 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation with L2 constraints for classifying images from different endoscope systems
Feb 02, 2018


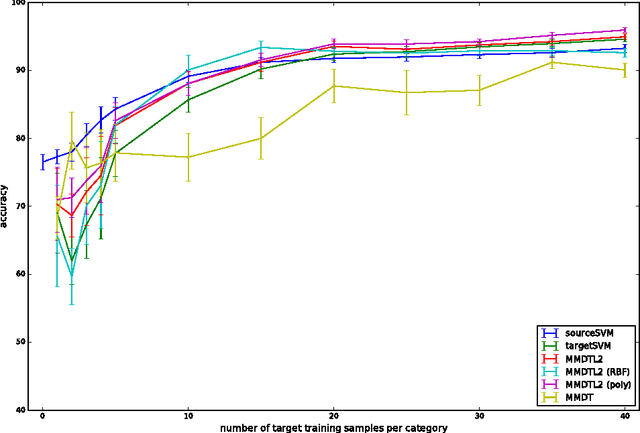
This paper proposes a method for domain adaptation that extends the maximum margin domain transfer (MMDT) proposed by Hoffman et al., by introducing L2 distance constraints between samples of different domains; thus, our method is denoted as MMDTL2. Motivated by the differences between the images taken by narrow band imaging (NBI) endoscopic devices, we utilize different NBI devices as different domains and estimate the transformations between samples of different domains, i.e., image samples taken by different NBI endoscope systems. We first formulate the problem in the primal form, and then derive the dual form with much lesser computational costs as compared to the naive approach. From our experimental results using NBI image datasets from two different NBI endoscopic devices, we find that MMDTL2 is better than MMDT and also support vector machines without adaptation, especially when NBI image features are high-dimensional and the per-class training samples are greater than 20.
Transfer Learning for Endoscopic Image Classification
Aug 24, 2016



In this paper we propose a method for transfer learning of endoscopic images. For transferring between features obtained from images taken by different (old and new) endoscopes, we extend the Max-Margin Domain Transfer (MMDT) proposed by Hoffman et al. in order to use L2 distance constraints as regularization, called Max-Margin Domain Transfer with L2 Distance Constraints (MMDTL2). Furthermore, we develop the dual formulation of the optimization problem in order to reduce the computation cost. Experimental results demonstrate that the proposed MMDTL2 outperforms MMDT for real data sets taken by different endoscopes.
Computer-Aided Colorectal Tumor Classification in NBI Endoscopy Using CNN Features
Aug 24, 2016



In this paper we report results for recognizing colorectal NBI endoscopic images by using features extracted from convolutional neural network (CNN). In this comparative study, we extract features from different layers from different CNN models, and then train linear SVM classifiers. Experimental results with 10-fold cross validations show that features from first few convolution layers are enough to achieve similar performance (i.e., recognition rate of 95%) with non-CNN local features such as Bag-of-Visual words, Fisher vector, and VLAD.