 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Performance Evaluation of Action Recognition Models on Transcoded Low Quality Videos
Apr 19, 2022



In the design of action recognition models, the quality of videos in the dataset is an important issue, however the trade-off between the quality and performance is often ignored. In general, action recognition models are trained and tested on high-quality videos, but in actual situations where action recognition models are deployed, sometimes it might not be assumed that the input videos are of high quality. In this study, we report qualitative evaluations of action recognition models for the quality degradation associated with transcoding by JPEG and H.264/AVC. Experimental results are shown for evaluating the performance of pre-trained models on the transcoded validation videos of Kinetics400. The models are also trained on the transcoded training videos. From these results, we quantitatively show the degree of degradation of the model performance with respect to the degradation of the video quality.
Vision Transformer with Cross-attention by Temporal Shift for Efficient Action Recognition
Apr 01, 2022

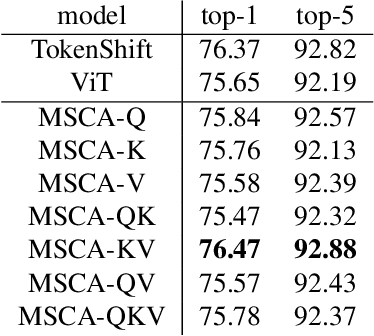

We propose Multi-head Self/Cross-Attention (MSCA), which introduces a temporal cross-attention mechanism for action recognition, based on the structure of the Multi-head Self-Attention (MSA) mechanism of the Vision Transformer (ViT). Simply applying ViT to each frame of a video frame can capture frame features, but cannot model temporal features. However, simply modeling temporal information with CNN or Transfomer is computationally expensive. TSM that perform feature shifting assume a CNN and cannot take advantage of the ViT structure. The proposed model captures temporal information by shifting the Query, Key, and Value in the calculation of MSA of ViT. This is efficient without additional coinformationmputational effort and is a suitable structure for extending ViT over temporal. Experiments on Kineitcs400 show the effectiveness of the proposed method and its superiority over previous methods.