 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP Multi-modal Hashing for Multimedia Retrieval
Paper and Code
Oct 10, 2024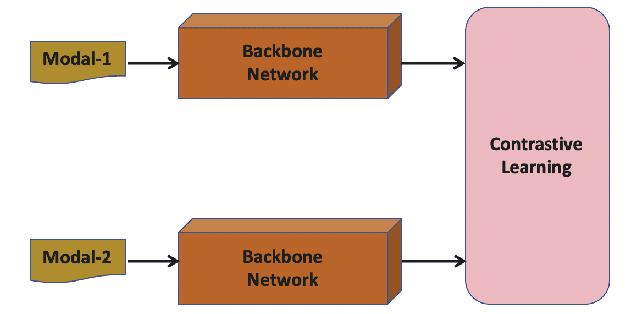



Multi-modal hashing methods are widely used in multimedia retrieval, which can fuse multi-source data to generate binary hash code. However, the individual backbone networks have limited feature expression capabilities and are not jointly pre-trained on large-scale unsupervised multi-modal data, resulting in low retrieval accuracy. To address this issue, we propose a novel CLIP Multi-modal Hashing (CLIPMH) method. Our method employs the CLIP framework to extract both text and vision features and then fuses them to generate hash code. Due to enhancement on each modal feature, our method has great improvement in the retrieval performance of multi-modal hashing methods. Compared with state-of-the-art unsupervised and supervised multi-modal hashing methods, experiments reveal that the proposed CLIPMH can significantly improve performance (a maximum increase of 8.38% in mAP).