 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction tube generation by person query matching for spatio-temporal action detection
Paper and Code
Mar 17, 2025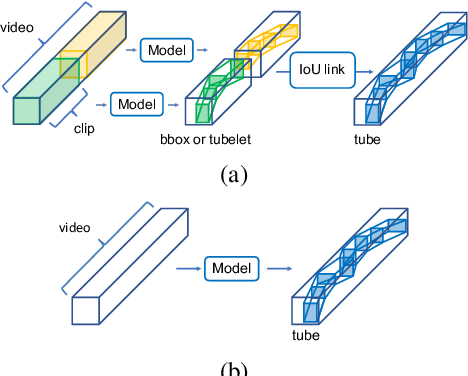
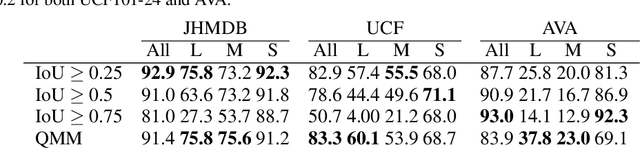
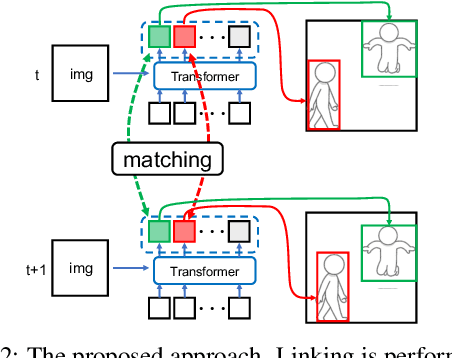
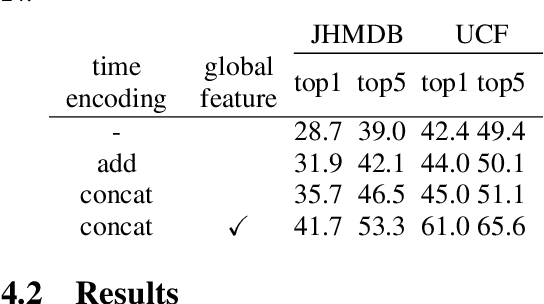
This paper proposes a method for spatio-temporal action detection (STAD) that directly generates action tubes from the original video without relying on post-processing steps such as IoU-based linking and clip splitting. Our approach applies query-based detection (DETR) to each frame and matches DETR queries to link the same person across frames. We introduce the Query Matching Module (QMM), which uses metric learning to bring queries for the same person closer together across frames compared to queries for different people. Action classes are predicted using the sequence of queries obtained from QMM matching, allowing for variable-length inputs from videos longer than a single clip. Experimental results on JHMDB, UCF101-24, and AVA datasets demonstrate that our method performs well for large position changes of people while offering superior computational efficiency and lower resource requirements.