 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRephrasing visual questions by specifying the entropy of the answer distribution
Paper and Code
Apr 10, 2020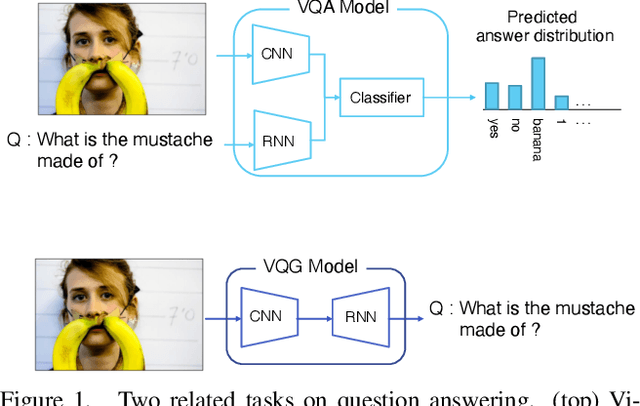


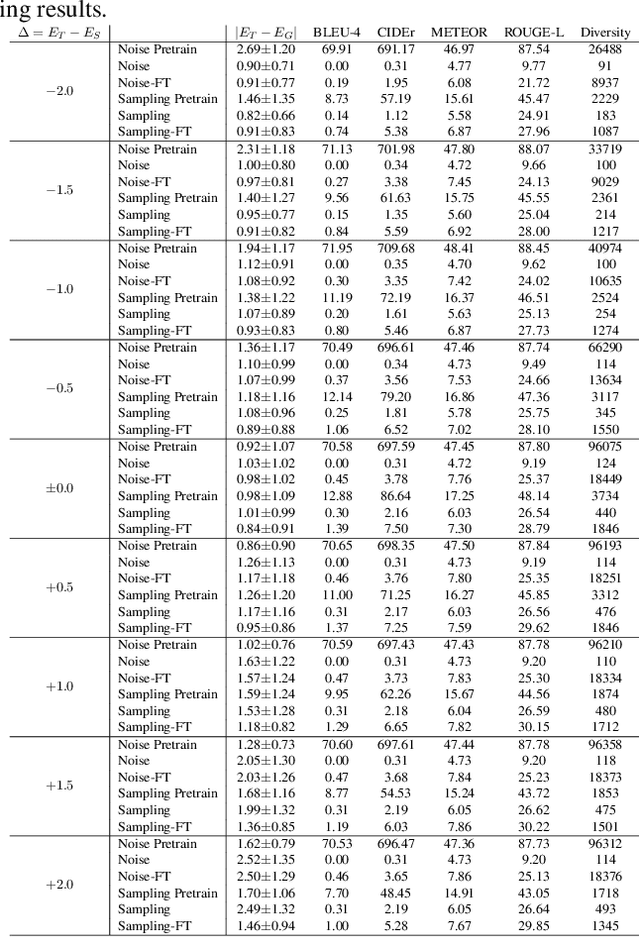
Visual question answering (VQA) is a task of answering a visual question that is a pair of question and image. Some visual questions are ambiguous and some are clear, and it may be appropriate to change the ambiguity of questions from situation to situation. However, this issue has not been addressed by any prior work. We propose a novel task, rephrasing the questions by controlling the ambiguity of the questions. The ambiguity of a visual question is defined by the use of the entropy of the answer distribution predicted by a VQA model. The proposed model rephrases a source question given with an image so that the rephrased question has the ambiguity (or entropy) specified by users. We propose two learning strategies to train the proposed model with the VQA v2 dataset, which has no ambiguity information. We demonstrate the advantage of our approach that can control the ambiguity of the rephrased questions, and an interesting observation that it is harder to increase than to reduce ambiguity.