 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich visual questions are difficult to answer? Analysis with Entropy of Answer Distributions
Paper and Code

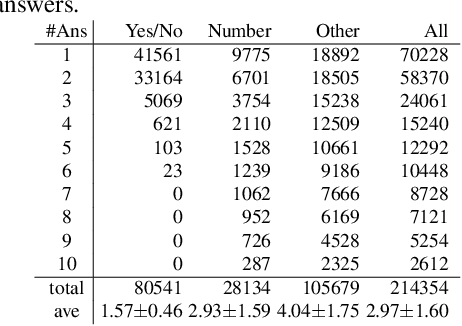
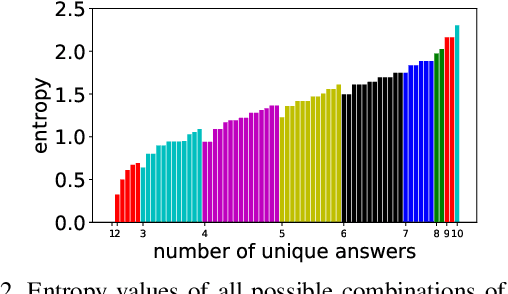
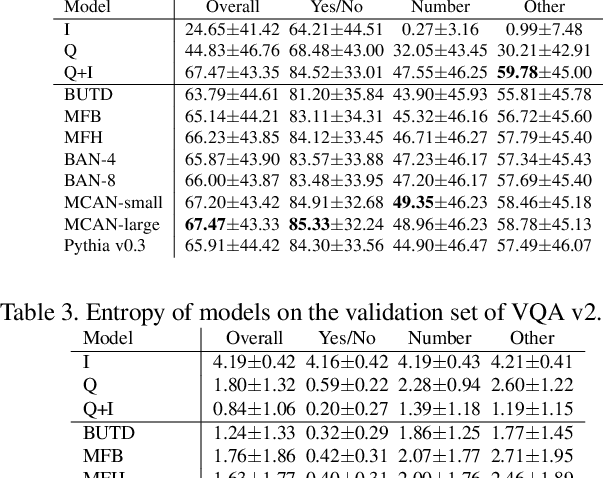
We propose a novel approach to identify the difficulty of visual questions for Visual Question Answering (VQA) without direct supervision or annotations to the difficulty. Prior works have considered the diversity of ground-truth answers of human annotators. In contrast, we analyze the difficulty of visual questions based on the behavior of multiple different VQA models. We propose to cluster the entropy values of the predicted answer distributions obtained by three different models: a baseline method that takes as input images and questions, and two variants that take as input images only and questions only. We use a simple k-means to cluster the visual questions of the VQA v2 validation set. Then we use state-of-the-art methods to determine the accuracy and the entropy of the answer distributions for each cluster. A benefit of the proposed method is that no annotation of the difficulty is required, because the accuracy of each cluster reflects the difficulty of visual questions that belong to it. Our approach can identify clusters of difficult visual questions that are not answered correctly by state-of-the-art methods. Detailed analysis on the VQA v2 dataset reveals that 1) all methods show poor performances on the most difficult cluster (about 10% accuracy), 2) as the cluster difficulty increases, the answers predicted by the different methods begin to differ, and 3) the values of cluster entropy are highly correlated with the cluster accuracy. We show that our approach has the advantage of being able to assess the difficulty of visual questions without ground-truth (i.e. the test set of VQA v2) by assigning them to one of the clusters. We expect that this can stimulate the development of novel directions of research and new algorithms. Clustering results are available online at https://github.com/tttamaki/vqd .