 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP Multi-modal Hashing for Multimedia Retrieval
Oct 10, 2024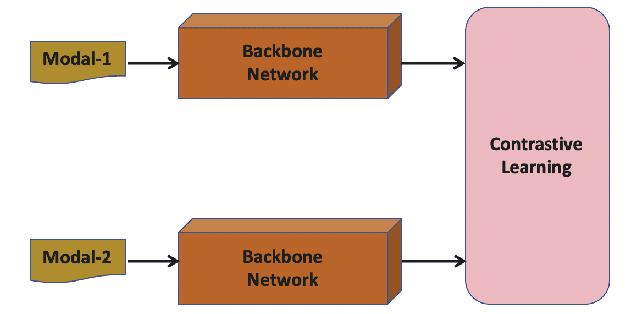



Multi-modal hashing methods are widely used in multimedia retrieval, which can fuse multi-source data to generate binary hash code. However, the individual backbone networks have limited feature expression capabilities and are not jointly pre-trained on large-scale unsupervised multi-modal data, resulting in low retrieval accuracy. To address this issue, we propose a novel CLIP Multi-modal Hashing (CLIPMH) method. Our method employs the CLIP framework to extract both text and vision features and then fuses them to generate hash code. Due to enhancement on each modal feature, our method has great improvement in the retrieval performance of multi-modal hashing methods. Compared with state-of-the-art unsupervised and supervised multi-modal hashing methods, experiments reveal that the proposed CLIPMH can significantly improve performance (a maximum increase of 8.38% in mAP).
Deep Prompt Multi-task Network for Abuse Language Detection
Mar 08, 2024



The detection of abusive language remains a long-standing challenge with the extensive use of social networks. The detection task of abusive language suffers from limited accuracy. We argue that the existing detection methods utilize the fine-tuning technique of the pre-trained language models (PLMs) to handle downstream tasks. Hence, these methods fail to stimulate the general knowledge of the PLMs. To address the problem, we propose a novel Deep Prompt Multi-task Network (DPMN) for abuse language detection. Specifically, DPMN first attempts to design two forms of deep prompt tuning and light prompt tuning for the PLMs. The effects of different prompt lengths, tuning strategies, and prompt initialization methods on detecting abusive language are studied. In addition, we propose a Task Head based on Bi-LSTM and FFN, which can be used as a short text classifier. Eventually, DPMN utilizes multi-task learning to improve detection metrics further. The multi-task network has the function of transferring effective knowledge. The proposed DPMN is evaluated against eight typical methods on three public datasets: OLID, SOLID, and AbuseAnalyzer. The experimental results show that our DPMN outperforms the state-of-the-art methods.
CLIP Multi-modal Hashing: A new baseline CLIPMH
Aug 22, 2023



The multi-modal hashing method is widely used in multimedia retrieval. It can fuse multi-source data to generate binary hash code. However, the current multi-modal methods have the problem of low retrieval accuracy. The reason is that the individual backbone networks have limited feature expression capabilities and are not jointly pre-trained on large-scale unsupervised multi-modal data. To solve this problem, we propose a new baseline CLIP Multi-modal Hashing (CLIPMH) method. It uses CLIP model to extract text and image features, and then fuse to generate hash code. CLIP improves the expressiveness of each modal feature. In this way, it can greatly improve the retrieval performance of multi-modal hashing methods. In comparison to state-of-the-art unsupervised and supervised multi-modal hashing methods, experiments reveal that the proposed CLIPMH can significantly enhance performance (Maximum increase of 8.38%). CLIP also has great advantages over the text and visual backbone networks commonly used before.
IR2Net: Information Restriction and Information Recovery for Accurate Binary Neural Networks
Oct 06, 2022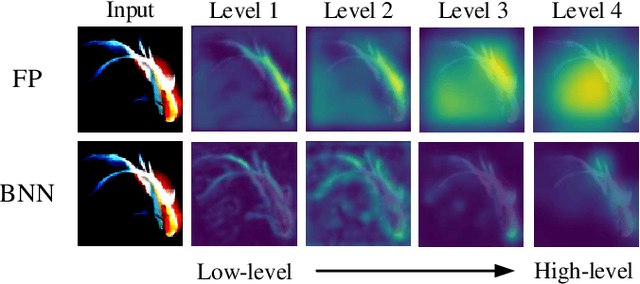
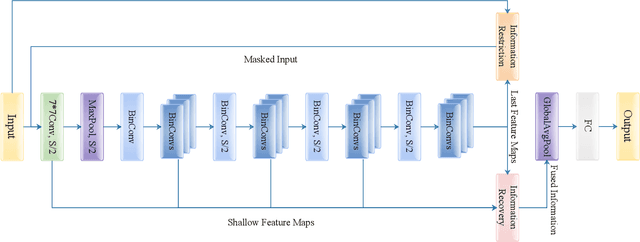
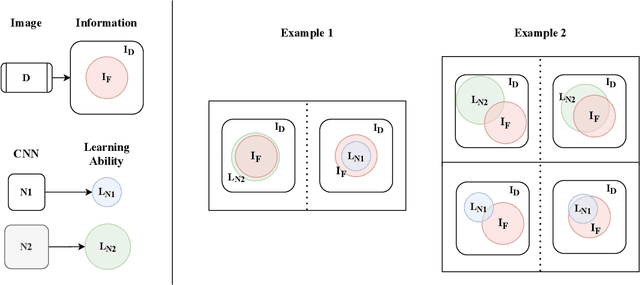
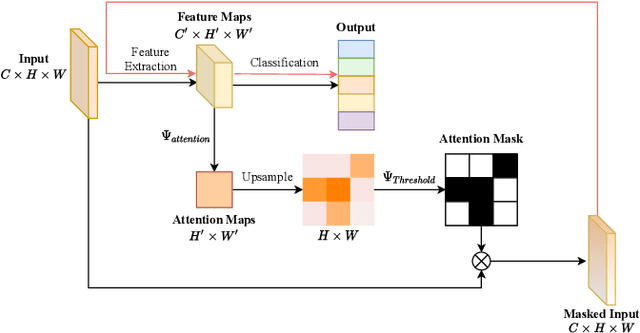
Weight and activation binarization can efficiently compress deep neural networks and accelerate model inference, but cause severe accuracy degradation. Existing optimization methods for binary neural networks (BNNs) focus on fitting full-precision networks to reduce quantization errors, and suffer from the trade-off between accuracy and computational complexity. In contrast, considering the limited learning ability and information loss caused by the limited representational capability of BNNs, we propose IR$^2$Net to stimulate the potential of BNNs and improve the network accuracy by restricting the input information and recovering the feature information, including: 1) information restriction: for a BNN, by evaluating the learning ability on the input information, discarding some of the information it cannot focus on, and limiting the amount of input information to match its learning ability; 2) information recovery: due to the information loss in forward propagation, the output feature information of the network is not enough to support accurate classification. By selecting some shallow feature maps with richer information, and fusing them with the final feature maps to recover the feature information. In addition, the computational cost is reduced by streamlining the information recovery method to strike a better trade-off between accuracy and efficiency. Experimental results demonstrate that our approach still achieves comparable accuracy even with $ \sim $10x floating-point operations (FLOPs) reduction for ResNet-18. The models and code are available at https://github.com/pingxue-hfut/IR2Net.
AIP: Adversarial Iterative Pruning Based on Knowledge Transfer for Convolutional Neural Networks
Aug 31, 2021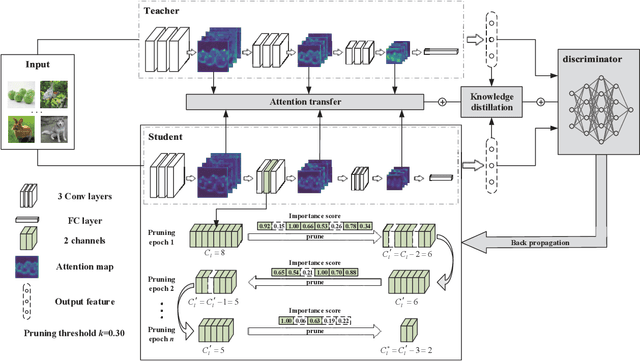
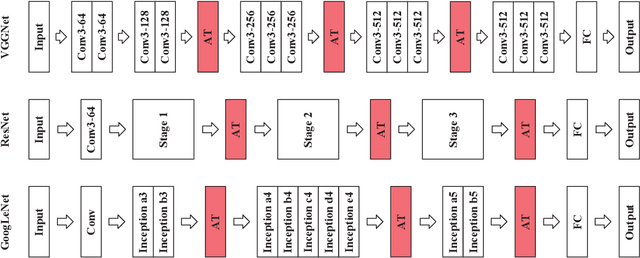
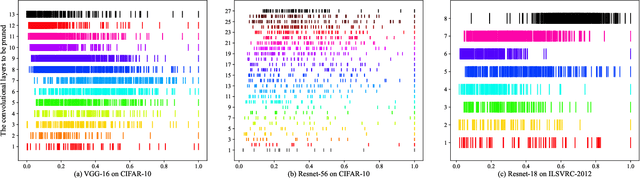
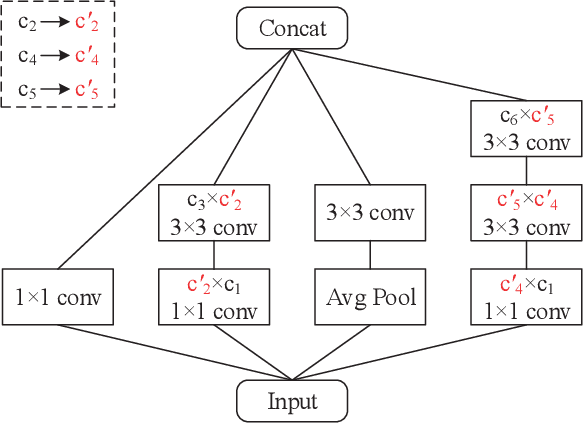
With the increase of structure complexity, convolutional neural networks (CNNs) take a fair amount of computation cost. Meanwhile, existing research reveals the salient parameter redundancy in CNNs. The current pruning methods can compress CNNs with little performance drop, but when the pruning ratio increases, the accuracy loss is more serious. Moreover, some iterative pruning methods are difficult to accurately identify and delete unimportant parameters due to the accuracy drop during pruning. We propose a novel adversarial iterative pruning method (AIP) for CNNs based on knowledge transfer. The original network is regarded as the teacher while the compressed network is the student. We apply attention maps and output features to transfer information from the teacher to the student. Then, a shallow fully-connected network is designed as the discriminator to allow the output of two networks to play an adversarial game, thereby it can quickly recover the pruned accuracy among pruning intervals. Finally, an iterative pruning scheme based on the importance of channels is proposed. We conduct extensive experiments on the image classification tasks CIFAR-10, CIFAR-100, and ILSVRC-2012 to verify our pruning method can achieve efficient compression for CNNs even without accuracy loss. On the ILSVRC-2012, when removing 36.78% parameters and 45.55% floating-point operations (FLOPs) of ResNet-18, the Top-1 accuracy drop are only 0.66%. Our method is superior to some state-of-the-art pruning schemes in terms of compressing rate and accuracy. Moreover, we further demonstrate that AIP has good generalization on the object detection task PASCAL VOC.
Self-Distribution Binary Neural Networks
Mar 04, 2021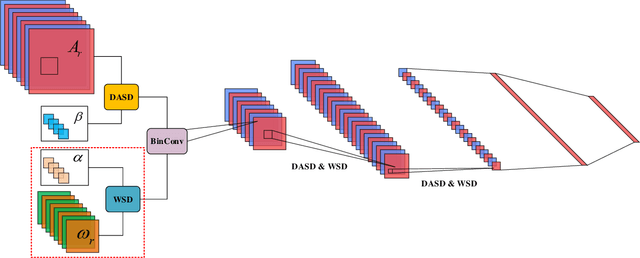
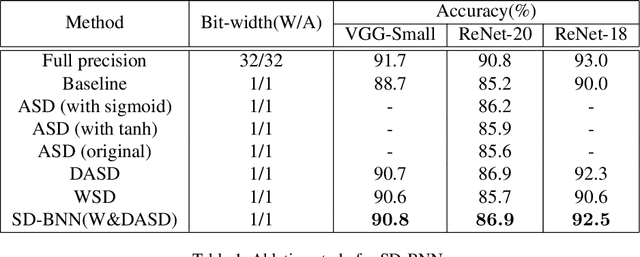
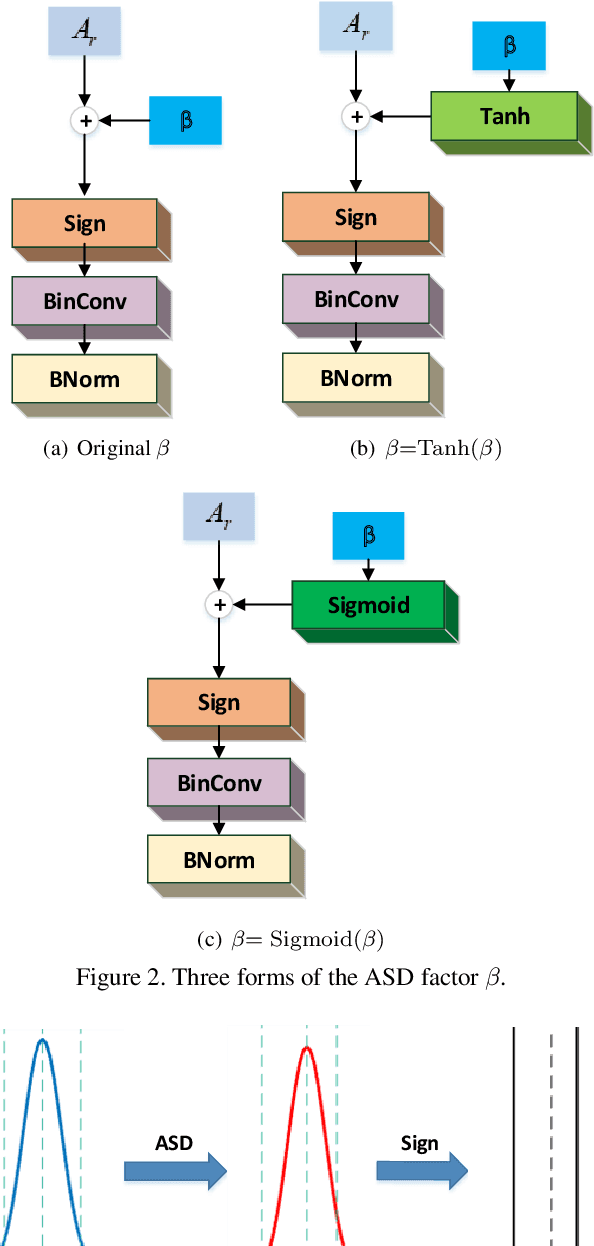
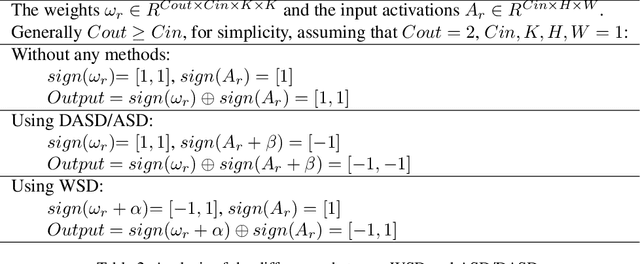
In this work, we study the binary neural networks (BNNs) of which both the weights and activations are binary (i.e., 1-bit representation). Feature representation is critical for deep neural networks, while in BNNs, the features only differ in signs. Prior work introduces scaling factors into binary weights and activations to reduce the quantization error and effectively improves the classification accuracy of BNNs. However, the scaling factors not only increase the computational complexity of networks, but also make no sense to the signs of binary features. To this end, Self-Distribution Binary Neural Network (SD-BNN) is proposed. Firstly, we utilize Activation Self Distribution (ASD) to adaptively adjust the sign distribution of activations, thereby improve the sign differences of the outputs of the convolution. Secondly, we adjust the sign distribution of weights through Weight Self Distribution (WSD) and then fine-tune the sign distribution of the outputs of the convolution. Extensive experiments on CIFAR-10 and ImageNet datasets with various network structures show that the proposed SD-BNN consistently outperforms the state-of-the-art (SOTA) BNNs (e.g., achieves 92.5% on CIFAR-10 and 66.5% on ImageNet with ResNet-18) with less computation cost. Code is available at https://github.com/ pingxue-hfut/SD-BNN.
ACP: Automatic Channel Pruning via Clustering and Swarm Intelligence Optimization for CNN
Jan 16, 2021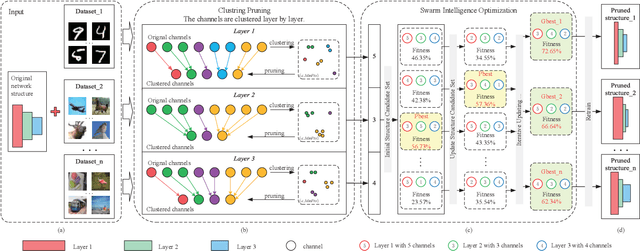
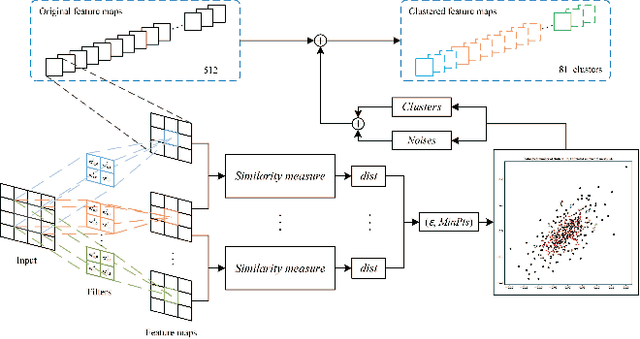
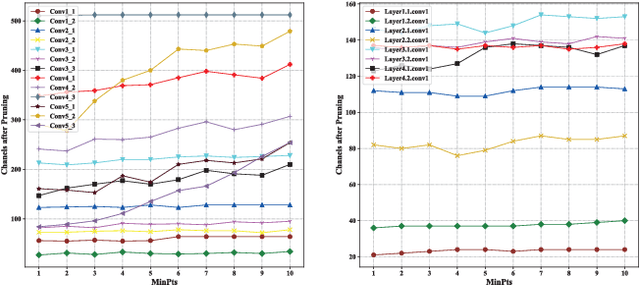
As the convolutional neural network (CNN) gets deeper and wider in recent years, the requirements for the amount of data and hardware resources have gradually increased. Meanwhile, CNN also reveals salient redundancy in several tasks. The existing magnitude-based pruning methods are efficient, but the performance of the compressed network is unpredictable. While the accuracy loss after pruning based on the structure sensitivity is relatively slight, the process is time-consuming and the algorithm complexity is notable. In this article, we propose a novel automatic channel pruning method (ACP). Specifically, we firstly perform layer-wise channel clustering via the similarity of the feature maps to perform preliminary pruning on the network. Then a population initialization method is introduced to transform the pruned structure into a candidate population. Finally, we conduct searching and optimizing iteratively based on the particle swarm optimization (PSO) to find the optimal compressed structure. The compact network is then retrained to mitigate the accuracy loss from pruning. Our method is evaluated against several state-of-the-art CNNs on three different classification datasets CIFAR-10/100 and ILSVRC-2012. On the ILSVRC-2012, when removing 64.36% parameters and 63.34% floating-point operations (FLOPs) of ResNet-50, the Top-1 and Top-5 accuracy drop are less than 0.9%. Moreover, we demonstrate that without harming overall performance it is possible to compress SSD by more than 50% on the target detection dataset PASCAL VOC. It further verifies that the proposed method can also be applied to other CNNs and application scenarios.
Coarse and fine-grained automatic cropping deep convolutional neural network
Oct 14, 2020The existing convolutional neural network pruning algorithms can be divided into two categories: coarse-grained clipping and fine-grained clipping. This paper proposes a coarse and fine-grained automatic pruning algorithm, which can achieve more efficient and accurate compression acceleration for convolutional neural networks. First, cluster the intermediate feature maps of the convolutional neural network to obtain the network structure after coarse-grained clipping, and then use the particle swarm optimization algorithm to iteratively search and optimize the structure. Finally, the optimal network tailoring substructure is obtained.
UCP: Uniform Channel Pruning for Deep Convolutional Neural Networks Compression and Acceleration
Oct 03, 2020
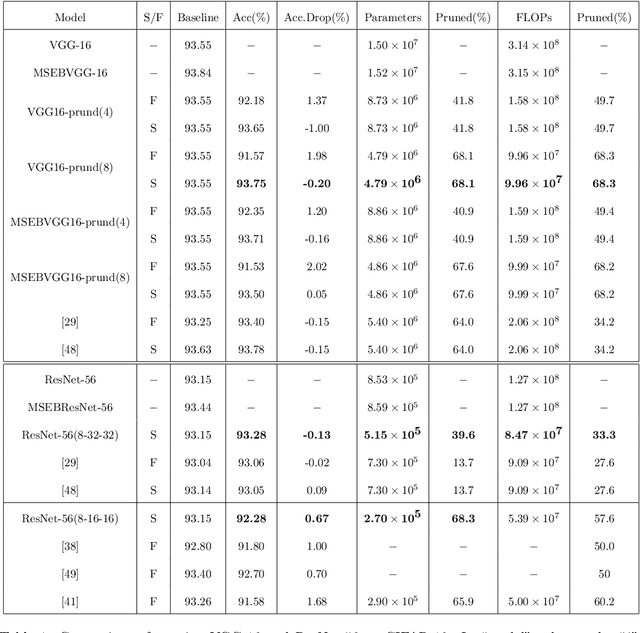
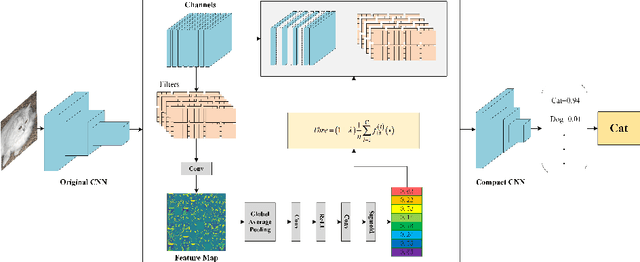
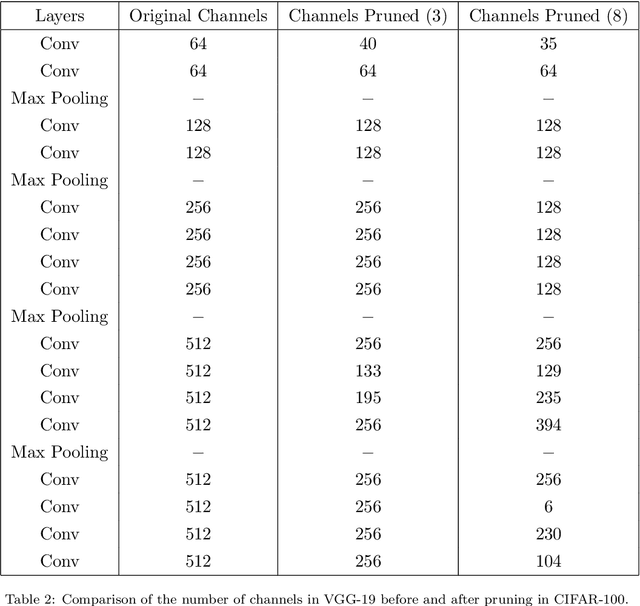
To apply deep CNNs to mobile terminals and portable devices, many scholars have recently worked on the compressing and accelerating deep convolutional neural networks. Based on this, we propose a novel uniform channel pruning (UCP) method to prune deep CNN, and the modified squeeze-and-excitation blocks (MSEB) is used to measure the importance of the channels in the convolutional layers. The unimportant channels, including convolutional kernels related to them, are pruned directly, which greatly reduces the storage cost and the number of calculations. There are two types of residual blocks in ResNet. For ResNet with bottlenecks, we use the pruning method with traditional CNN to trim the 3x3 convolutional layer in the middle of the blocks. For ResNet with basic residual blocks, we propose an approach to consistently prune all residual blocks in the same stage to ensure that the compact network structure is dimensionally correct. Considering that the network loses considerable information after pruning and that the larger the pruning amplitude is, the more information that will be lost, we do not choose fine-tuning but retrain from scratch to restore the accuracy of the network after pruning. Finally, we verified our method on CIFAR-10, CIFAR-100 and ILSVRC-2012 for image classification. The results indicate that the performance of the compact network after retraining from scratch, when the pruning rate is small, is better than the original network. Even when the pruning amplitude is large, the accuracy can be maintained or decreased slightly. On the CIFAR-100, when reducing the parameters and FLOPs up to 82% and 62% respectively, the accuracy of VGG-19 even improved by 0.54% after retraining.