 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflective Dialogue between Teacher and Solver Agents for Video Question Answering
May 27, 2026Various approaches have been proposed to adapt Vision-Language Models (VLMs) to specialized domains for Video Question Answering, including fine-tuning and in-context learning. However, acquiring task-specific knowledge at the inference phase from only a small labeled support set without fine-tuning remains a challenge. In this paper, we propose a method that achieves adaptation solely through inference-time context injection. Our method first constructs a Reflective Dialogue (RD) -- a multi-turn conversation between two agents, in which Teacher poses each support question and delivers correctness feedback, and Solver answers and provides visual grounding explanations (or reflections) for both correct and incorrect answers. This dialogue history is then used as context at the inference phase. Experiments on the EgoCross benchmark demonstrate that our method outperforms both a baseline zero-shot setting and a standard in-context learning approach that passes support set examples directly, achieving 3rd place in the Open-source Track of the 1st Cross-Domain EgoCross Challenge at the CVPR 2026 EgoVis Workshop, for which this paper also serves as a technical report.
BFMD: A Full-Match Badminton Dense Dataset for Dense Shot Captioning
Mar 26, 2026Understanding tactical dynamics in badminton requires analyzing entire matches rather than isolated clips. However, existing badminton datasets mainly focus on short clips or task-specific annotations and rarely provide full-match data with dense multimodal annotations. This limitation makes it difficult to generate accurate shot captions and perform match-level analysis. To address this limitation, we introduce the first Badminton Full Match Dense (BFMD) dataset, with 19 broadcast matches (including both singles and doubles) covering over 20 hours of play, comprising 1,687 rallies and 16,751 hit events, each annotated with a shot caption. The dataset provides hierarchical annotations including match segments, rally events, and dense rally-level multimodal annotations such as shot types, shuttle trajectories, player pose keypoints, and shot captions. We develop a VideoMAE-based multimodal captioning framework with a Semantic Feedback mechanism that leverages shot semantics to guide caption generation and improve semantic consistency. Experimental results demonstrate that multimodal modeling and semantic feedback improve shot caption quality over RGB-only baselines. We further showcase the potential of BFMD by analyzing the temporal evolution of tactical patterns across full matches.
M3DDM+: An improved video outpainting by a modified masking strategy
Jan 16, 2026M3DDM provides a computationally efficient framework for video outpainting via latent diffusion modeling. However, it exhibits significant quality degradation -- manifested as spatial blur and temporal inconsistency -- under challenging scenarios characterized by limited camera motion or large outpainting regions, where inter-frame information is limited. We identify the cause as a training-inference mismatch in the masking strategy: M3DDM's training applies random mask directions and widths across frames, whereas inference requires consistent directional outpainting throughout the video. To address this, we propose M3DDM+, which applies uniform mask direction and width across all frames during training, followed by fine-tuning of the pretrained M3DDM model. Experiments demonstrate that M3DDM+ substantially improves visual fidelity and temporal coherence in information-limited scenarios while maintaining computational efficiency. The code is available at https://github.com/tamaki-lab/M3DDM-Plus.
Action tube generation by person query matching for spatio-temporal action detection
Mar 17, 2025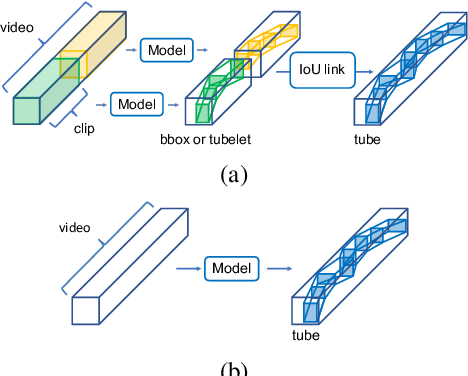
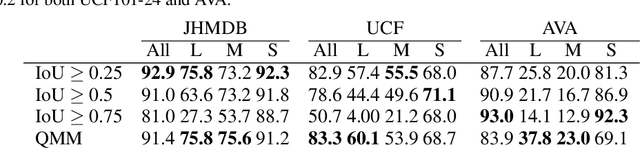
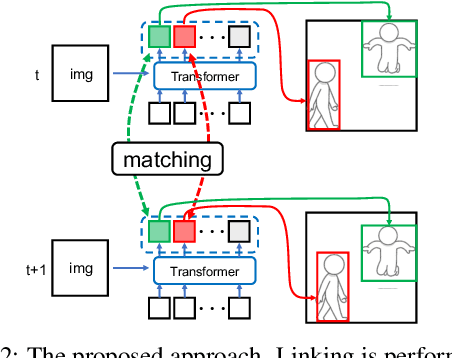
This paper proposes a method for spatio-temporal action detection (STAD) that directly generates action tubes from the original video without relying on post-processing steps such as IoU-based linking and clip splitting. Our approach applies query-based detection (DETR) to each frame and matches DETR queries to link the same person across frames. We introduce the Query Matching Module (QMM), which uses metric learning to bring queries for the same person closer together across frames compared to queries for different people. Action classes are predicted using the sequence of queries obtained from QMM matching, allowing for variable-length inputs from videos longer than a single clip. Experimental results on JHMDB, UCF101-24, and AVA datasets demonstrate that our method performs well for large position changes of people while offering superior computational efficiency and lower resource requirements.
Shift and matching queries for video semantic segmentation
Oct 10, 2024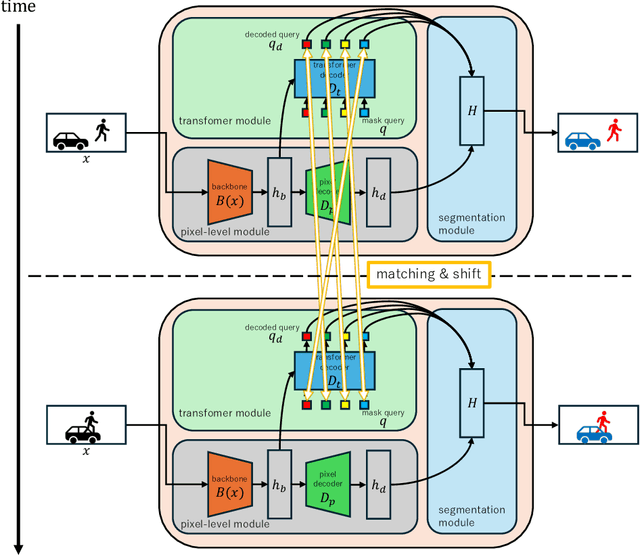
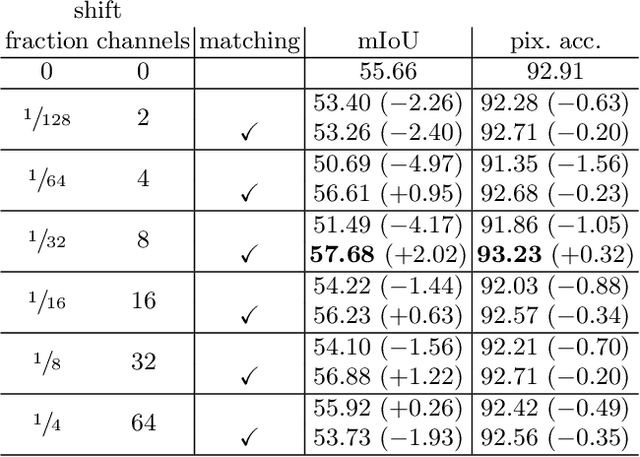
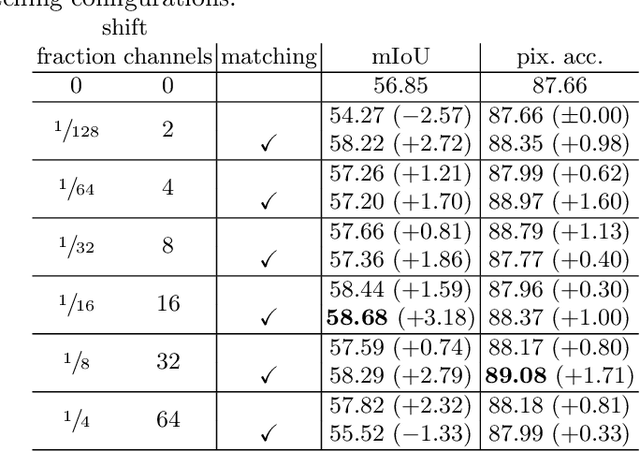

Video segmentation is a popular task, but applying image segmentation models frame-by-frame to videos does not preserve temporal consistency. In this paper, we propose a method to extend a query-based image segmentation model to video using feature shift and query matching. The method uses a query-based architecture, where decoded queries represent segmentation masks. These queries should be matched before performing the feature shift to ensure that the shifted queries represent the same mask across different frames. Experimental results on CityScapes-VPS and VSPW show significant improvements from the baselines, highlighting the method's effectiveness in enhancing segmentation quality while efficiently reusing pre-trained weights.
Query matching for spatio-temporal action detection with query-based object detector
Sep 27, 2024



In this paper, we propose a method that extends the query-based object detection model, DETR, to spatio-temporal action detection, which requires maintaining temporal consistency in videos. Our proposed method applies DETR to each frame and uses feature shift to incorporate temporal information. However, DETR's object queries in each frame may correspond to different objects, making a simple feature shift ineffective. To overcome this issue, we propose query matching across different frames, ensuring that queries for the same object are matched and used for the feature shift. Experimental results show that performance on the JHMDB21 dataset improves significantly when query features are shifted using the proposed query matching.
Online pre-training with long-form videos
Aug 28, 2024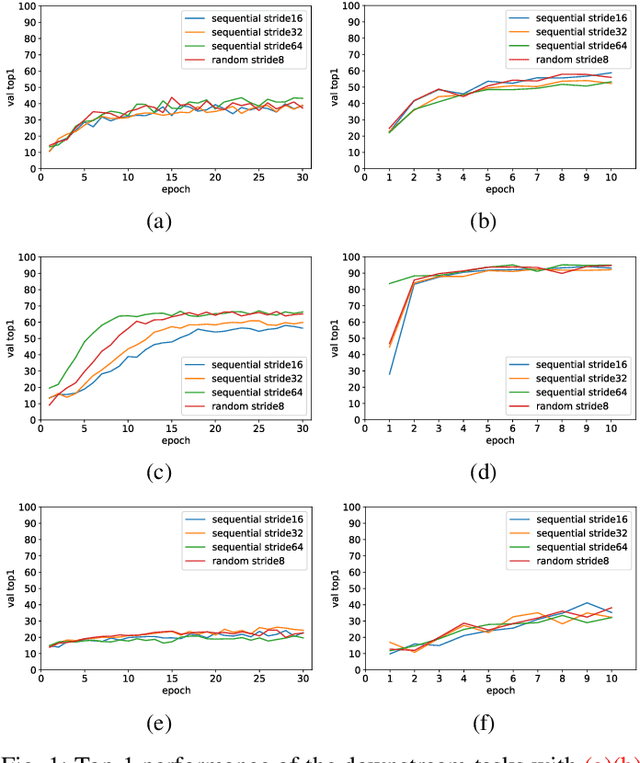
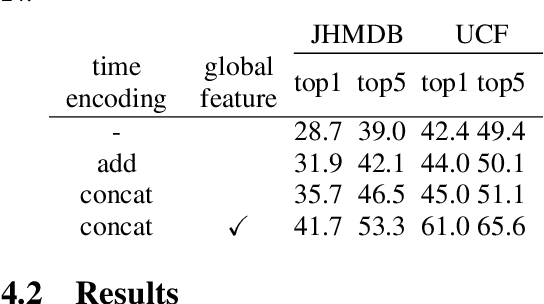
In this study, we investigate the impact of online pre-training with continuous video clips. We will examine three methods for pre-training (masked image modeling, contrastive learning, and knowledge distillation), and assess the performance on downstream action recognition tasks. As a result, online pre-training with contrast learning showed the highest performance in downstream tasks. Our findings suggest that learning from long-form videos can be helpful for action recognition with short videos.
Fine-grained length controllable video captioning with ordinal embeddings
Aug 27, 2024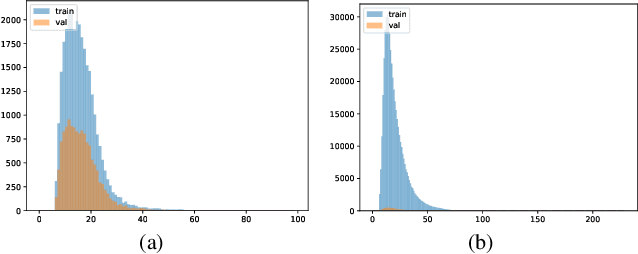

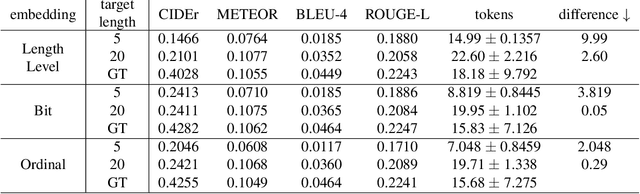
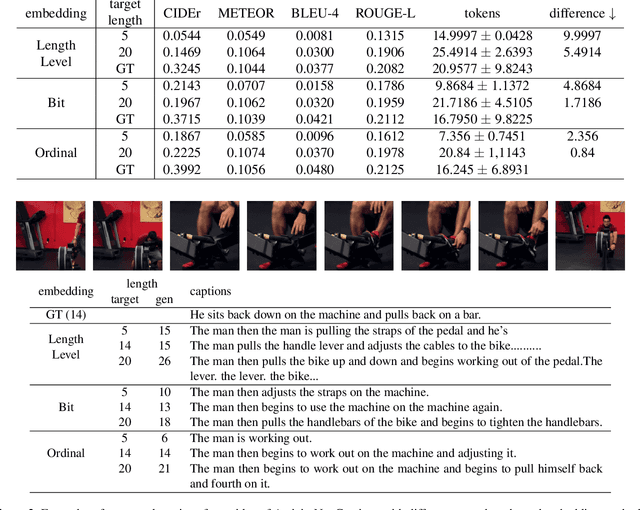
This paper proposes a method for video captioning that controls the length of generated captions. Previous work on length control often had few levels for expressing length. In this study, we propose two methods of length embedding for fine-grained length control. A traditional embedding method is linear, using a one-hot vector and an embedding matrix. In this study, we propose methods that represent length in multi-hot vectors. One is bit embedding that expresses length in bit representation, and the other is ordinal embedding that uses the binary representation often used in ordinal regression. These length representations of multi-hot vectors are converted into length embedding by a nonlinear MLP. This method allows for not only the length control of caption sentences but also the control of the time when reading the caption. Experiments using ActivityNet Captions and Spoken Moments in Time show that the proposed method effectively controls the length of the generated captions. Analysis of the embedding vectors with ICA shows that length and semantics were learned separately, demonstrating the effectiveness of the proposed embedding methods.
Multi-model learning by sequential reading of untrimmed videos for action recognition
Jan 26, 2024We propose a new method for learning videos by aggregating multiple models by sequentially extracting video clips from untrimmed video. The proposed method reduces the correlation between clips by feeding clips to multiple models in turn and synchronizes these models through federated learning. Experimental results show that the proposed method improves the performance compared to the no synchronization.
S3Aug: Segmentation, Sampling, and Shift for Action Recognition
Oct 23, 2023



Action recognition is a well-established area of research in computer vision. In this paper, we propose S3Aug, a video data augmenatation for action recognition. Unlike conventional video data augmentation methods that involve cutting and pasting regions from two videos, the proposed method generates new videos from a single training video through segmentation and label-to-image transformation. Furthermore, the proposed method modifies certain categories of label images by sampling to generate a variety of videos, and shifts intermediate features to enhance the temporal coherency between frames of the generate videos. Experimental results on the UCF101, HMDB51, and Mimetics datasets demonstrate the effectiveness of the proposed method, paricularlly for out-of-context videos of the Mimetics dataset.