 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnfolding with a Wasserstein Loss
Mar 21, 2026Data unfolding -- the removal of noise or artifacts from measurements -- is a fundamental task across the experimental sciences. Of particular interest are applications in physics, where the dominant approach is Richardson-Lucy (RL) deconvolution. The classical RL approach aims to find denoised data that, once passed through the noise model, is as close as possible to the measured data in terms of Kullback-Leibler (KL) divergence. This requires that the support of the measured data overlaps with the output of the noise model, a hypothesis typically enforced by binning, which introduces numerical error. As a counterpoint, the present work studies an alternative formulation using a Wasserstein loss. We establish sharp conditions for existence and uniqueness of optimizers, answering open questions of Li, et al., regarding necessary conditions for existence and uniqueness in the case of transport map noise models. We then develop a provably convergent generalized Sinkhorn algorithm to compute approximate optimizers. Our algorithm requires only empirical observations of the noise model and measured data and scales with the size of the data, rather than the ambient dimension. Numerical experiments on one- and two-dimensional problems inspired by jet mass unfolding in particle physics demonstrate that the optimal transport approach offers robust, accurate performance compared to classical RL deconvolution, particularly when binning artifacts are significant.
Vector valued optimal transport: from dynamic to static formulations
May 06, 2025
Motivated by applications in classification of vector valued measures and multispecies PDE, we develop a theory that unifies existing notions of vector valued optimal transport, from dynamic formulations (\`a la Benamou-Brenier) to static formulations (\`a la Kantorovich). In our framework, vector valued measures are modeled as probability measures on a product space $\mathbb{R}^d \times G$, where $G$ is a weighted graph over a finite set of nodes and the graph geometry strongly influences the associated dynamic and static distances. We obtain sharp inequalities relating four notions of vector valued optimal transport and prove that the distances are mutually bi-H\"older equivalent. We discuss the theoretical and practical advantages of each metric and indicate potential applications in multispecies PDE and data analysis. In particular, one of the static formulations discussed in the paper is amenable to linearization, a technique that has been explored in recent years to accelerate the computation of pairwise optimal transport distances.
Wasserstein Archetypal Analysis
Oct 25, 2022Archetypal analysis is an unsupervised machine learning method that summarizes data using a convex polytope. In its original formulation, for fixed k, the method finds a convex polytope with k vertices, called archetype points, such that the polytope is contained in the convex hull of the data and the mean squared Euclidean distance between the data and the polytope is minimal. In the present work, we consider an alternative formulation of archetypal analysis based on the Wasserstein metric, which we call Wasserstein archetypal analysis (WAA). In one dimension, there exists a unique solution of WAA and, in two dimensions, we prove existence of a solution, as long as the data distribution is absolutely continuous with respect to Lebesgue measure. We discuss obstacles to extending our result to higher dimensions and general data distributions. We then introduce an appropriate regularization of the problem, via a Renyi entropy, which allows us to obtain existence of solutions of the regularized problem for general data distributions, in arbitrary dimensions. We prove a consistency result for the regularized problem, ensuring that if the data are iid samples from a probability measure, then as the number of samples is increased, a subsequence of the archetype points converges to the archetype points for the limiting data distribution, almost surely. Finally, we develop and implement a gradient-based computational approach for the two-dimensional problem, based on the semi-discrete formulation of the Wasserstein metric. Our analysis is supported by detailed computational experiments.
A blob method for inhomogeneous diffusion with applications to multi-agent control and sampling
Mar 09, 2022
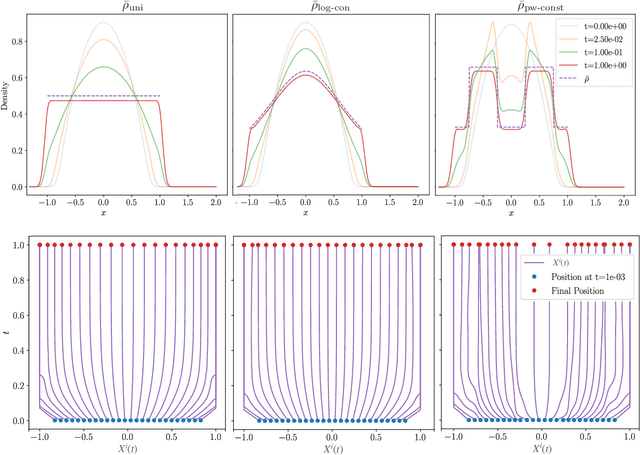


As a counterpoint to classical stochastic particle methods for linear diffusion equations, we develop a deterministic particle method for the weighted porous medium equation (WPME) and prove its convergence on bounded time intervals. This generalizes related work on blob methods for unweighted porous medium equations. From a numerical analysis perspective, our method has several advantages: it is meshfree, preserves the gradient flow structure of the underlying PDE, converges in arbitrary dimension, and captures the correct asymptotic behavior in simulations. That our method succeeds in capturing the long time behavior of WPME is significant from the perspective of related problems in quantization. Just as the Fokker-Planck equation provides a way to quantize a probability measure $\bar{\rho}$ by evolving an empirical measure according to stochastic Langevin dynamics so that the empirical measure flows toward $\bar{\rho}$, our particle method provides a way to quantize $\bar{\rho}$ according to deterministic particle dynamics approximating WMPE. In this way, our method has natural applications to multi-agent coverage algorithms and sampling probability measures. A specific case of our method corresponds exactly to the mean-field dynamics of training a two-layer neural network for a radial basis function activation function. From this perspective, our convergence result shows that, in the over parametrized regime and as the variance of the radial basis functions goes to zero, the continuum limit is given by WPME. This generalizes previous results, which considered the case of a uniform data distribution, to the more general inhomogeneous setting. As a consequence of our convergence result, we identify conditions on the target function and data distribution for which convexity of the energy landscape emerges in the continuum limit.
Clustering dynamics on graphs: from spectral clustering to mean shift through Fokker-Planck interpolation
Aug 18, 2021
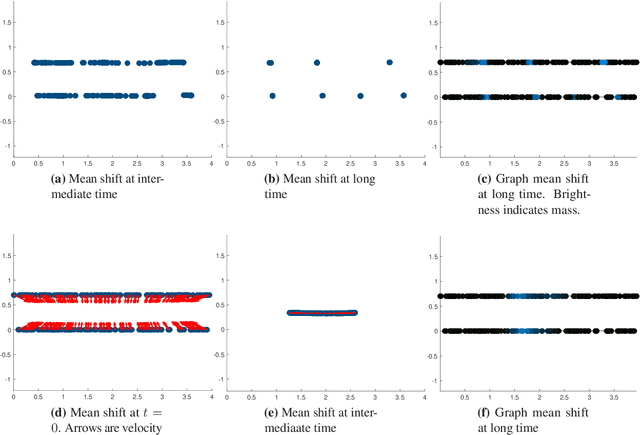
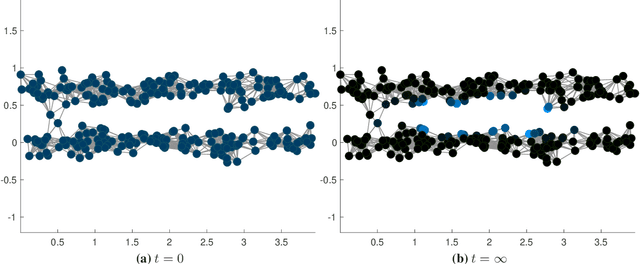
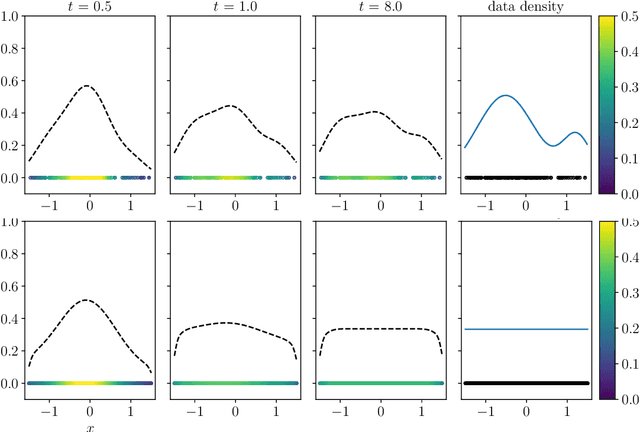
In this work we build a unifying framework to interpolate between density-driven and geometry-based algorithms for data clustering, and specifically, to connect the mean shift algorithm with spectral clustering at discrete and continuum levels. We seek this connection through the introduction of Fokker-Planck equations on data graphs. Besides introducing new forms of mean shift algorithms on graphs, we provide new theoretical insights on the behavior of the family of diffusion maps in the large sample limit as well as provide new connections between diffusion maps and mean shift dynamics on a fixed graph. Several numerical examples illustrate our theoretical findings and highlight the benefits of interpolating density-driven and geometry-based clustering algorithms.
Linearized Optimal Transport for Collider Events
Aug 19, 2020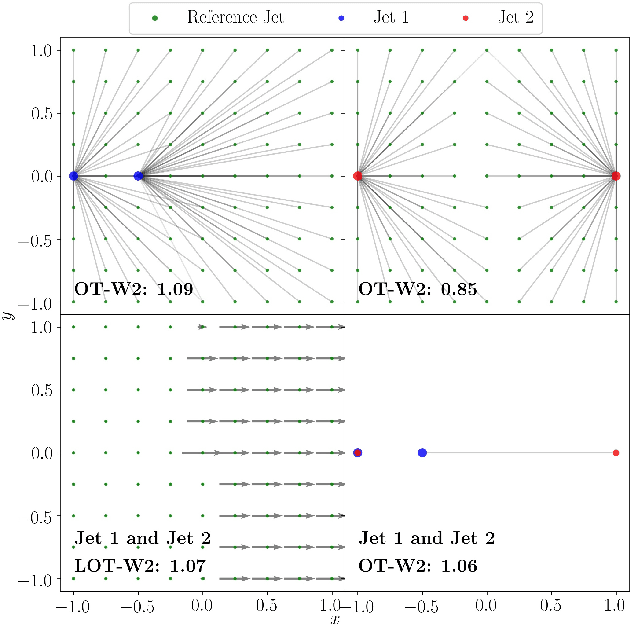
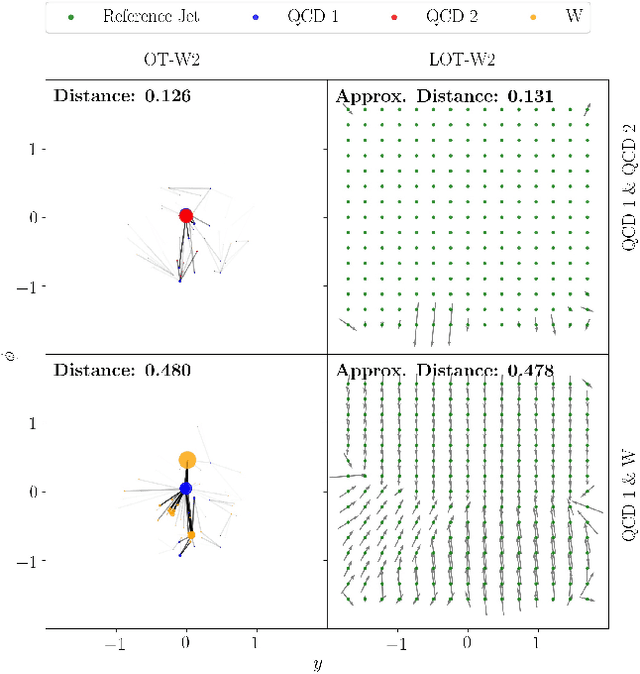
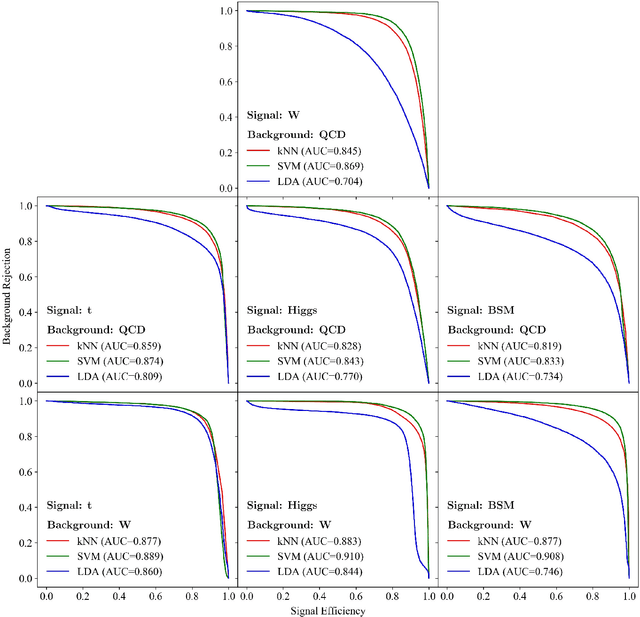
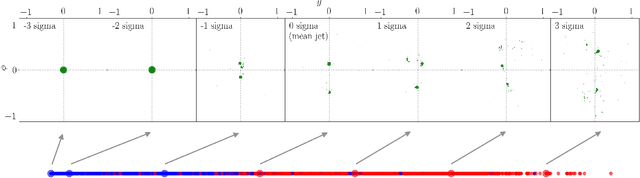
We introduce an efficient framework for computing the distance between collider events using the tools of Linearized Optimal Transport (LOT). This preserves many of the advantages of the recently-introduced Energy Mover's Distance, which quantifies the "work" required to rearrange one event into another, while significantly reducing the computational cost. It also furnishes a Euclidean embedding amenable to simple machine learning algorithms and visualization techniques, which we demonstrate in a variety of jet tagging examples. The LOT approximation lowers the threshold for diverse applications of the theory of optimal transport to collider physics.