 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Uncertainty in Transformer Inference
Dec 08, 2024We explore the Iterative Inference Hypothesis (IIH) within the context of transformer-based language models, aiming to understand how a model's latent representations are progressively refined and whether observable differences are present between correct and incorrect generations. Our findings provide empirical support for the IIH, showing that the nth token embedding in the residual stream follows a trajectory of decreasing loss. Additionally, we observe that the rate at which residual embeddings converge to a stable output representation reflects uncertainty in the token generation process. Finally, we introduce a method utilizing cross-entropy to detect this uncertainty and demonstrate its potential to distinguish between correct and incorrect token generations on a dataset of idioms.
Boosting Sample Efficiency and Generalization in Multi-agent Reinforcement Learning via Equivariance
Oct 03, 2024



Multi-Agent Reinforcement Learning (MARL) struggles with sample inefficiency and poor generalization [1]. These challenges are partially due to a lack of structure or inductive bias in the neural networks typically used in learning the policy. One such form of structure that is commonly observed in multi-agent scenarios is symmetry. The field of Geometric Deep Learning has developed Equivariant Graph Neural Networks (EGNN) that are equivariant (or symmetric) to rotations, translations, and reflections of nodes. Incorporating equivariance has been shown to improve learning efficiency and decrease error [ 2 ]. In this paper, we demonstrate that EGNNs improve the sample efficiency and generalization in MARL. However, we also show that a naive application of EGNNs to MARL results in poor early exploration due to a bias in the EGNN structure. To mitigate this bias, we present Exploration-enhanced Equivariant Graph Neural Networks or E2GN2. We compare E2GN2 to other common function approximators using common MARL benchmarks MPE and SMACv2. E2GN2 demonstrates a significant improvement in sample efficiency, greater final reward convergence, and a 2x-5x gain in over standard GNNs in our generalization tests. These results pave the way for more reliable and effective solutions in complex multi-agent systems.
Adaptive Neural Networks Using Residual Fitting
Jan 13, 2023Current methods for estimating the required neural-network size for a given problem class have focused on methods that can be computationally intensive, such as neural-architecture search and pruning. In contrast, methods that add capacity to neural networks as needed may provide similar results to architecture search and pruning, but do not require as much computation to find an appropriate network size. Here, we present a network-growth method that searches for explainable error in the network's residuals and grows the network if sufficient error is detected. We demonstrate this method using examples from classification, imitation learning, and reinforcement learning. Within these tasks, the growing network can often achieve better performance than small networks that do not grow, and similar performance to networks that begin much larger.
Presentation and Analysis of a Multimodal Dataset for Grounded LanguageLearning
Jul 31, 2020
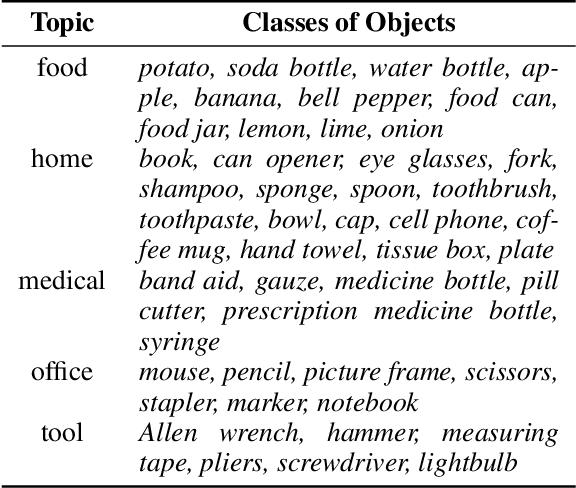


Grounded language acquisition -- learning how language-based interactions refer to the world around them -- is amajor area of research in robotics, NLP, and HCI. In practice the data used for learning consists almost entirely of textual descriptions, which tend to be cleaner, clearer, and more grammatical than actual human interactions. In this work, we present the Grounded Language Dataset (GoLD), a multimodal dataset of common household objects described by people using either spoken or written language. We analyze the differences and present an experiment showing how the different modalities affect language learning from human in-put. This will enable researchers studying the intersection of robotics, NLP, and HCI to better investigate how the multiple modalities of image, text, and speech interact, as well as show differences in the vernacular of these modalities impact results.
Planning with Abstract Learned Models While Learning Transferable Subtasks
Dec 16, 2019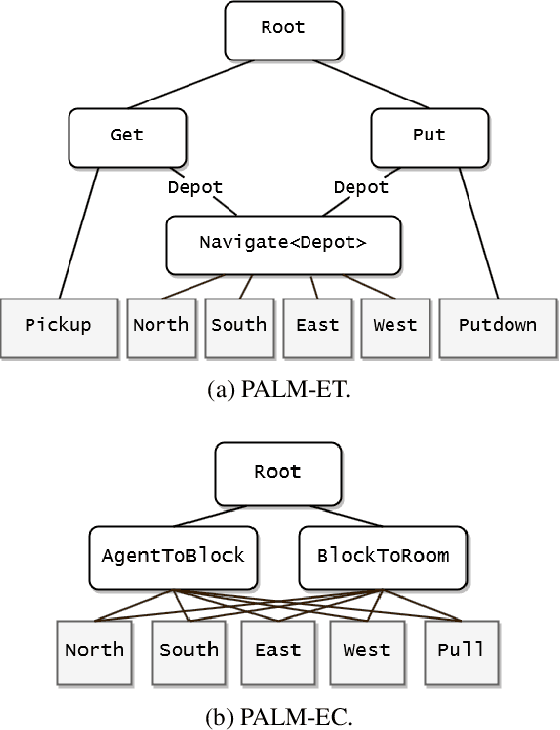
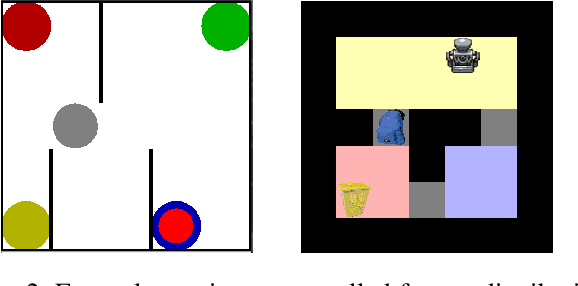
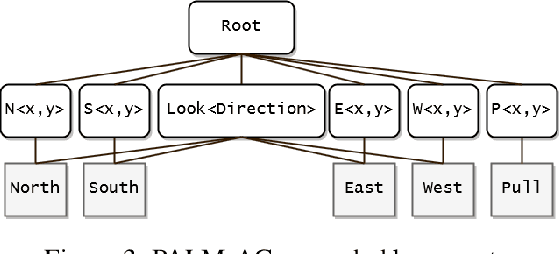
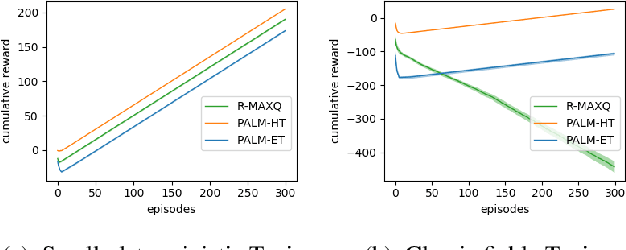
We introduce an algorithm for model-based hierarchical reinforcement learning to acquire self-contained transition and reward models suitable for probabilistic planning at multiple levels of abstraction. We call this framework Planning with Abstract Learned Models (PALM). By representing subtasks symbolically using a new formal structure, the lifted abstract Markov decision process (L-AMDP), PALM learns models that are independent and modular. Through our experiments, we show how PALM integrates planning and execution, facilitating a rapid and efficient learning of abstract, hierarchical models. We also demonstrate the increased potential for learned models to be transferred to new and related tasks.