 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction tube generation by person query matching for spatio-temporal action detection
Mar 17, 2025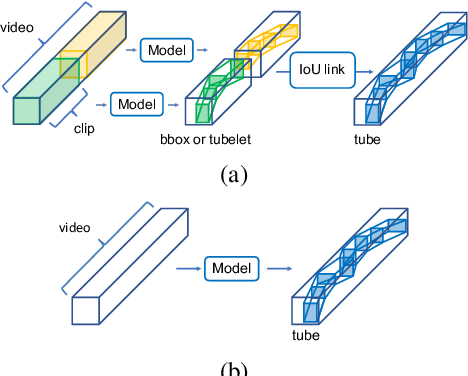
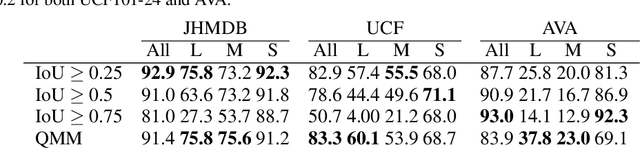
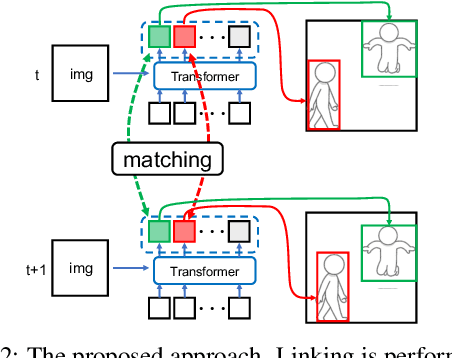
This paper proposes a method for spatio-temporal action detection (STAD) that directly generates action tubes from the original video without relying on post-processing steps such as IoU-based linking and clip splitting. Our approach applies query-based detection (DETR) to each frame and matches DETR queries to link the same person across frames. We introduce the Query Matching Module (QMM), which uses metric learning to bring queries for the same person closer together across frames compared to queries for different people. Action classes are predicted using the sequence of queries obtained from QMM matching, allowing for variable-length inputs from videos longer than a single clip. Experimental results on JHMDB, UCF101-24, and AVA datasets demonstrate that our method performs well for large position changes of people while offering superior computational efficiency and lower resource requirements.
Query matching for spatio-temporal action detection with query-based object detector
Sep 27, 2024



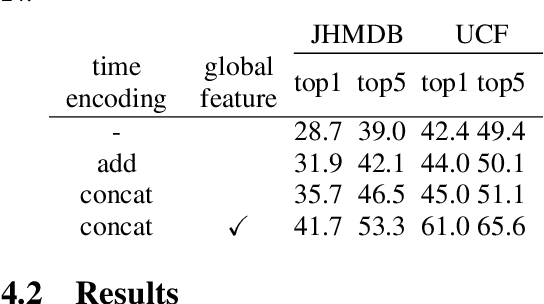
In this paper, we propose a method that extends the query-based object detection model, DETR, to spatio-temporal action detection, which requires maintaining temporal consistency in videos. Our proposed method applies DETR to each frame and uses feature shift to incorporate temporal information. However, DETR's object queries in each frame may correspond to different objects, making a simple feature shift ineffective. To overcome this issue, we propose query matching across different frames, ensuring that queries for the same object are matched and used for the feature shift. Experimental results show that performance on the JHMDB21 dataset improves significantly when query features are shifted using the proposed query matching.
On the Performance Evaluation of Action Recognition Models on Transcoded Low Quality Videos
Apr 19, 2022



In the design of action recognition models, the quality of videos in the dataset is an important issue, however the trade-off between the quality and performance is often ignored. In general, action recognition models are trained and tested on high-quality videos, but in actual situations where action recognition models are deployed, sometimes it might not be assumed that the input videos are of high quality. In this study, we report qualitative evaluations of action recognition models for the quality degradation associated with transcoding by JPEG and H.264/AVC. Experimental results are shown for evaluating the performance of pre-trained models on the transcoded validation videos of Kinetics400. The models are also trained on the transcoded training videos. From these results, we quantitatively show the degree of degradation of the model performance with respect to the degradation of the video quality.
Model-agnostic Multi-Domain Learning with Domain-Specific Adapters for Action Recognition
Apr 15, 2022
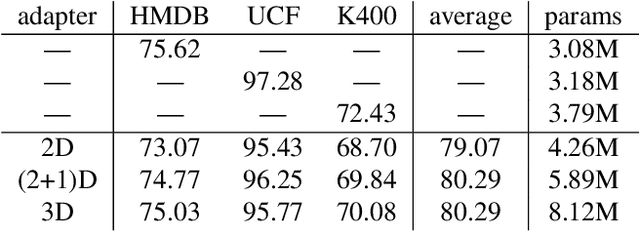


In this paper, we propose a multi-domain learning model for action recognition. The proposed method inserts domain-specific adapters between layers of domain-independent layers of a backbone network. Unlike a multi-head network that switches classification heads only, our model switches not only the heads, but also the adapters for facilitating to learn feature representations universal to multiple domains. Unlike prior works, the proposed method is model-agnostic and doesn't assume model structures unlike prior works. Experimental results on three popular action recognition datasets (HMDB51, UCF101, and Kinetics-400) demonstrate that the proposed method is more effective than a multi-head architecture and more efficient than separately training models for each domain.