 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained length controllable video captioning with ordinal embeddings
Paper and Code
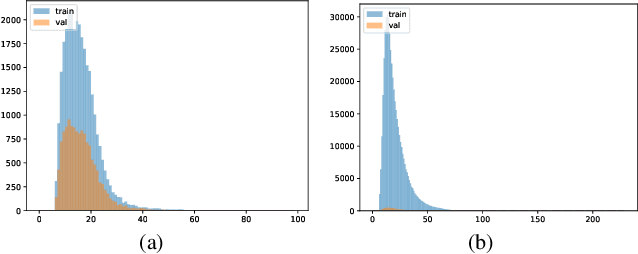

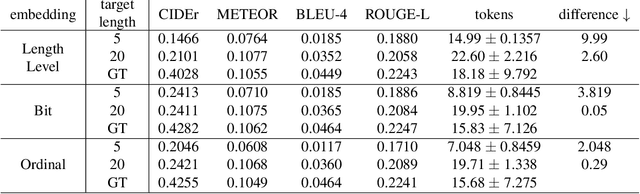
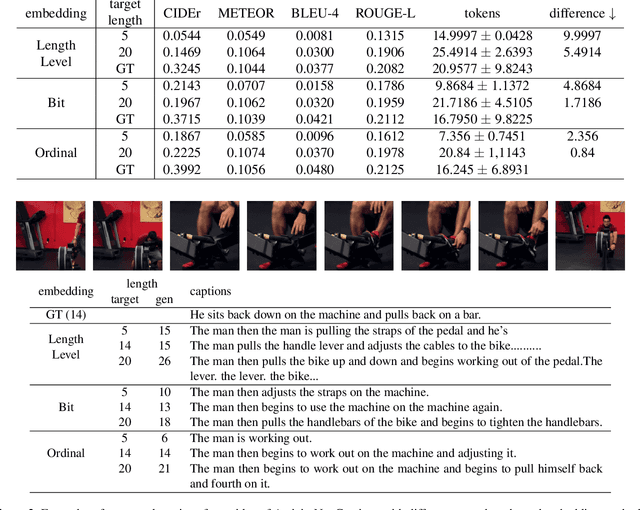
This paper proposes a method for video captioning that controls the length of generated captions. Previous work on length control often had few levels for expressing length. In this study, we propose two methods of length embedding for fine-grained length control. A traditional embedding method is linear, using a one-hot vector and an embedding matrix. In this study, we propose methods that represent length in multi-hot vectors. One is bit embedding that expresses length in bit representation, and the other is ordinal embedding that uses the binary representation often used in ordinal regression. These length representations of multi-hot vectors are converted into length embedding by a nonlinear MLP. This method allows for not only the length control of caption sentences but also the control of the time when reading the caption. Experiments using ActivityNet Captions and Spoken Moments in Time show that the proposed method effectively controls the length of the generated captions. Analysis of the embedding vectors with ICA shows that length and semantics were learned separately, demonstrating the effectiveness of the proposed embedding methods.