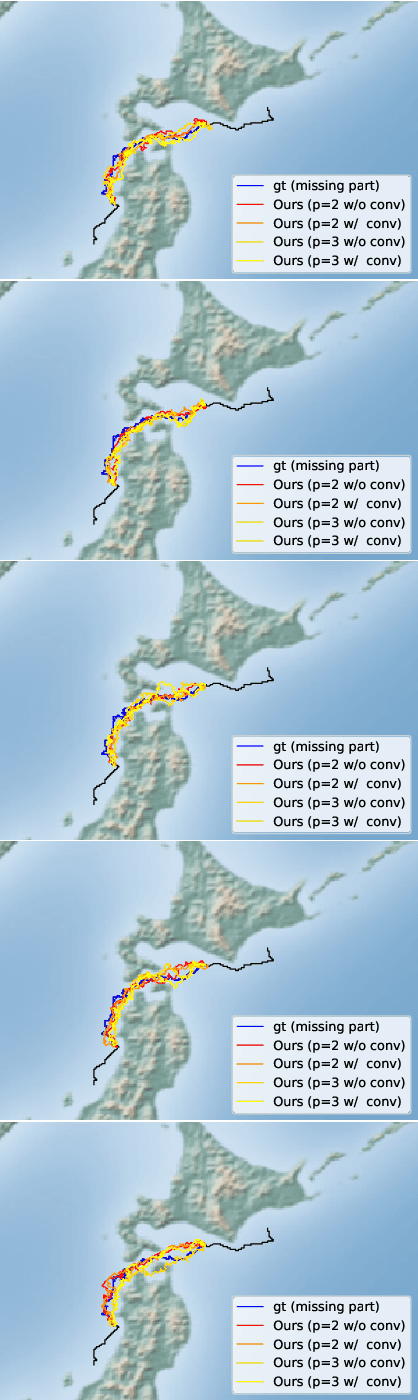
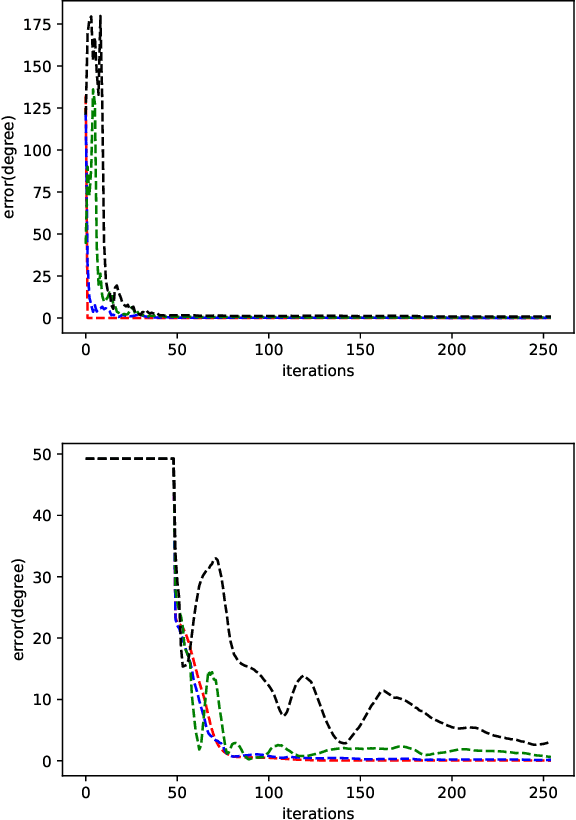
An efficient inverse reinforcement learning for generating trajectories is proposed based of 2D and 3D activity forecasting. We modify reward function with $L_p$ norm and propose convolution into value iteration steps, which is called convolutional value iteration. Experimental results with seabird trajectories (43 for training and 10 for test), our method is best in terms of MHD error and performs fastest. Generated trajectories for interpolating missing parts of trajectories look much similar to real seabird trajectories than those by the previous works.
Semantic segmentation of trajectories with improved agent models for pedestrian behavior analysis
Dec 12, 2019



In this paper, we propose a method for semantic segmentation of pedestrian trajectories based on pedestrian behavior models, or agents. The agents model the dynamics of pedestrian movements in two-dimensional space using a linear dynamics model and common start and goal locations of trajectories. First, agent models are estimated from the trajectories obtained from image sequences. Our method is built on top of the Mixture model of Dynamic pedestrian Agents (MDA); however, the MDA's trajectory modeling and estimation are improved. Then, the trajectories are divided into semantically meaningful segments. The subsegments of a trajectory are modeled by applying a hidden Markov model using the estimated agent models. Experimental results with a real trajectory dataset show the effectiveness of the proposed method as compared to the well-known classical Ramer-Douglas-Peucker algorithm and also to the original MDA model.
Biomedical Image Segmentation by Retina-like Sequential Attention Mechanism Using Only A Few Training Images
Sep 27, 2019



In this paper we propose a novel deep learning-based algorithm for biomedical image segmentation which uses a sequential attention mechanism able to shift the focus of attention across the image in a selective way, allowing subareas which are more difficult to classify to be processed at increased resolution. The spatial distribution of class information in each subarea is learned using a retina-like representation where resolution decreases with distance from the center of attention. The final segmentation is achieved by averaging class predictions over overlapping subareas, utilizing the power of ensemble learning to increase segmentation accuracy. Experimental results for semantic segmentation task for which only a few training images are available show that a CNN using the proposed method outperforms both a patch-based classification CNN and a fully convolutional-based method.
Semantic segmentation of trajectories with agent models
Feb 27, 2018



In many cases, such as trajectories clustering and classification, we often divide a trajectory into segments as preprocessing. In this paper, we propose a trajectory semantic segmentation method based on learned behavior models. In the proposed method, we learn some behavior models from video sequences. Next, using learned behavior models and a hidden Markov model, we segment a trajectory into semantic segments. Comparing with the Ramer-Douglas-Peucker algorithm, we show the effectiveness of the proposed method.
Domain Adaptation with L2 constraints for classifying images from different endoscope systems
Feb 02, 2018


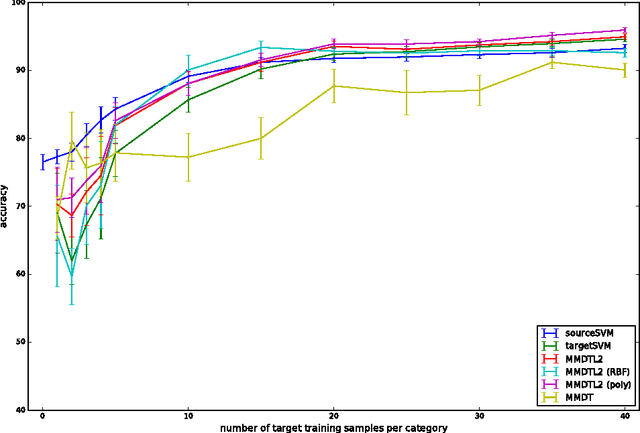
This paper proposes a method for domain adaptation that extends the maximum margin domain transfer (MMDT) proposed by Hoffman et al., by introducing L2 distance constraints between samples of different domains; thus, our method is denoted as MMDTL2. Motivated by the differences between the images taken by narrow band imaging (NBI) endoscopic devices, we utilize different NBI devices as different domains and estimate the transformations between samples of different domains, i.e., image samples taken by different NBI endoscope systems. We first formulate the problem in the primal form, and then derive the dual form with much lesser computational costs as compared to the naive approach. From our experimental results using NBI image datasets from two different NBI endoscopic devices, we find that MMDTL2 is better than MMDT and also support vector machines without adaptation, especially when NBI image features are high-dimensional and the per-class training samples are greater than 20.