 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Multi-armed Bandit with Local Search for MaxSAT
Nov 29, 2022Partial MaxSAT (PMS) and Weighted PMS (WPMS) are two practical generalizations of the MaxSAT problem. In this paper, we propose a local search algorithm for these problems, called BandHS, which applies two multi-armed bandits to guide the search directions when escaping local optima. One bandit is combined with all the soft clauses to help the algorithm select to satisfy appropriate soft clauses, and the other bandit with all the literals in hard clauses to help the algorithm select appropriate literals to satisfy the hard clauses. These two bandits can improve the algorithm's search ability in both feasible and infeasible solution spaces. We further propose an initialization method for (W)PMS that prioritizes both unit and binary clauses when producing the initial solutions. Extensive experiments demonstrate the excellent performance and generalization capability of our proposed methods, that greatly boost the state-of-the-art local search algorithm, SATLike3.0, and the state-of-the-art SAT-based incomplete solver, NuWLS-c.
Reinforced Lin-Kernighan-Helsgaun Algorithms for the Traveling Salesman Problems
Jul 15, 2022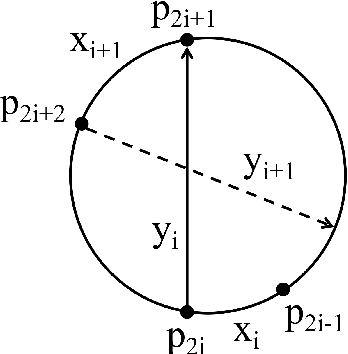
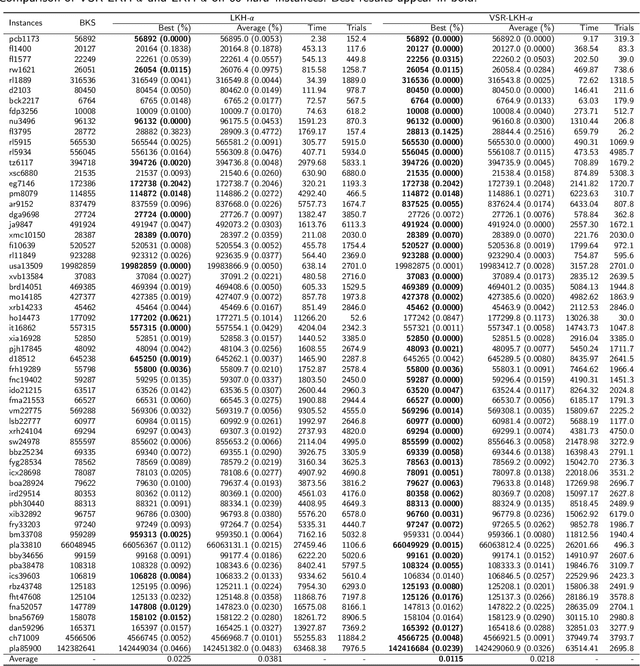

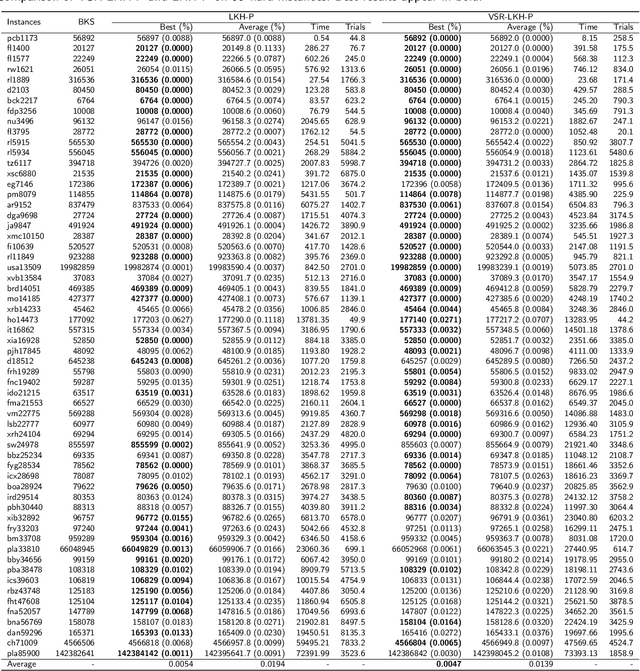
TSP is a classical NP-hard combinatorial optimization problem with many practical variants. LKH is one of the state-of-the-art local search algorithms for the TSP. LKH-3 is a powerful extension of LKH that can solve many TSP variants. Both LKH and LKH-3 associate a candidate set to each city to improve the efficiency, and have two different methods, $\alpha$-measure and POPMUSIC, to decide the candidate sets. In this work, we first propose a Variable Strategy Reinforced LKH (VSR-LKH) algorithm, which incorporates three reinforcement learning methods (Q-learning, Sarsa, Monte Carlo) with LKH, for the TSP. We further propose a new algorithm called VSR-LKH-3 that combines the variable strategy reinforcement learning method with LKH-3 for typical TSP variants, including the TSP with time windows (TSPTW) and Colored TSP (CTSP). The proposed algorithms replace the inflexible traversal operations in LKH and LKH-3 and let the algorithms learn to make a choice at each search step by reinforcement learning. Both LKH and LKH-3, with either $\alpha$-measure or POPMUSIC, can be significantly improved by our methods. Extensive experiments on 236 widely-used TSP benchmarks with up to 85,900 cities demonstrate the excellent performance of VSR-LKH. VSR-LKH-3 also significantly outperforms the state-of-the-art heuristics for TSPTW and CTSP.
BandMaxSAT: A Local Search MaxSAT Solver with Multi-armed Bandit
Jan 14, 2022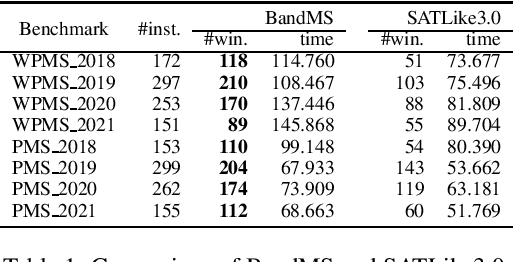
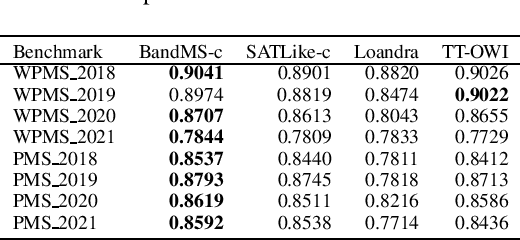
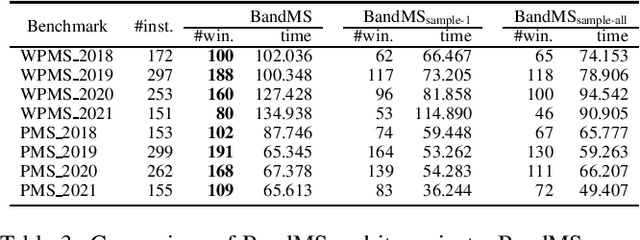

We address Partial MaxSAT (PMS) and Weighted PMS (WPMS), two practical generalizations of the MaxSAT problem, and propose a local search algorithm called BandMaxSAT, that applies a multi-armed bandit to guide the search direction, for these problems. The bandit in our method is associated with all the soft clauses in the input (W)PMS instance. Each arm corresponds to a soft clause. The bandit model can help BandMaxSAT to select a good direction to escape from local optima by selecting a soft clause to be satisfied in the current step, that is, selecting an arm to be pulled. We further propose an initialization method for (W)PMS that prioritizes both unit and binary clauses when producing the initial solutions. Extensive experiments demonstrate that BandMaxSAT significantly outperforms the state-of-the-art (W)PMS local search algorithm SATLike3.0. Specifically, the number of instances in which BandMaxSAT obtains better results is about twice that obtained by SATLike3.0. We further combine BandMaxSAT with the complete solver TT-Open-WBO-Inc. The resulting solver BandMaxSAT-c also outperforms some of the best state-of-the-art complete (W)PMS solvers, including SATLike-c, Loandra and TT-Open-WBO-Inc.
Farsighted Probabilistic Sampling based Local Search for (Weighted) Partial MaxSAT
Aug 23, 2021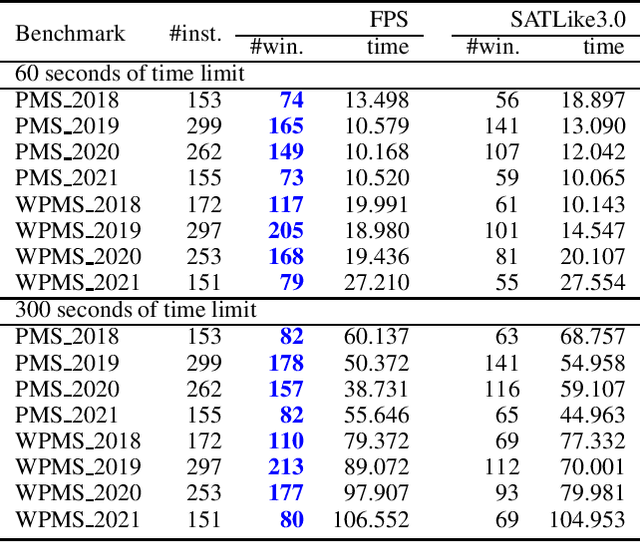
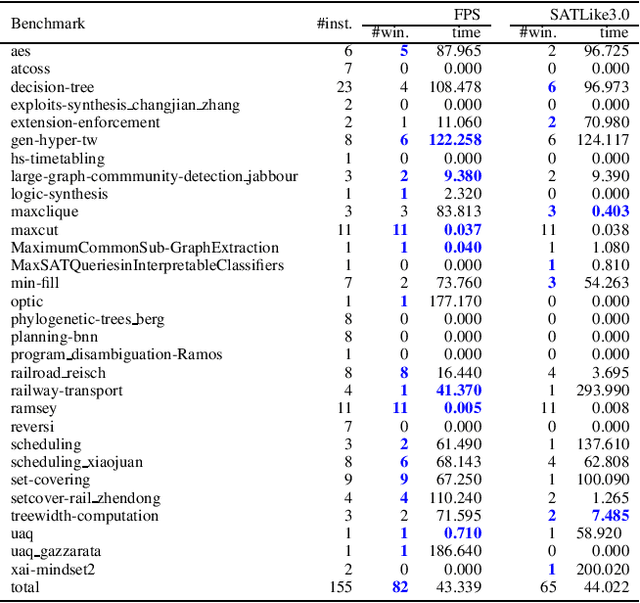
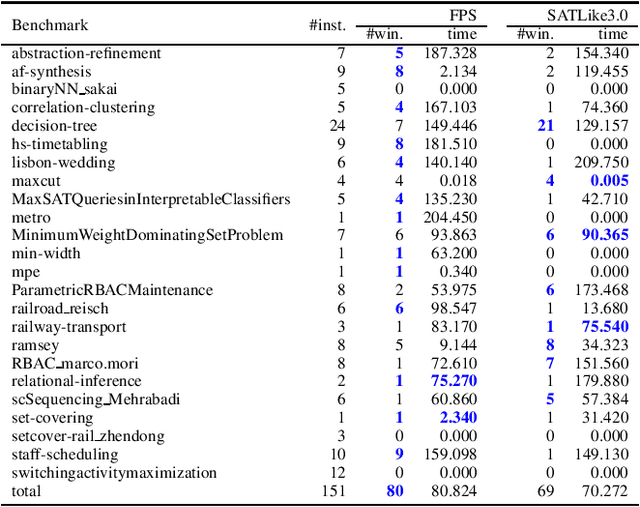
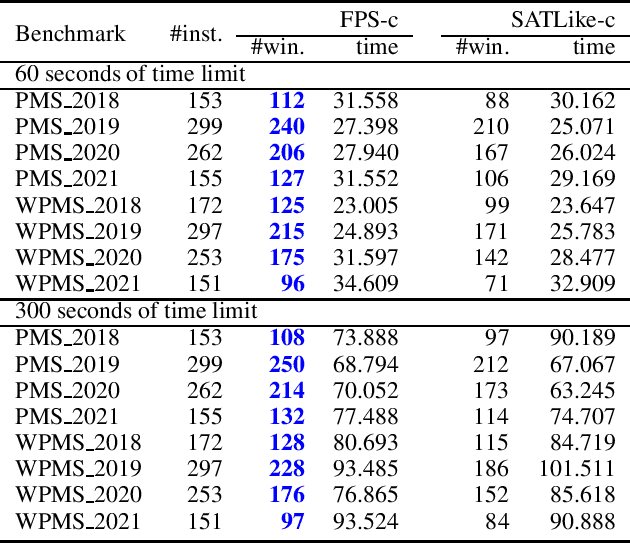
Partial MaxSAT (PMS) and Weighted Partial MaxSAT (WPMS) are both practical generalizations to the typical combinatorial problem of MaxSAT. In this work, we propose an effective farsighted probabilistic sampling based local search algorithm called FPS for solving these two problems, denoted as (W)PMS. The FPS algorithm replaces the mechanism of flipping a single variable per iteration step, that is widely used in existing (W)PMS local search algorithms, with the proposed farsighted local search strategy, and provides higher-quality local optimal solutions. The farsighted strategy employs the probabilistic sampling technique that allows the algorithm to look-ahead widely and efficiently. In this way, FPS can provide more and better search directions and improve the performance without reducing the efficiency. Extensive experiments on all the benchmarks of (W)PMS problems from the incomplete track of recent four years of MaxSAT Evaluations demonstrate that our method significantly outperforms SATLike3.0, the state-of-the-art local search algorithm, for solving both the PMS and WPMS problems. We furthermore do comparison with the extended solver of SATLike, SATLike-c, which is the champion of three categories among the total four (PMS and WPMS categories, each associated with two time limits) of the incomplete track in the recent MaxSAT Evaluation (MSE2021). We replace the local search component in SATLike-c with the proposed farsighted sampling local search approach, and the resulting solver FPS-c also outperforms SATLike-c for solving both the PMS and WPMS problems.
Combining Reinforcement Learning with Lin-Kernighan-Helsgaun Algorithm for the Traveling Salesman Problem
Dec 28, 2020
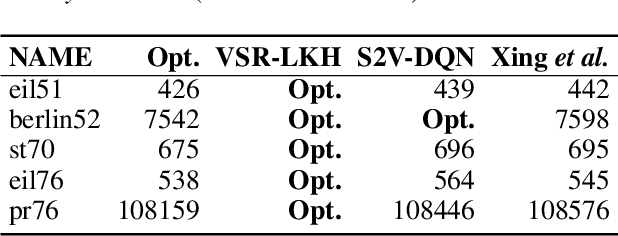
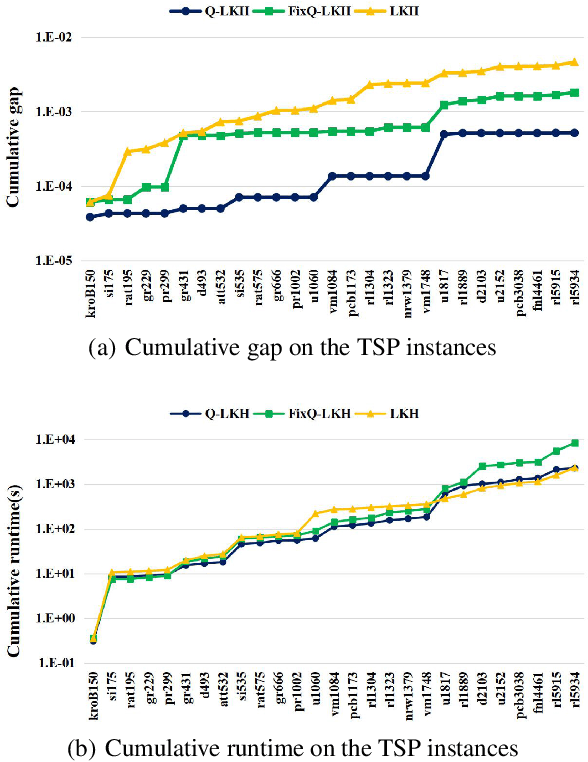
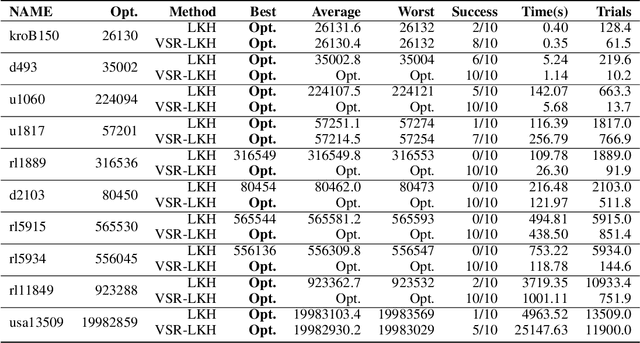
We address the Traveling Salesman Problem (TSP), a famous NP-hard combinatorial optimization problem. And we propose a variable strategy reinforced approach, denoted as VSR-LKH, which combines three reinforcement learning methods (Q-learning, Sarsa and Monte Carlo) with the well-known TSP algorithm, called Lin-Kernighan-Helsgaun (LKH). VSR-LKH replaces the inflexible traversal operation in LKH, and lets the program learn to make choice at each search step by reinforcement learning. Experimental results on 111 TSP benchmarks from the TSPLIB with up to 85,900 cities demonstrate the excellent performance of the proposed method.
Stochastic Item Descent Method for Large Scale Equal Circle Packing Problem
Jan 22, 2020



Stochastic gradient descent (SGD) is a powerful method for large-scale optimization problems in the area of machine learning, especially for a finite-sum formulation with numerous variables. In recent years, mini-batch SGD gains great success and has become a standard technique for training deep neural networks fed with big amount of data. Inspired by its success in deep learning, we apply the idea of SGD with batch selection of samples to a classic optimization problem in decision version. Given $n$ unit circles, the equal circle packing problem (ECPP) asks whether there exist a feasible packing that could put all the circles inside a circular container without overlapping. Specifically, we propose a stochastic item descent method (SIDM) for ECPP in large scale, which randomly divides the unit circles into batches and runs Broyden-Fletcher-Goldfarb-Shanno (BFGS) algorithm on the corresponding batch function iteratively to speedup the calculation. We also increase the batch size during the batch iterations to gain higher quality solution. Comparing to the current best packing algorithms, SIDM greatly speeds up the calculation of optimization process and guarantees the solution quality for large scale instances with up to 1500 circle items, while the baseline algorithms usually handle about 300 circle items. The results indicate the highly efficiency of SIDM for this classic optimization problem in large scale, and show potential for other large scale classic optimization problems in which gradient descent is used for optimization.