 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer with Cross-attention by Temporal Shift for Efficient Action Recognition
Paper and Code


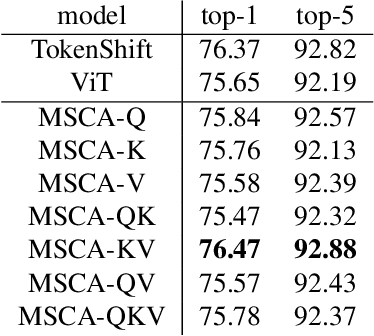

We propose Multi-head Self/Cross-Attention (MSCA), which introduces a temporal cross-attention mechanism for action recognition, based on the structure of the Multi-head Self-Attention (MSA) mechanism of the Vision Transformer (ViT). Simply applying ViT to each frame of a video frame can capture frame features, but cannot model temporal features. However, simply modeling temporal information with CNN or Transfomer is computationally expensive. TSM that perform feature shifting assume a CNN and cannot take advantage of the ViT structure. The proposed model captures temporal information by shifting the Query, Key, and Value in the calculation of MSA of ViT. This is efficient without additional coinformationmputational effort and is a suitable structure for extending ViT over temporal. Experiments on Kineitcs400 show the effectiveness of the proposed method and its superiority over previous methods.