 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-resolution myelin-water fraction and quantitative relaxation mapping using 3D ViSTa-MR fingerprinting
Dec 21, 2023Purpose: This study aims to develop a high-resolution whole-brain multi-parametric quantitative MRI approach for simultaneous mapping of myelin-water fraction (MWF), T1, T2, and proton-density (PD), all within a clinically feasible scan time. Methods: We developed 3D ViSTa-MRF, which combined Visualization of Short Transverse relaxation time component (ViSTa) technique with MR Fingerprinting (MRF), to achieve high-fidelity whole-brain MWF and T1/T2/PD mapping on a clinical 3T scanner. To achieve fast acquisition and memory-efficient reconstruction, the ViSTa-MRF sequence leverages an optimized 3D tiny-golden-angle-shuffling spiral-projection acquisition and joint spatial-temporal subspace reconstruction with optimized preconditioning algorithm. With the proposed ViSTa-MRF approach, high-fidelity direct MWF mapping was achieved without a need for multi-compartment fitting that could introduce bias and/or noise from additional assumptions or priors. Results: The in-vivo results demonstrate the effectiveness of the proposed acquisition and reconstruction framework to provide fast multi-parametric mapping with high SNR and good quality. The in-vivo results of 1mm- and 0.66mm-iso datasets indicate that the MWF values measured by the proposed method are consistent with standard ViSTa results that are 30x slower with lower SNR. Furthermore, we applied the proposed method to enable 5-minute whole-brain 1mm-iso assessment of MWF and T1/T2/PD mappings for infant brain development and for post-mortem brain samples. Conclusions: In this work, we have developed a 3D ViSTa-MRF technique that enables the acquisition of whole-brain MWF, quantitative T1, T2, and PD maps at 1mm and 0.66mm isotropic resolution in 5 and 15 minutes, respectively. This advancement allows for quantitative investigations of myelination changes in the brain.
Validation and generalization of pixel-wise relevance in convolutional neural networks trained for face classification
Jun 16, 2020

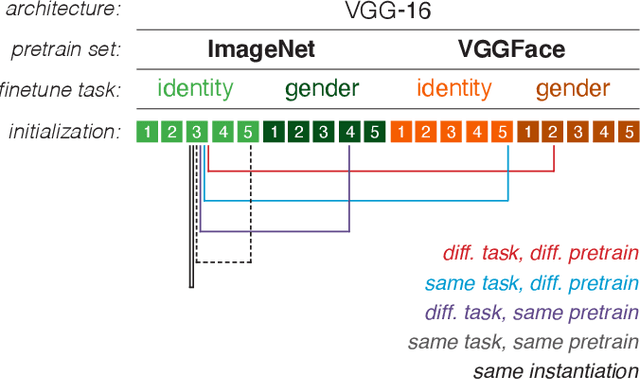
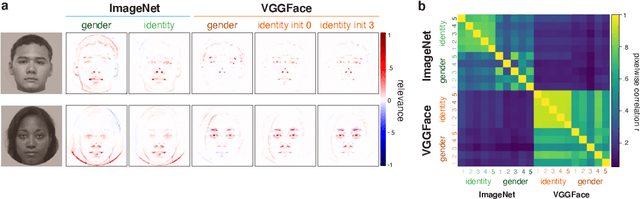
The increased use of convolutional neural networks for face recognition in science, governance, and broader society has created an acute need for methods that can show how these 'black box' decisions are made. To be interpretable and useful to humans, such a method should convey a model's learned classification strategy in a way that is robust to random initializations or spurious correlations in input data. To this end, we applied the decompositional pixel-wise attribution method of layer-wise relevance propagation (LRP) to resolve the decisions of several classes of VGG-16 models trained for face recognition. We then quantified how these relevance measures vary with and generalize across key model parameters, such as the pretraining dataset (ImageNet or VGGFace), the finetuning task (gender or identity classification), and random initializations of model weights. Using relevance-based image masking, we find that relevance maps for face classification prove generally stable across random initializations, and can generalize across finetuning tasks. However, there is markedly less generalization across pretraining datasets, indicating that ImageNet- and VGGFace-trained models sample face information differently even as they achieve comparably high classification performance. Fine-grained analyses of relevance maps across models revealed asymmetries in generalization that point to specific benefits of choice parameters, and suggest that it may be possible to find an underlying set of important face image pixels that drive decisions across convolutional neural networks and tasks. Finally, we evaluated model decision weighting against human measures of similarity, providing a novel framework for interpreting face recognition decisions across human and machine.
The Effect of Learning Strategy versus Inherent Architecture Properties on the Ability of Convolutional Neural Networks to Develop Transformation Invariance
Oct 31, 2018
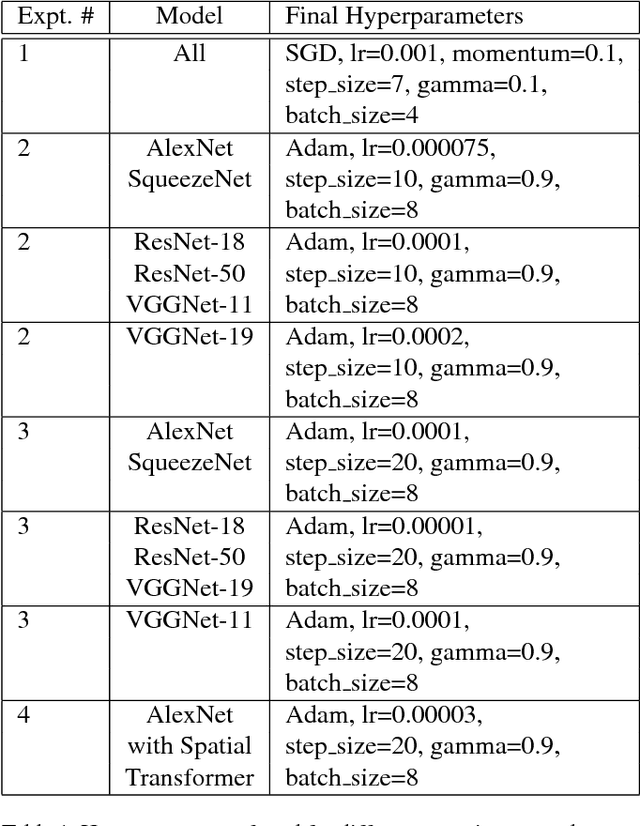

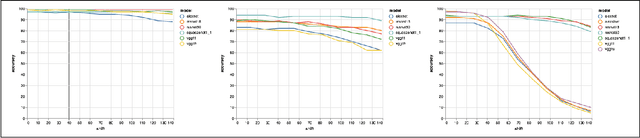
As object recognition becomes an increasingly common ML task, and recent research demonstrating CNNs vulnerability to attacks and small image perturbations necessitate fully understanding the foundations of object recognition. We focus on understanding the mechanisms behind how neural networks generalize to spatial transformations of complex objects. While humans excel at discriminating between objects shown at new positions, orientations, and scales, past results demonstrate that this may be limited to familiar objects - humans demonstrate low tolerance of spatial-variances for purposefully constructed novel objects. Because training artificial neural networks from scratch is similar to showing novel objects to humans, we seek to understand the factors influencing the tolerance of CNNs to spatial transformations. We conduct a thorough empirical examination of seven Convolutional Neural Network (CNN) architectures. By training on a controlled face image dataset, we measure model accuracy across different degrees of 5 transformations: position, size, rotation, Gaussian blur, and resolution transformation due to resampling. We also examine how learning strategy affects generalizability by examining how different amounts of pre-training have on model robustness. Overall, we find that the most significant contributor to transformation invariance is pre-training on a large, diverse image dataset. Moreover, while AlexNet tends to be the least robust network, VGG and ResNet architectures demonstrate higher robustness for different transformations. Along with kernel visualizations and qualitative analyses, we examine differences between learning strategy and inherent architectural properties in contributing to invariance of transformations, providing valuable information towards understanding how to achieve greater robustness to transformations in CNNs.