 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Low-Bit Quantization-Aware Training Work for Reasoning LLMs? A Systematic Study
Jan 21, 2026Reasoning models excel at complex tasks such as coding and mathematics, yet their inference is often slow and token-inefficient. To improve the inference efficiency, post-training quantization (PTQ) usually comes with the cost of large accuracy drops, especially for reasoning tasks under low-bit settings. In this study, we present a systematic empirical study of quantization-aware training (QAT) for reasoning models. Our key findings include: (1) Knowledge distillation is a robust objective for reasoning models trained via either supervised fine-tuning or reinforcement learning; (2) PTQ provides a strong initialization for QAT, improving accuracy while reducing training cost; (3) Reinforcement learning remains feasible for quantized models given a viable cold start and yields additional gains; and (4) Aligning the PTQ calibration domain with the QAT training domain accelerates convergence and often improves the final accuracy. Finally, we consolidate these findings into an optimized workflow (Reasoning-QAT), and show that it consistently outperforms state-of-the-art PTQ methods across multiple LLM backbones and reasoning datasets. For instance, on Qwen3-0.6B, it surpasses GPTQ by 44.53% on MATH-500 and consistently recovers performance in the 2-bit regime.
IteRPrimE: Zero-shot Referring Image Segmentation with Iterative Grad-CAM Refinement and Primary Word Emphasis
Mar 02, 2025Zero-shot Referring Image Segmentation (RIS) identifies the instance mask that best aligns with a specified referring expression without training and fine-tuning, significantly reducing the labor-intensive annotation process. Despite achieving commendable results, previous CLIP-based models have a critical drawback: the models exhibit a notable reduction in their capacity to discern relative spatial relationships of objects. This is because they generate all possible masks on an image and evaluate each masked region for similarity to the given expression, often resulting in decreased sensitivity to direct positional clues in text inputs. Moreover, most methods have weak abilities to manage relationships between primary words and their contexts, causing confusion and reduced accuracy in identifying the correct target region. To address these challenges, we propose IteRPrimE (Iterative Grad-CAM Refinement and Primary word Emphasis), which leverages a saliency heatmap through Grad-CAM from a Vision-Language Pre-trained (VLP) model for image-text matching. An iterative Grad-CAM refinement strategy is introduced to progressively enhance the model's focus on the target region and overcome positional insensitivity, creating a self-correcting effect. Additionally, we design the Primary Word Emphasis module to help the model handle complex semantic relations, enhancing its ability to attend to the intended object. Extensive experiments conducted on the RefCOCO/+/g, and PhraseCut benchmarks demonstrate that IteRPrimE outperforms previous state-of-the-art zero-shot methods, particularly excelling in out-of-domain scenarios.
Detection of Small Targets in Sea Clutter Based on RepVGG and Continuous Wavelet Transform
Nov 14, 2023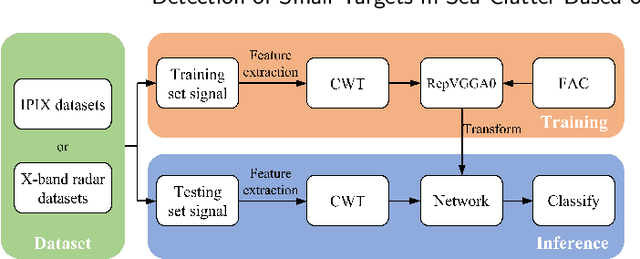
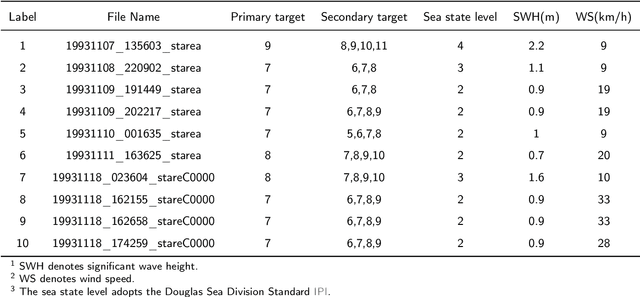
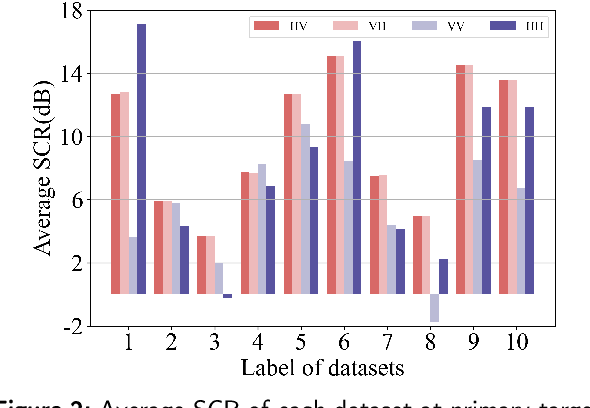
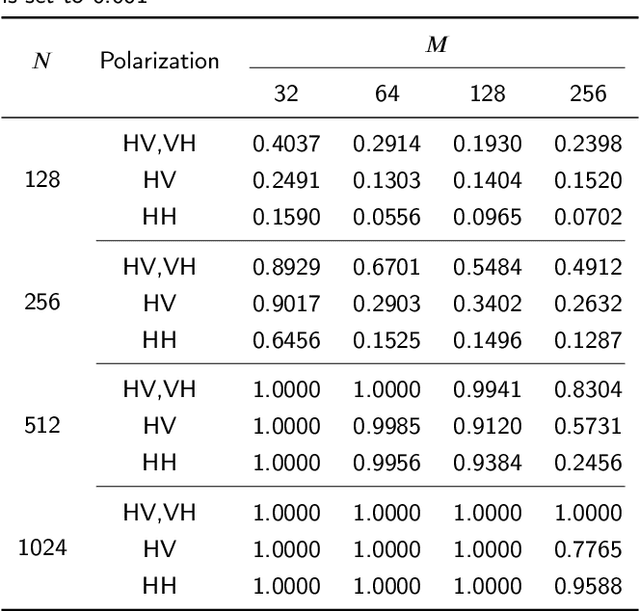
Constructing a high-performance target detector under the background of sea clutter is always necessary and important. In this work, we propose a RepVGGA0-CWT detector, where RepVGG is a residual network that gains a high detection accuracy. Different from traditional residual networks, RepVGG keeps an acceptable calculation speed. Giving consideration to both accuracy and speed, the RepVGGA0 is selected among all the variants of RepVGG. Also, continuous wavelet transform (CWT) is employed to extract the radar echoes' time-frequency feature effectively. In the tests, other networks (ResNet50, ResNet18 and AlexNet) and feature extraction methods (short-time Fourier transform (STFT), CWT) are combined to build detectors for comparison. The result of different datasets shows that the RepVGGA0-CWT detector performs better than those detectors in terms of low controllable false alarm rate, high training speed, high inference speed and low memory usage. This RepVGGA0-CWT detector is hardware-friendly and can be applied in real-time scenes for its high inference speed in detection.